Algorithm🧑🏻💻
👉🏻 At first, declare a hash table with name occurrence.
👉🏻 Now, we will use the declared hash table to store the frequency of each string which is stored in the vector called sequence.
👉🏻 Now iteration over the hash table is done by the function findSecondMostRepeated, and then the second most repeated string is found.
👉🏻 Print the string.
You can also read about the Longest Consecutive Sequence.
Implementation In C++💻
C++ code for the problem statement second most repeated word in a sequence.
#include <bits/stdc++.h>
using namespace std;
string findSecondMostRepeated(vector<string> sequence){
unordered_map<string, int> occurrence;
for (int i = 0; i < sequence.size(); i++)
occurrence[sequence[i]]++;
int firstMax = INT_MIN, secondMax = INT_MIN;
for (auto it = occurrence.begin(); it != occurrence.end(); it++) {
if (it->second > firstMax) {
secondMax = firstMax;
firstMax = it->second;
}
else if (it->second > secondMax && it->second != firstMax)
secondMax = it->second;
}
for (auto it = occurrence.begin(); it != occurrence.end(); it++)
if (it->second == secondMax)
return it->first;
}
int main(){
vector<string> sequence = { "ddd", "yh",
"yh", "ddd", "ddd", "vv" };
cout << "The string \""<<findSecondMostRepeated(sequence)<<"\" is the second most repeated word in the sequence.";
return 0;
}

You can also try this code with Online C++ Compiler
Output -
The string "yh" is the second most repeated word in the sequence.
Implementation In Java💻
Java code for the problem statement second most repeated word in a sequence.
import java.util.*;
class codingNinjas{
static String findSecondMostRepeated(Vector<String> sequence){
HashMap<String, Integer> occurrence = new HashMap<String,Integer>(sequence.size()){
@Override
public Integer get(Object key) {
return containsKey(key) ? super.get(key) : 0;
}
};
for (int i = 0; i < sequence.size(); i++)
occurrence.put(sequence.get(i), occurrence.get(sequence.get(i))+1);
int firstMax = Integer.MIN_VALUE, secondMax = Integer.MIN_VALUE;
Iterator<Map.Entry<String, Integer>> itr = occurrence.entrySet().iterator();
while (itr.hasNext()){
Map.Entry<String, Integer> entry = itr.next();
int v = entry.getValue();
if( v > firstMax) {
secondMax = firstMax;
firstMax = v;
}
else if (v > secondMax && v != firstMax)
secondMax = v;
}
itr = occurrence.entrySet().iterator();
while (itr.hasNext()){
Map.Entry<String, Integer> entry = itr.next();
int v = entry.getValue();
if (v == secondMax)
return entry.getKey();
}
return null;
}
public static void main(String[] args){
String arr[] = { "ddd", "yh", "yh", "ddd", "ddd", "vv" };
List<String> sequence = Arrays.asList(arr);
System.out.print("The string \"" + findSecondMostRepeated(new Vector<>(sequence)) +"\" is the second most repeated word in the sequence.");
}
}
You can also try this code with Online C++ Compiler
Output -
The string "yh" is the second most repeated word in the sequence.
Implementation In Python💻
Python code for the problem statement second most repeated word in a sequence.
def findSecondMostRepeated(sequence):
occurrence = {}
for i in range(len(sequence)):
occurrence[sequence[i]] = occurrence.get(sequence[i], 0) + 1
firstMax = -10**8
secondMax = -10**8
for it in occurrence:
if (occurrence[it] > firstMax):
secondMax = firstMax
firstMax = occurrence[it]
elif (occurrence[it] > secondMax and occurrence[it] != firstMax):
secondMax = occurrence[it]
for it in occurrence:
if (occurrence[it] == secondMax):
return it
if __name__ == '__main__':
sequence = [ "ddd", "yh", "yh", "ddd", "ddd", "vv" ]
print("The string \"",findSecondMostRepeated(sequence),"\" is the second most repeated word in the sequence.")
You can also try this code with Online Python Compiler
Output -
The string "yh" is the second most repeated word in the sequence.
Complexities of Algorithm🎯
The time and space complexity of the given solution for the problem statement to find the second most repeated word in a sequence are given below.
Time Complexity
Vector is iterated only once in the loop where we are assigning the value of secondMax and firstMax inside the function findSecondMostRepeated(Vector<String> sequence), so the time complexity of the above solution is O(N), where ‘N’ is the given vector’s size.
Space Complexity
O(N) space is needed for storing the hash table, where N is the given vector’s size.
Check out this article - C++ String Concatenation
Frequently Asked Questions🤔
What is hashing?
In the data structure, hashing is a technique of mapping a large part of data into small tables using a hashing function.
What is a hash table?
Hashtable is a data structure where keys are mapped to their values, where a unique index s assigned to each key. Accessing value becomes more manageable if we know the index of the value. Calculating a unique index for each key hash table uses hashing technique.
What are the two parts of the hash table?
The Hash table consists of two parts: Hash function and Array.
What is an array?
An array stores similar data type elements and has a fixed size. It stores elements in the contagious memory location, which means there is no space between the elements of an array in the memory location. In the hash table, it helps to hold all the key-value entries.
What is the hash function?
For performing hashing technique we use this hash function. That helps to find the index of our key-value pair.
What is Boolean?
A data type called boolean has two possible values to assign, which are also called truth values that are "true" and "false".
Conclusion
In this blog, we discussed the problem statement to find the second most repeated word in a sequence using hashing method, including the algorithm, code, and its complexities and if you would like to learn more, check out our articles on Count quadruples from four sorted arrays whose sum is equal to a given value x and Count Divisible Pairs in an Array.
Refer to our guided paths on Coding Ninjas Studio to learn more about DSA, Competitive Programming, JavaScript, System Design, etc. Enroll in our courses and refer to the mock test and problems available. Take a look at the interview experiences and interview bundle for placement preparations.
Do upvote our blog to help other ninjas grow.

Happy Learning Ninja! 🥷




























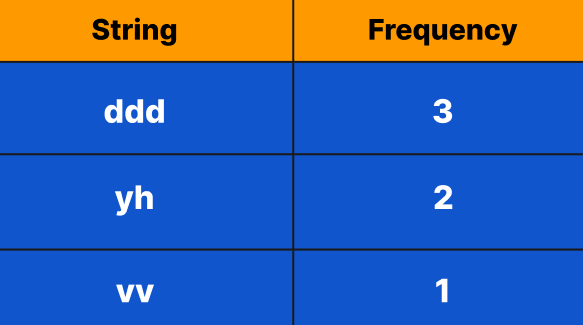







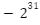 , which is < 3, so we will change the value of firstMax to 3 as it is the first maximum number we encountered, and secondMax will be equal to firstMax.
, which is < 3, so we will change the value of firstMax to 3 as it is the first maximum number we encountered, and secondMax will be equal to firstMax.



 8+ registered
8+ registered 

