Do you think IIT Guwahati certified course can help you in your career?
Introduction
Object recognition is a computer vision technology to identify objects in images and videos. Humans are nearly perfect in object recognition. We can easily recognize objects regardless of what angle we are looking at them. It doesn’t matter what their size or the scenery behind them is. Computers, however, struggle to do the same. It is very challenging for a computer to recognize an object if we change its features like angle or scale. This article will discuss an interesting technique known as scale-invariant feature transform (SIFT) that helps overcome this problem.
What is Scale-Invariant Feature Transform (SIFT)?
SIFT is an algorithm that detects and matches the features of an image. The main idea behind SIFT is to extract key points (features) from a set of reference images and store them in a database. To identify an object in a new image, we compare the features of the new image from the database.
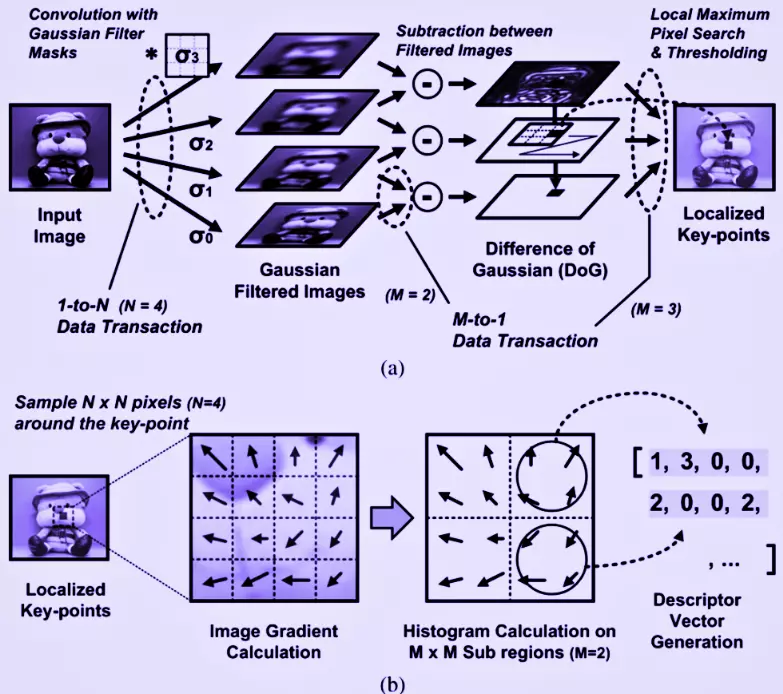
Four steps of Scale-Invariant Feature Transform (SIFT)
Scale-space extrema selection: It is the first step of SIFT algorithm. The potential interest points are located using difference-of-gaussian.
Keypoint localization: A model is fit to determine the location and scale at each potential location. Keypoints are selected based on their stability.
Orientation assignment: orientations are assigned to keypoints locations based on local image gradient direction.
Keypoint descriptor: It is the final step of SIFT algorithm. A coordinate system around the feature point is created that remains the same for the different views of the feature.
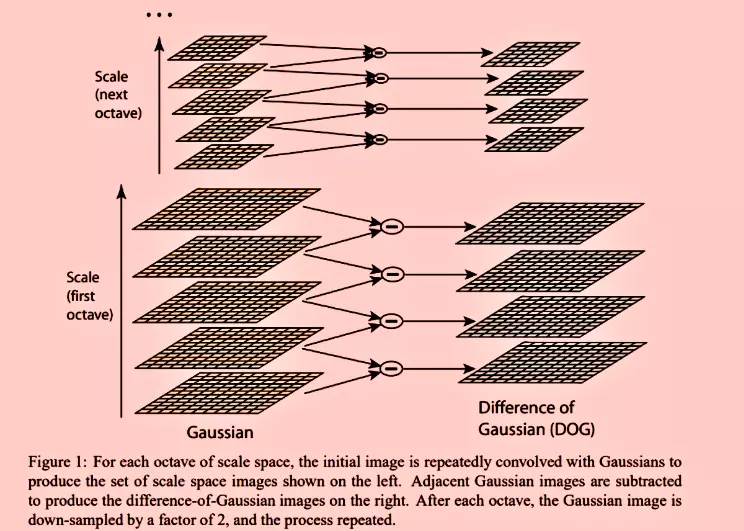
Scale-space extrema selection
Constructing the scaled space:
We first identify the candidate locations for the key points that are processed and examined in the succeeding steps. Detecting locations invariant to scale change can be done by searching the features that remain the same at different scales.
The scale-space of an image is defined as a function, L(x, y, σ), formed by performing a convolution operation of a variable-scale gaussian function, G(x, y, σ), on an input image, I(x, y). The variable-scale gaussian function is defined by:
And the scale space is defined by:
Where * is the convolution operation on x and y.
To detect the stable keypoint in scale space, we use the difference of gaussian, which is defined as:
Finding keypoints:
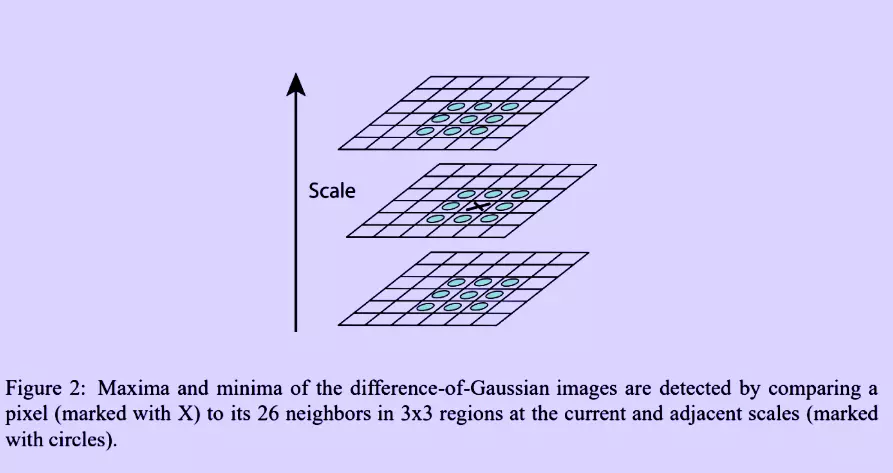
After calculating the Difference of Gaussians, we calculate the Laplacian of Gaussian approximations that are scale-invariant. Each pixel is compared with its eight neighboring pixels and 9 pixels in the following scale and 9 pixels in the previous scale. It is selected if it is larger or smaller than all these neighbors. If it’s a local extremum, it is potentially a key point.
Keypoint Localization
We get a lot of key points from the previous steps. Some of the key points are on the edges, and some of the key points have low contrast. These features are not as much important.
To remove the low contrast features, we check the intensities of each feature and remove the features that have intensities lower than the threshold value.
Orientation Assignment
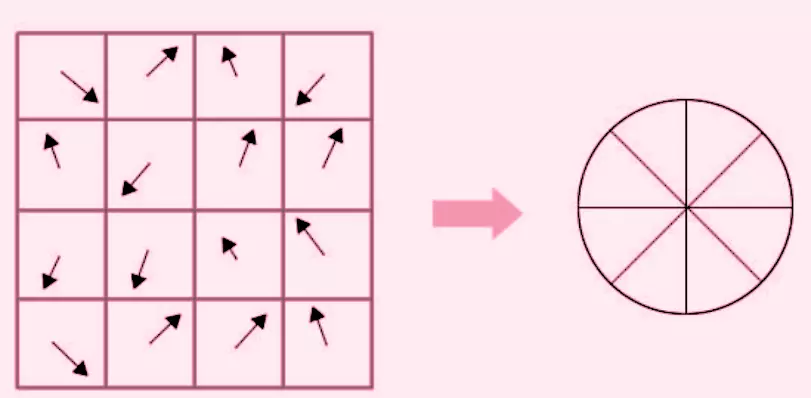
After getting useful key points, we assign an orientation to each key point to make it orientation invariance. We use histogram of oriented gradient to achieve this.
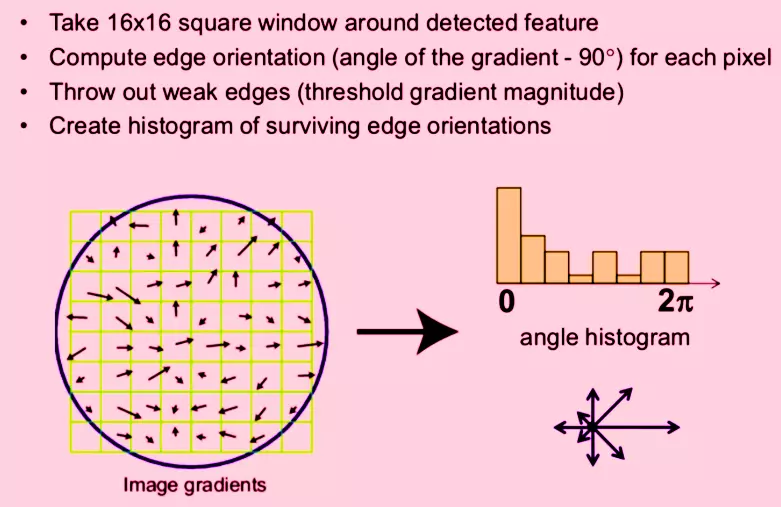
Keypoint Descriptor
It is the final step of SIFT algorithm. After getting key points that are described according to their location, scale, and orientation, we create a coordinate system around the feature point that remains the same from the different views of the feature.
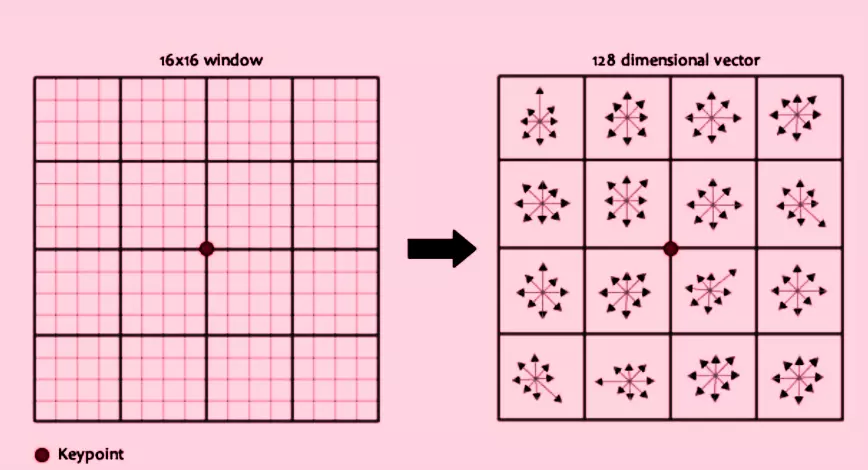
To do this, we take a 16X16 window around the key point. The window is divided into sixteen 4X4 blocks.
For each 4X4 window, an 8 bin orientation histogram is created.
After we get the keypoint descriptor, the key points between the two images are matched by identifying their neighboring key points from the database of key points that we get from training.
Scale Invariance: SIFT (Scale-Invariant Feature Transform) effectively detects and describes image features at different scales.
Robustness: Performs well under varying lighting conditions, rotations, and partial occlusions.
Distinctiveness: Generates highly distinctive features that enable accurate matching across different images.
Large Number of Features: Identifies a large number of key points, enhancing the reliability of image matching.
Efficient Matching: Facilitates efficient matching and recognition in large datasets due to its detailed feature descriptors.
Wide Applicability: Used extensively in applications like image stitching, object recognition, and 3D modeling due to its versatility.
Frequently Asked Questions
How can SIFT be implemented in our code?
We can use OpenCV to implement SIFT.
Are there any other algorithms like SIFT?
Yes, there are other algorithms like SIFT. For example, SURF.
Which is better, SIFT or SURF?
SURF is more accurate than SIFT.
What are the Steps of SIFT Features?
The steps of SIFT features include:
Scale-space Extrema Detection: Identify key points at different scales.
Keypoint Localization: Refine the location and scale of key points.
Orientation Assignment: Assign orientations to key points.
Keypoint Descriptor: Generate descriptors for key points.
Conclusion
In this article, we talked about the SIFT algorithm. We talked about its need and the overall process of how it is carried out. You can add your own image and get its key points. You can read the original paper here. To learn more about similar topics, check out our machine learning course at coding ninjas.
































 8+ registered
8+ registered 

