Do you think IIT Guwahati certified course can help you in your career?
Run length encoding (RLE) is an extremely simple compression technique. The aim is to replace successive repetitions of a particular symbol with a single copy of the symbol, plus a cout of how many times that symbol appears. For example - Original sequence: "AAAABBBCCDAA" Encoded sequence: "A4B3C2D1A2" Run-length encoding (RLE) is a compression technique that stores repeated sequences of data as a single value, along with a count of how many times it appears. This helps reduce file size without losing any information.
What is meant here is that string is a topic in Data Structures that everybody must read about, but few might know about this algorithm called Run length Encoding.
Let's start with this interesting topic and try to learn about it.
What is Run-Length Encoding?
Run-length encoding (RLE) is a very basic type of data compression in which an inputs stream of data (such as "PPPRRRSSSSSSS") is provided, and the output is a series of counts of successive data values in a row (i.e. "3P3R7S"). Since there is no loss in this type of data compression, the original data can be fully retrieved upon decompression. The algorithm's flexibility in both the encoding (compression) and decoding (decompression) processes is one of its most appealing qualities.
This type of data compression(Encoding) is lossless, meaning that all of the original data is recovered when decoded. One of the algorithm's most attractive aspects is its easiness in both encodings (compression) and decoding (decompression).
In this article, we will be covering the encoding of a string taken as user input. Let us move to the next section to understand with an example.
Example
Here's a simple example of a data stream ("run") in its original and encoded forms:
Input:
AAAAAABBBBBCCCCCCCCDDEEEEEFFF
Output:
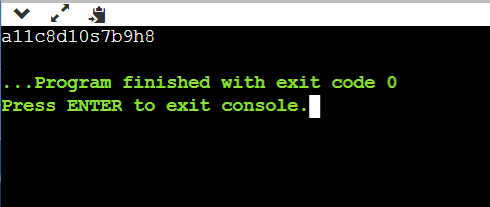
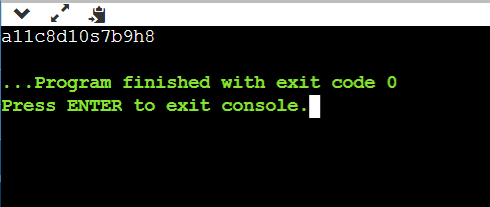
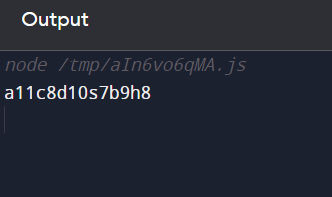
6A5B8C2D5E3F
In this example, we have the data given as input of 29 characters. The characters are then compressed into 12 characters which is a function of RLE.
History of run-length encoding
Run-Length Encoding (RLE) is one of the oldest and simplest forms of data compression techniques, dating back to the early days of computing. Its origins can be traced to the 1960s when computer systems were emerging and memory and storage were expensive resources. RLE operates on the principle of identifying consecutive occurrences of the same data value and replacing them with a single value and a count of how many times it repeats.
This compression method gained popularity due to its simplicity and effectiveness, especially for data with long runs of identical values, such as certain types of images, text, and graphics. While RLE may not always provide optimal compression for all types of data, its straightforward implementation and ability to quickly reduce file sizes have made it a widely used technique in various applications, including image and text compression, fax transmission, and early computer graphics. Despite advancements in compression algorithms, RLE remains a fundamental concept in the field of data compression and continues to be used in various forms in modern computing systems.
Run-length encoding and LZ77
Run-length encoding (RLE) and LZ77 are both classic compression techniques, albeit with different approaches and characteristics.
Run-Length Encoding (RLE): RLE is a simple and intuitive compression method that dates back to the early days of computing. It operates by replacing sequences of the same data value with a single value and a count of how many times it repeats. For example, a sequence like "AAAABBBCCDAA" could be encoded as "4A3B2C1D2A". RLE is particularly effective for data with long runs of identical values, such as certain types of images and text files. However, it may not be as efficient for data with irregular patterns or a wide range of values.
LZ77: LZ77, developed by Abraham Lempel and Jacob Ziv in 1977, is a dictionary-based compression algorithm. Unlike RLE, which focuses on repeating values, LZ77 identifies and replaces repeated sequences of data with references to previously encountered patterns. It uses a sliding window mechanism to maintain a buffer of recently processed data, enabling it to efficiently identify and encode repetitive sequences. LZ77 achieves compression by storing pointers to dictionary entries rather than repeating the actual data. This approach makes LZ77 highly effective for compressing various data types, including text, images, and multimedia files. It serves as a foundational component in many modern compression algorithms and formats.
Algorithm
Step 1: Choose the first character of the String that the user gives.
Step 2: Insert the selected character into the target string.
Step 3: Count the number of additional occurrences of the selected character and append the total to the target string. (One can also print the count of the string first and then select the character.)
Step 4: If the end of the String is not reached, select the next character and repeat steps 2, 3, and 4, respectively.
Step 5: Output string length will come the same.
Implementation in C++
C++ Code
C++ Code
#include <iostream> #include <string> using namespace std;
/* Perform Run–length encoding (RLE) data compression algorithm on string `str` */ string encodes(string s) { // Stores output string string encoding = ""; int counting=0; for (int n = 0; s[n]; n++) { // Count occurrences of character at index `i' counting = 1; while (s[n] == s[n + 1]) { counting++, n++; }
// Add(append) the current character and its count to the outcome encoding += to_string(counting) + s[n]; } return encoding; }
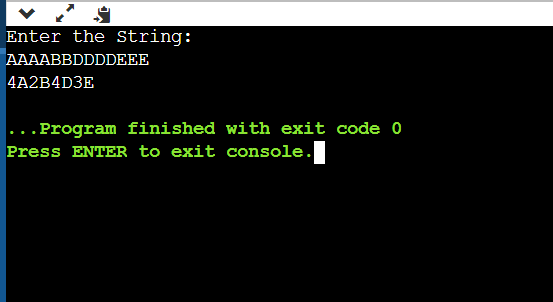
int main() { string s ; cout<<"Enter the String:"<<endl; getline(cin,s); cout << encodes(s); return 0; }
You can also try this code with Online C++ Compiler
import java.util.*; class Main { /* Perform Run–length encoding (RLE) data compression algorithm on string `str` */ public static String encode(String s) { // Stores output string String encoded = "";
// Base case if (s == null) { return encoded; }
int count; for (int i = 0; i < s.length(); i++) { // Count occurrences of character at index `i' count = 1; while (i + 1 < s.length() && s.charAt(i) == s.charAt(i + 1)) { count++; i++; }
// Append current character and its count to the result encoded += String.valueOf(count) + s.charAt(i); } return encoded; }
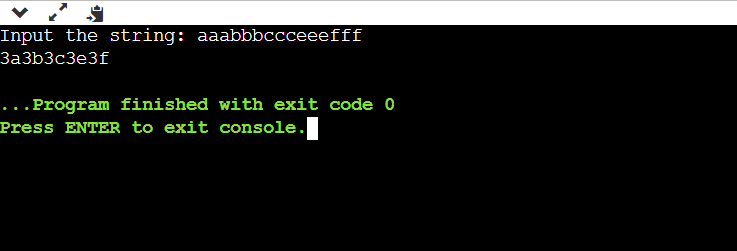
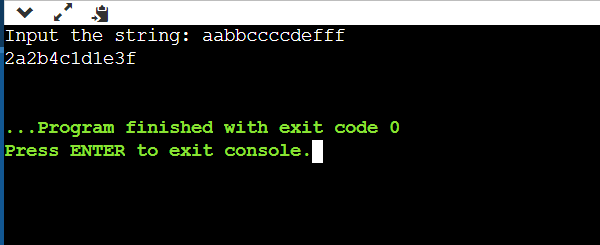
public static void main(String[] args) { // 'System.in' is a standard input stream Scanner sc= new Scanner(System.in); System.out.print("Input the string: "); String s = sc.nextLine(); System.out.print(encode(s)); } }
You can also try this code with Online Java Compiler
using System; class CodingNinjas { public static void encode(string s){ int length = s.Length; for (int i = 0; i < length; i++) { Console.Write(s[i]); int count = 1; while (i < length - 1 && s[i] == s[i + 1]) { count++; i++; }
The time complexity of run length encoding isO(n^2).
Explanation: There are two iterations going on. First is from i =0 to string length and another is nested to the first loop from i=i+1 to the length of the string.
Space Complexity
The space complexity of run length encoding is O(1).
Explanation: No extra space is getting utilized.
Drawbacks of run-length encoding
Run-Length Encoding (RLE) has several drawbacks, which limit its applicability in certain scenarios:
Inefficiency with Random Data: RLE works well with data that contains long runs of identical values. However, it performs poorly with random or highly varied data where runs of identical values are infrequent. In such cases, RLE may actually increase the size of the data due to the overhead of storing count values.
Limited Compression Ratio: While RLE can effectively compress certain types of data, it typically achieves modest compression ratios compared to more advanced compression algorithms. This limitation means that RLE may not be suitable for applications where significant compression is required.
Not Suitable for Lossy Compression: RLE is a lossless compression technique, meaning that it preserves all the original data when decompressed. However, it is not suitable for lossy compression scenarios where some loss of data fidelity is acceptable in exchange for higher compression ratios.
Encoding Overhead: RLE encoding requires additional metadata to represent the counts of repeated values. This overhead can increase the size of the compressed data, particularly for short runs of repeated values.
Limited Applicability: RLE is most effective for specific types of data, such as binary images, simple graphics, and text documents with repeated characters. It may not be well-suited for compressing complex data structures or multimedia files with diverse patterns and information.
The data sequence is saved as a single value and count. For example, a minute of a beach scene would have similar colors on the screen for the duration of the shot, such as blues from the sky and sea and yellows from the sand.
What is meant by run length encoding?
Run Length Encoding (RLE) is a technique for compressing data with long repeated-value runs. The RLE code reads an input string and outputs a compressed string with the counts of consecutive characters.
Why is Run Length Encoding used?
Run Length Encoding (RLE) is used as a technique for compressing data with long repeated-value runs. For example, consider an image with little change or a collection of smooth, fluid data. Compressing the image with this technique will significantly reduce data size, making storing, transmitting, and processing simpler.
What is run-length encoding vs dictionary encoding?
Run-length encoding is a special lossless technique that is used to compress data with long runs. All of the original data is recovered when decoded. Dictionary encoding is also a lossless technique that is used to find patterns in the data.
What is run length and Huffman encoding?
Run-Length Encoding (RLE) is a data compression technique that replaces sequences of the same data value with a single value and a count of how many times it repeats, reducing redundancy. Huffman Encoding is a variable-length prefix coding technique used for lossless data compression. It assigns shorter codes to more frequent symbols, optimizing the encoding process for efficient compression.
What is the run length of a string?
The run length of a string refers to the number of consecutive occurrences of the same character or sequence within the string, often used in data compression algorithms like Run-Length Encoding to reduce redundancy and compress data effectively.
Conclusion
In this blog, we have learned about Run Length Encoding. The articles contain the proper definition of algorithms with pictorial representation and programming.
If you found this blog has helped you enhance your knowledge, and if you want to learn more algorithms like the run length encoding algorithm, check out our articles below:































 9+ registered
9+ registered 

