Do you think IIT Guwahati certified course can help you in your career?
Introduction
Pattern matching is always an important topic from an interview perspective. Thus it's important to master all the ways in which pattern matching is done. Today we will see how we can do pattern matching using a suffix tree. Now, Let's understand the problem statement.
Understanding the Problem
We have been given two strings ‘TXT’ and ‘PATTERN’ and our task is to find all the occurrences of the ‘PATTERN’ string in ‘TXT’.
Let's understand this by the following example.
Example
Input
‘TXT’ = ‘codeandcode’
‘PATTERN’ = ‘code’
Output
2
Explanation
We can see that the ‘PATTERN’ ‘code’ is present 2 times in the ‘TXT’ string starting from 0th and 7th index.
Intuition
The intuition is very similar to the problem we solved earlier i.e., Substring Check using Suffix tree. We will first create the suffix tree using Ukkonen’s Algorithm which is a linear time-taking algorithm. After that, we will do the following steps.
First and foremost, we will check whether the given ‘PATTERN’ is present in ‘TXT’ or not similar to what we did in Subtring Check. To do so, go through the suffix tree and compare it to the ‘PATTERN’.
If we see that there exists a pattern in the suffix tree (don't fall off now), go down the subtree and look for all suffix indices on leaf nodes. In string, all of the suffix indices will be pattern indices.
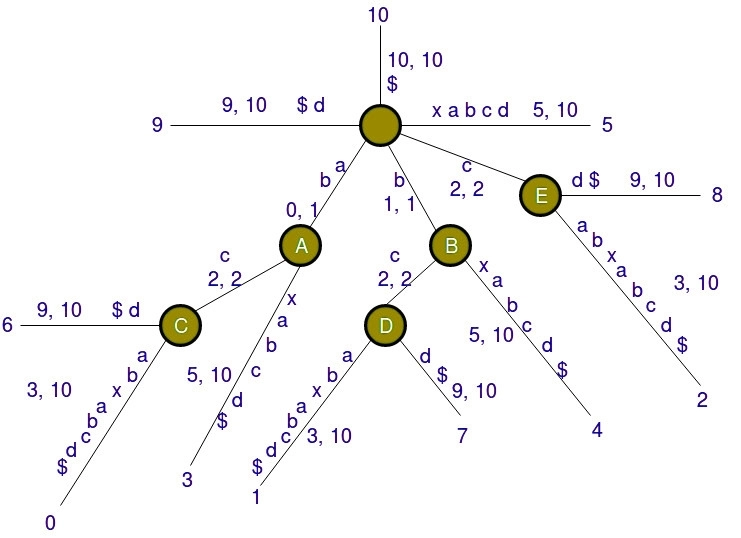
This suffix tree for String "abcabxabcd$" displays suffix indices as well as edge label indices (start, end). The substring value on the edges is solely shown for demonstration purposes. The path label string is never stored in the tree.
A path's Suffix Index indicates the position of a substring (beginning at the root) on that path.
Consider the path "bcd$" in the above tree, which has a suffix index of 7. It indicates that the substrings b, bc, bcd, and bcd$ are located at index 7 in the string.
We should be able to view the following using the preceding explanation:
At indices 0, 3, and 6, the substring "ab" appears.
At indices 0 and 6, the substring "abc" is found.
.
.
Things will become more clear from the following code.
Code
#include <bits/stdc++.h>
using namespace std;
#define MAX_CHAR 256
struct SuffixTreeNode {
struct SuffixTreeNode *children[MAX_CHAR];
struct SuffixTreeNode *suffixLink;
int start;
int *end;
/* This is used to store index of suffix for the path from root to leaf node*/
int suffixIndex;
};
typedef struct SuffixTreeNode Node;
string text; //Input string
Node *root = NULL; //Pointer to root node
Node *lastNewNode = NULL;
Node *activeNode = NULL;
int activeEdge = -1;
int activeLength = 0;
/* This tells how many suffixed need to be added */
int remainingSuffixCount = 0;
int leafEnd = -1;
int *rootEnd = NULL;
int *splitEnd = NULL;
int size = -1; //Length of input string
Node *newNode(int start, int *end)
{
Node *node =(Node*) malloc(sizeof(Node));
int i;
for (i = 0; i < MAX_CHAR; i++)
node->children[i] = NULL;
/* If its a root node then suffixLink will be set to NULL */
node->suffixLink = root;
node->start = start;
node->end = end;
node->suffixIndex = -1;
return node;
}
int edgeLength(Node *n) {
if(n == root)
return 0;
return *(n->end) - (n->start) + 1;
}
int walkDown(Node *currNode)
{
/* Now next internal node will be set to activeNode if its greater than current edgeLength*/
if (activeLength >= edgeLength(currNode))
{
activeEdge += edgeLength(currNode);
activeLength -= edgeLength(currNode);
activeNode = currNode;
return 1;
}
return 0;
}
void extendSuffixTree(int pos)
{
/* Used for extension of the leaves created */
leafEnd = pos;
/* This signifies that we need to add one more node */
remainingSuffixCount++;
/* This means that there is no new node to be added */
lastNewNode = NULL;
/* Adding all the suffixes */
while(remainingSuffixCount > 0) {
if (activeLength == 0)
activeEdge = pos;
if (activeNode->children == NULL)
{
//Extension Rule 2 (A new leaf edge gets created)
activeNode->children =
newNode(pos, &leafEnd);
if (lastNewNode != NULL)
{
lastNewNode->suffixLink = activeNode;
lastNewNode = NULL;
}
}
else
{
Node *next = activeNode->children;
if (walkDown(next))//Do walkdown
{
continue;
}
/*Extension Rule 3 (current character being processed
is already on the edge)*/
if (text[next->start + activeLength] == text[pos])
{
if(lastNewNode != NULL && activeNode != root)
{
lastNewNode->suffixLink = activeNode;
lastNewNode = NULL;
}
activeLength++;
/*STOP all further processing in this phase
and move on to next phase*/
break;
}
splitEnd = (int*) malloc(sizeof(int));
*splitEnd = next->start + activeLength - 1;
/ *New internal node */
Node *split = newNode(next->start, splitEnd);
activeNode->children] = split;
split->children] = newNode(pos, &leafEnd);
next->start += activeLength;
split->children] = next;
if (lastNewNode != NULL)
{
lastNewNode->suffixLink = split;
}
lastNewNode = split;
}
remainingSuffixCount--;
if (activeNode == root && activeLength > 0)
{
activeLength--;
activeEdge = pos - remainingSuffixCount + 1;
}
else if (activeNode != root)
{
activeNode = activeNode->suffixLink;
}
}
}
void print(int i, int j)
{
int k;
for (k=i; k<=j; k++)
printf("%c", text[k]);
}
/* This will print the tree in DFS manner */
void setSuffixIndexByDFS(Node *nnode, int labelHeight)
{
if (nnode == NULL) return;
int leaf = 1;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (nnode->children[i] != NULL)
{
/* Not a leaf Node */
leaf = 0;
setSuffixIndexByDFS(nnode->children[i], labelHeight +
edgeLength(nnode->children[i]));
}
}
if (leaf == 1)
{
nnode->suffixIndex = size - labelHeight;
}
}
void freeSuffixTreeByPostOrder(Node *nnode)
{
if (nnode == NULL)
return;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (nnode->children[i] != NULL)
{
freeSuffixTreeByPostOrder(nnode->children[i]);
}
}
if (nnode->suffixIndex == -1)
free(nnode->end);
free(nnode);
}
/* This will build the tree and will also print the edge labels */
void buildSuffixTree()
{
size = text.length();
int i;
rootEnd = (int*) malloc(sizeof(int));
*rootEnd = - 1;
root = newNode(-1, rootEnd);
/* First active node has to be a root node */
activeNode = root;
for (i=0; i<size; i++)
extendSuffixTree(i);
int labelHeight = 0;
setSuffixIndexByDFS(root, labelHeight);
}
int traverseEdge(string str, int idx, int start, int end)
{
int k = 0;
/* Character by character traversal */
for(k=start; k<=end && str[idx] != '\0'; k++, idx++)
{
if(text[k] != str[idx])
return -1;
}
/* If matched */
if(str[idx] == '\0')
return 1;
return 0;
}
int doTraversalToCountLeaf(Node *nnode)
{
if(nnode == NULL)
return 0;
if(nnode->suffixIndex > -1)
{
cout<<"Found at position"<<" "<< nnode->suffixIndex;
return 1;
}
int count = 0;
int i = 0;
for (i = 0; i < MAX_CHAR; i++)
{
if(nnode->children[i] != NULL)
{
count += doTraversalToCountLeaf(nnode->children[i]);
}
}
return count;
}
int countLeaf(Node *nnode)
{
if(nnode == NULL)
return 0;
return doTraversalToCountLeaf(nnode);
}
int doTraversal(Node *nnode, string str, int idx)
{
if(nnode == NULL)
{
return -1; // no match
}
int res = -1;
/* If node n is not root node, then traverse edge from node n's parent to node n.*/
if(nnode->start != -1)
{
res = traverseEdge(str, idx, nnode->start, *(nnode->end));
if(res == -1) //no match
return -1;
if(res == 1) //match
{
if(nnode->suffixIndex > -1)
cout<<"Substring count :1 and position"<<nnode->suffixIndex;
else
cout<<"Substring count"<< " "<<countLeaf(nnode);
return 1;
}
}
idx = idx + edgeLength(nnode);
/* We will check if there is any edge from nnode going out */
if(nnode->children[str[idx]] != NULL)
return doTraversal(nnode->children[str[idx]], str, idx);
else
return -1;
}
void checkForSubString(string str)
{
int res = doTraversal(root, str, 0);
if(res != 1)
cout<<"Pattern is not a Substring"<<str;
else
cout<<"Pattern is a Substring"<<str;
}
int main()
{
string pattern;
cin>>text>>pattern;
buildSuffixTree();
checkForSubString(pattern);
/* Free the dynamically allocated memory */
freeSuffixTreeByPostOrder(root);
return 0;
}
You can also try this code with Online C++ Compiler
O(M + N), where ‘N’ is the length of ‘TXT’ and ‘M’ is the length of ‘PATTERN’,
Reason: Construction of the Ukkonen’s Suffix Tree costs us O(N) time and after that, traversal for substring check takes O(M) and then if there are Z occurrences of the pattern, it will take O(Z) to find indices of all those Z occurrences. Thus the overall time complexity is O(M) + O(N) + O(Z) ~ O(M + N + Z)~ O(M + N)
Space Complexity
O(N), where ‘N’ is the length of ‘TXT’
Reason: This is the space used to build the suffix tree.
What is a suffix tree? The Suffix Tree is a compressed trie that stores all of a string's suffixes. Suffix tree has been shown to be quite useful in string-related tasks such as detecting different substrings in a string, pattern matching, and determining the largest palindrome, among others.
What advantages does Suffix Tree have over Tries?? Suffix Trees take up less space, and the difference between linear and quadratic space complexity might be significant when storing a large text. The use of a suffix tree can help speed up lookups.
What are the uses of a Suffix Tree? While this data structure has various uses, the most typical ones are scanning a string in a Text in O(len(string)) time for multiple checks, looking for the longest repeated string, largest common substring, and so on. It can also be used to look for patterns in DNA or protein sequences.
What are the ways to improve the suffix tree formation? Instead of using the brute force method, we can use Ukkonen's Technique which is an upgrade to the brute force algorithm (it can create a suffix tree in O(M) time, which is the best we can anticipate).
Are there any other Data Structures and Algorithms content in Coding Ninjas Studio? Yes, Coding Ninjas Studio allows you to practice coding as well as answer frequently asked interview questions. The more we practice, the more likely we are to acquire a job at our dream company.
Conclusion
We saw how we solved the problem ‘Searching All Patterns Using Suffix Tree', which was based on the concept of Suffix Tree. Some other problems that revolve around the suffix tree concepts areSubstring Check, All occurrences of patterns. Now don't waste any more time and head over to our practice platform Coding Ninjas Studio to practice top problems on every topic, interview experiences, and many more. Till then, Happy Coding































 9+ registered
9+ registered 

