Do you think IIT Guwahati certified course can help you in your career?
Introduction
In the world of data structures and algorithms, searching plays a pivotal role in retrieving data efficiently. Whether it’s locating a specific item in a database, finding a path in a maze, or processing complex datasets, effective searching algorithms make a significant impact. Searching algorithms help determine the presence or absence of elements in various data structures, such as arrays, trees, or graphs, optimizing performance and response times.
In this blog, we will explore fundamental and advanced searching algorithms like linear search, binary search, depth-first search, etc.
What is Searching in Data Structure?
Searching in data structures refers to the process of finding a specific element or a set of elements within a data structure. The objective is to determine whether the desired element is present in the data structure and, if so, locate its position. This is a fundamental operation in computer science, as it allows for efficient data retrieval, which is crucial for performing a wide range of computing tasks.
Different data structures support various searching techniques that can be optimized based on the characteristics of the data. For example, searching in an array might involve scanning each element sequentially until the desired value is found. This method is straightforward but can be time-consuming if the array is large. In contrast, more complex data structures like binary search trees allow for faster searching operations, which can significantly reduce the time it takes to find an element by following a path from the root to the leaf, eliminating half of the search space with each step.
The efficiency of a search method in a data structure is measured by how quickly it can locate an element or confirm its absence. This efficiency is crucial because it can greatly affect the overall performance of software applications, especially those that handle large amounts of data. The choice of search method and data structure often depends on the specific requirements of the application, including the type of data, the frequency of searches, and the need for other data operations like insertion and deletion.
Searching Algorithms in Data Structures
In data structures, searching algorithms are essential for efficiently locating elements within various data collections, such as arrays, trees, or graphs. They help streamline data retrieval by minimizing the time and effort needed to find specific information.
Several searching methods are employed in data structures, each suited for specific types of data and usage scenarios. Here are some commonly used searching methods:
Linear Search: This is the simplest form of searching, where each element of the data structure is checked sequentially until the target element is found or the list is fully traversed. It is easy to implement and works well with small datasets.
Binary Search: Binary search is much faster than linear search but requires the data to be sorted beforehand. It operates by repeatedly dividing the search interval in half. If the value of the target is less than the value in the middle of the interval, the search continues in the lower half, or else it continues in the upper half.
Jump Search: Jump search improves upon linear search by jumping ahead by a fixed number of elements instead of going one by one. However, it requires the array to be sorted. This method is useful when there is a balance to be maintained between linear and binary search.
Interpolation Search: A variation of binary search, interpolation search calculates an estimate of where the target value could be based on the lowest and highest values in the array. This method works best for uniformly distributed data.
Exponential Search: Exponential search is useful when the array is unbounded or when the size of the array is unknown. It first determines the range where the element could exist by growing exponentially, and then a binary search is applied within this range.
Fibonacci Search: A method that utilizes Fibonacci numbers to divide the array into sections. It is primarily used when the data structure prohibits direct access to elements, such as in distributed data systems.
Hashing: Hashing is a technique used to map data to a fixed-size array using a hash function. It allows for efficient data retrieval, as the average time complexity for insertion, deletion, and searching is O(1). Hash tables are widely used in databases, caches, and sets to provide fast lookups.
Tree-based Searching: Tree-based searching uses hierarchical structures like binary search trees (BSTs) or AVL trees to organize data. These structures allow efficient searching with an average time complexity of O(log n). Tree-based search algorithms work by recursively traversing the tree, comparing values at each node.
Ternary Search: Ternary search is a divide-and-conquer algorithm that splits the search range into three parts rather than two, as in binary search. It is used for finding the maximum or minimum value in unimodal functions. The time complexity is O(log3 n), which is slower than binary search but can be useful in specific scenarios.
Hash-based Searching (e.g., Bloom Filter): Hash-based searching involves using hash functions to index and search for elements in a set. Bloom Filters are a space-efficient probabilistic data structure that uses multiple hash functions to check membership. While it provides fast membership testing with a small memory footprint, it may yield false positives.
String Searching Algorithms: String searching algorithms are used to find substrings within a string, such as the Knuth-Morris-Pratt (KMP) or Boyer-Moore algorithms. These algorithms reduce the number of character comparisons by preprocessing the pattern and skipping irrelevant parts of the text, achieving efficient string matching in O(n) or O(m+n) time.
What is Linear Search?
Linear search, also known as sequential search, is one of the simplest searching methods used in programming. It is a method where each element of a list or array is checked sequentially, starting from the first element, until the desired element is found or the list ends. This method does not require the list to be sorted, making it versatile for searching through unsorted data.
Here’s how linear search works
Start at the first element of the list.
Compare the current element with the target value.
If the current element matches the target value, return the index of this element.
If the current element does not match, move to the next element.
Repeat steps 2 through 4 until the element is found or the list ends.
If the list ends without finding the target, indicate that the search was unsuccessful.
Linear search is straightforward to implement and understand, making it an excellent choice for small datasets or lists where elements are added and removed frequently, as it does not require maintaining any order. However, its efficiency decreases as the size of the dataset increases, since the average number of comparisons needed grows linearly with the number of elements. This can be a significant drawback when dealing with large volumes of data.
Implementation:
Python
Python
def linear_search(arr, target): """ This function performs a linear search on an array.
:param arr: List of elements where the search will be performed. :param target: The element to be searched within the list. :return: The index of the target if found, otherwise -1. """ for index, element in enumerate(arr): if element == target: return index # Return the index of the target element if found return -1 # Return -1 if the target is not found in the list
# Example usage: if __name__ == "__main__": data = [5, 3, 8, 6, 7, 2] target = 6 result = linear_search(data, target)
if result != -1: print(f"Element found at index: {result}") else: print("Element not found in the list.")
You can also try this code with Online Python Compiler
Binary search is a more efficient searching technique compared to linear search, especially for larger datasets. It operates on the principle of divide and conquer and requires that the dataset be sorted before the search begins. The primary advantage of binary search is its speed in finding an element, as it significantly reduces the number of comparisons needed to locate an item.
Here’s how binary search works
Here’s the step-by-step process of how binary search works:
Start in the Middle: Begin by examining the middle element of the array.
Compare Values: Check if the middle element is equal to the target value. If it matches, the search is complete, and the index of the middle element is returned.
Divide the Array: If the target value is less than the middle element, the search continues in the left half of the array. If the target is greater, the search shifts to the right half.
Repeat the Process: This process of dividing the array and checking the middle element is repeated on the new half-array. Each step cuts the search area by half.
Conclude the Search: The search continues until the target is found or until the subarray size becomes zero (which means the target is not in the array).
Binary search drastically improves search efficiency, reducing the complexity from O(n) in linear search to O(log n) in binary search. This means that even for large arrays, the number of steps required to find an element grows logarithmically with the size of the array.
This method is particularly useful in scenarios where frequent searches are performed over sorted datasets, such as in database lookup operations or during high-volume data processing, where performance is critical.
Implementation:
Python
Python
def binary_search(arr, target): """ This function performs a binary search on a sorted array.
:param arr: A sorted list of elements where the search will be performed. :param target: The element to be searched in the list. :return: The index of the target if found, otherwise -1. """ left, right = 0, len(arr) - 1 while left <= right: mid = (left + right) // 2 if arr[mid] == target: return mid # Return the index of the target element if found elif arr[mid] < target: left = mid + 1 # Move the left boundary to narrow the search else: right = mid - 1 # Move the right boundary to narrow the search return -1 # Return -1 if the target is not found in the list
# Example usage: if __name__ == "__main__": data = [1, 2, 4, 5, 7, 8, 12, 14, 23] target = 7 result = binary_search(data, target)
if result != -1: print(f"Element found at index: {result}") else: print("Element not found in the list.")
You can also try this code with Online Python Compiler
Interpolation search is an advanced searching technique that works on principles similar to those used in binary search but with a key difference—it estimates the position of the target based on the values of the boundaries and the target itself, assuming that the values are stored in a uniformly or near-uniformly distributed manner. This method can be particularly efficient if the elements are not only sorted but also uniformly distributed.
Here’s how Interpolation search works
Here’s how interpolation search works in steps:
Estimate the Position: The search estimates where the target value could be located within the array based on linear interpolation. The formula used is:
where pos is the estimated position, x is the target value, arr is the array, low and high are the current boundaries of the array segment being searched.
Verify and Adjust: Once an estimated position is calculated, the algorithm checks the element at that position:
If the element at pos matches the target, the search is complete.
If the target is larger, the algorithm adjusts the lower boundary (low) to pos + 1.
If the target is smaller, it adjusts the upper boundary (high) to pos - 1.
Repeat or Complete: These steps are repeated until the target is found or the subarray bounds are invalid (i.e., when low exceeds high), indicating that the target is not in the array.
Implementation:
Python
Python
def interpolation_search(arr, target): """ This function performs an interpolation search on a sorted array.
:param arr: A sorted list of elements where the search will be performed. :param target: The element to be searched in the list. :return: The index of the target if found, otherwise -1. """ low, high = 0, len(arr) - 1
while low <= high and target >= arr[low] and target <= arr[high]: if low == high: if arr[low] == target: return low return -1
# Calculate the position using the interpolation formula pos = low + int(((high - low) / (arr[high] - arr[low])) * (target - arr[low]))
# Check if the target is found if arr[pos] == target: return pos
# If the target is larger, search in the upper part if arr[pos] < target: low = pos + 1
# If the target is smaller, search in the lower part else: high = pos - 1
return -1 # Element not found
# Example usage: if __name__ == "__main__": data = [10, 12, 13, 16, 18, 19, 20, 21, 22, 23, 24, 33, 35, 42, 47] target = 33 result = interpolation_search(data, target)
if result != -1: print(f"Element found at index: {result}") else: print("Element not found in the list.")
You can also try this code with Online Python Compiler
Jump search is an algorithm for searching a sorted array by jumping ahead by fixed steps (square root of the array length) and then performing a linear search within a block. It works well when elements are uniformly distributed.
How the algorithm works:
Divide the array into blocks of size √n.
Jump ahead by √n steps to find the block where the element might exist.
Exponential search (also known as exponential binary search) is used to search a sorted array. It is an optimized version of binary search where the search interval grows exponentially.
How the algorithm works:
Start with an initial range [0, 1] and double the range exponentially.
Once the range is found, perform a binary search within that range.
def exponential_search(arr, target): if arr[0] == target: return 0 i = 1 while i < len(arr) and arr[i] <= target: i *= 2 return binary_search(arr, target, i // 2, min(i, len(arr) - 1))
Fibonacci Search is an efficient search algorithm based on the Fibonacci sequence. It is used for searching in sorted arrays and is similar to binary search but uses Fibonacci numbers to divide the search range.
How the algorithm works:
Use Fibonacci numbers to determine the search range and split the array.
If the element is smaller than the pivot, reduce the range to the left; if it is larger, reduce the range to the right.
Tree-based searching uses hierarchical structures like Binary Search Trees (BST) for organizing data. It allows efficient searching with O(log n) time complexity on balanced trees.
How the algorithm works:
Traverse the tree from the root node.
If the target is less than the current node's value, move to the left child; if greater, move to the right child.
Hash-based searching involves using a hash function to store and query data. Bloom filters are a probabilistic data structure used to test if an element is in a set, with a possible false positive.
How the algorithm works:
Multiple hash functions check the presence of an element in a bit array.
If all positions are set to 1, the element might exist; if any position is 0, the element definitely does not exist.
apple in Bloom Filter: True
orange in Bloom Filter: False
String Searching Algorithms
String searching algorithms are used to find a substring in a string. Algorithms like KMP, Boyer-Moore, and Rabin-Karp are used for efficient pattern matching.
How the algorithm works:
These algorithms preprocess the pattern to reduce unnecessary comparisons, improving the search time complexity.
Implementation:
Python
Python
def naive_search(text, pattern): n = len(text) m = len(pattern)
for i in range(n - m + 1): if text[i:i+m] == pattern: return i return -1
# Example usage text = "hello world" pattern = "world" result = naive_search(text, pattern)
print(f"Pattern '{pattern}' found at index {result}")
You can also try this code with Online Python Compiler
Importance of Searching in Data Structures and Algorithms (DSA)
Speed of Data Access: Efficient searching algorithms reduce the time it takes to access data, improving performance in applications that require fast data retrieval, such as transaction processing systems and high-frequency trading platforms.
Resource Optimization: Good searching techniques help in minimizing the use of system resources like memory and processing power. This is particularly crucial for devices with limited resources, such as mobile devices or embedded systems.
Enhancing User Experience: In user-facing applications, such as web applications or mobile apps, efficient searching can greatly enhance user experience by providing instant feedback and quick results, keeping users engaged.
Scalability of Applications: Effective search methods allow applications to handle larger datasets without a significant decrease in performance. This scalability is essential for growing businesses that accumulate large amounts of data over time.
Educational Foundation: For computer science students, understanding searching algorithms is crucial for grasping more complex concepts in algorithms and data structures, laying a strong foundation for their academic and professional growth.
Impact on Competitive Programming: Searching is a popular topic in competitive programming, where the ability to implement efficient search solutions can dramatically affect contest outcomes and rankings.
Critical for Data Analysis: Searching algorithms are pivotal in data analysis tasks, allowing analysts to quickly sift through vast datasets to find relevant insights and patterns, which is essential for decision-making processes in business and research.
Applications of Searching Algorithm
Database Management Systems: Searching is fundamental in databases. Efficient search algorithms enable quick data retrieval from vast databases, which is crucial for performance in applications ranging from online retail to financial services.
Search Engines: The backbone of search engines is complex searching algorithms that sift through immense amounts of web data to find relevant results based on user queries. These algorithms continually refine their searches to improve accuracy and speed.
Operating Systems: Searching mechanisms in operating systems help manage files and directories. Efficient searching allows quick file retrieval and effective organization of data on the hard drive.
E-commerce Platforms: On e-commerce sites, searching helps customers find products quickly. Algorithms optimize these searches to match products to user queries accurately, enhancing the shopping experience.
Data Science and Machine Learning: Searching algorithms are used in data preprocessing to locate and organize data efficiently. This organization is crucial for effective analysis and machine learning model training.
Networking: In networking, search algorithms can help manage routing tables used in network routers, which direct traffic efficiently across the internet.
Bioinformatics: In bioinformatics, searching is essential for sequence alignment and genetic sequencing, helping scientists match DNA sequences and understand genetic structures.
Library Implementations of Searching Algorithms
Many programming languages offer built-in libraries that include implementations of various searching algorithms, making it easier for developers to integrate these functionalities into their applications without needing to write the algorithms from scratch. Here are some examples of how searching algorithms are implemented in popular programming libraries:
Python
bisect Module: Python’s bisect module provides support for maintaining ordered lists via binary search. It allows insertion and searching operations to be performed efficiently on sorted lists.
numpy Library: For numerical computations, the numpy library offers functions like searchsorted, which performs a binary search on arrays, helping to locate elements quickly within large numerical datasets.
Java
Collections Framework: Java's Collections framework includes classes like Arrays and Collections, which have static methods such as binarySearch() that implement binary search on arrays and collections.
C++
Standard Template Library (STL): The C++ STL provides functions like lower_bound and upper_bound which use binary search techniques to find elements or their insertion points in sorted ranges.
JavaScript
Lodash Library: In JavaScript, libraries like Lodash include utilities for working with arrays and objects, such as the _.sortedIndex() method, which uses a binary search algorithm to determine the smallest index at which a value should be inserted into an array to maintain order.
These library functions are optimized for performance and tested for reliability, ensuring that developers can confidently use them in various applications. Utilizing these libraries not only saves time and effort but also reduces the potential for errors that might occur when implementing complex search algorithms from scratch.
By leveraging these built-in functions, developers can focus more on building the functionality of their applications rather than worrying about the underlying data search operations, which are critical for handling and manipulating large datasets effectively.
Frequently Asked Questions
Why is it important to choose the right searching algorithm?
Choosing the right searching algorithm is crucial because it can significantly affect the efficiency of data retrieval and overall application performance. Different algorithms are suited for different data structures and requirements, and selecting an appropriate one can reduce computational time and resource usage.
Can I use linear search on sorted data?
Yes, you can use linear search on sorted data, but it is not the most efficient method. Sorted data typically benefits more from algorithms like binary search or interpolation search, which can find elements much faster than linear search.
How do I decide which searching algorithm to implement?
The choice of a searching algorithm depends on several factors, including the size of the data, whether the data is sorted or unsorted, and the frequency of searches. For large, sorted datasets, binary search or interpolation search is usually more efficient. For smaller or unordered datasets, a linear search might be sufficient.
Conclusion
In this article, we have talked about the fundamental concepts of searching in data structures, looked into various searching methods such as linear, binary, and interpolation search. We've also discussed their importance in software applications across different domains, such as databases, e-commerce, and data science. Furthermore, we highlighted how these searching algorithms are readily available in popular programming libraries, allowing developers to efficiently integrate robust search functionalities into their applications.






























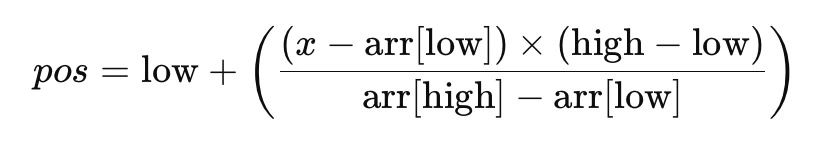


 8+ registered
8+ registered 

