Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In MapReduce, minimizing the network traffic and optimizing the partition scheme are very crucial operations to optimize the job performance, and these two operations are done under the Shuffle and Sort Phase.
This article will discuss all the phases of MapReduce, especially the Shuffle and Sort Phase. We will discuss all the key aspects of these phases and some practices to optimize MapReduce job performance.
What is MapReduce?
MapReduce is a software framework that performs the processing of large distributed data sets in a parallel manner. It consists of two distinct phases - Map and Reduce. There is also a Shuffle and Sort phase that is performed in between them. It is used for large-scale data processing by dividing the data into smaller chunks, then processing those chunks in a parallel manner, and finally combining the results to get a final output.
Map Phase in MapReduce
The Map Phase is the first Phase of MapReduce which processes the data in parallel across multiple nodes. These nodes have their own Map Functions that take an input record as input and apply some operations to it to give an output in the form of intermediate key-value pairs.
Some important key aspects of Map Phase in MapReduce
It is responsible for processing the data in multiple nodes by dividing it into chunks and assigning each chunk to a node for processing.
It requires a user-defined Map Function which takes an input record to give an intermediate key-value pair.
The key-value pairs generated by the Map Function are sorted by key in the Shuffle and Sort Phase so that pairs having the same keys can group together.
If a node fails while processing the data, the work gets shifted towards other nodes, so there can’t be any interruption during processing.
Shuffle and Sort in MapReduce
The Shuffle and Sort Phase occur in between the Map and Reduce Phases. In this Phase, all the key-value pairs generated by the Map Function are grouped together based on their keys and then sorted by their keys.
Some important key aspects of the Shuffle and Sort in MapReduce
Transferring data from Mapper to Reducer comes under shuffling.
The grouping of key-value pairs reduces the operating time because during the Reduce Phase, we can operate the key-value pairs having the same key simultaneously.
The sorting phase is necessary to ensure that the key-value pairs with the same key are grouped together.
The sorted key-value pairs are divided into segments so that each segment can be processed independently by the Reduce Phase. These segments are divided in such a way that each segment has the key-value pairs with the same key.
It enables parallel processing, reduces network traffic and improves the overall performance.
Practices to optimize the Shuffle and Sort in MapReduce
Using the custom partitioners is beneficial because they select the partition number based on the hash value, which is a constant time operation and improves the performance of the Shuffle and Sort Phase.
The number of partitions used in the Shuffle and Sort Phase can significantly impact the performance. Choosing the number of partitions as the multiple of the number of nodes in a Reduce Phase is good practice.
The use of combiners can optimize the Shuffle and Sort Phase by reducing the amount of data that needs to be transferred to the Reducers by aggregating the output of the Mappers.
If Sorting is optional for any task, it would be beneficial not to Sort the key-value pairs because Sorting is time-consuming.
Implementation of Shuffle and Sort in MapReduce
Code
#include <bits/stdc++.h>
using namespace std;
// Shuffle Function
vector <pair<string, vector<int>>> Shuffle(vector <pair<string, int>> &data_set) {
map <string, vector <int>> mapping;
// result will store the shuffled key-value pairs
vector <pair<string, vector<int>>> result;
vector <string> temporary;
unordered_set <string> mark;
// temporary is for maintaining the order of keys
// mark is for checking whether the key is present in the temporary vector or not
for(auto &x : data_set) {
string key = x.first;
int value = x.second;
mapping[key].emplace_back(value);
// check if the key is present or not
if(mark.find(key) == mark.end()) {
mark.insert(key);
temporary.push_back(key);
}
}
// push the key-value pairs in the order maintained by the temporary vector
for(auto &x : temporary) {
result.push_back({x, mapping[x]});
}
return result;
}
// Sort Function
vector <pair<string, vector <int>>> Sort(vector <pair<string, vector<int>>> &Shuffled_data) {
vector <pair<string, vector<int>>> result;
for(auto &x : Shuffled_data) {
result.push_back({x.first, x.second});
}
sort(result.begin(), result.end());
return result;
}
int main() {
vector <pair<string, int>> data_set = {
{"ask", 1},
{"then", 5},
{"ask", 2},
{"when", 4},
{"when", 10},
{"okay", 7},
{"when", 7}
};
vector <pair<string, vector<int>>> shuffled_data = Shuffle(data_set);
cout << "Shuffled Data\n";
for(auto &x : shuffled_data) {
cout << x.first << " : [";
int k = x.second.size(), cnt = 0;
for(auto &y : x.second) {
cout << y;
cnt ++;
if(cnt < k) cout << ' ';
}
cout << "]\n";
}
cout << "\nSorted Data \n";
vector <pair<string, vector<int>>> sorted_data = Sort(shuffled_data);
for(auto &x : sorted_data) {
cout << x.first << " : [";
int k = x.second.size(), cnt = 0;
for(auto &y : x.second) {
cout << y;
cnt ++;
if(cnt < k) cout << ' ';
}
cout << "]\n";
}
return 0;
}
You can also try this code with Online C++ Compiler
Shuffled Data
ask : [1 2]
then : [5]
when : [4 10 7]
okay : [7]
Sorted Data
ask : [1 2]
okay : [7]
then : [5]
when : [4 10 7]
The Shuffle Function is for grouping the key-value pairs based on the keys. The “mapping’ map used here is for storing the list of values corresponding to a particular key. The “result” vector is storing our shuffled data containing the grouped key-value pairs. The “temporary” vector is for maintaining the order of the keys. We will maintain this order by storing the keys in the set (“mark”) and push the keys into the “temporary” vector only when the key is not present in the set. After iterating the whole Data Set, all the key-value pairs will be stored in the map. We will push these grouped key-values into the “result” vector in the order maintained by the “temporary” vector. The Sort Function takes Shuffled Data as a parameter. Here we have used an inbuilt Sort Function provided by the C++ library. It will sort the shuffled data based on the first element. In our case, the first element is key, so there is no need to make a comparator
Reduce Phase in MapReduce
The Reduce Phase is the final Phase of the MapReduce job. During the Reduce Phase, the intermediate key-value pairs are passed to the Reduce Function, grouped by their keys. The Reduce Function performs the user-defined operation on these key-value pairs, giving us the output, the final output of the MapReduce job.
Some important key aspects of the Reduce Phase in MapReduce
The Reduce Phase is responsible for performing the user-defined operations on the values associated with the key.
The Reduce Function can perform any operation on the values associated with the keys such as sum, average and many other aggregate functions.
The Reduce Function is designed to run on multiple nodes with each node having a subsequence of key-value pairs.
This phase can be used to remove the duplicates from the key-value pairs.
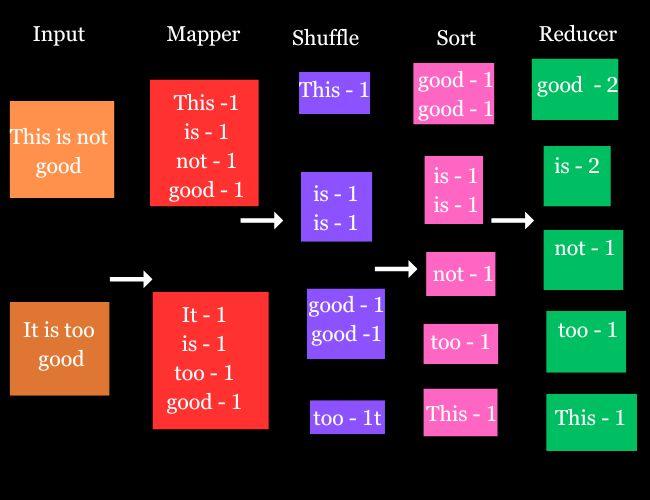
Example to visualize the Phases of MapReduce
You can see the above image to visualize the phases of MapReducer from Mapper to Reducer. Starting from the Mapper, it divides the input data into smaller chunks of key-value pairs. Then, the shuffling process groups all the key-value pairs based on their keys. After that, all these key-value pairs are sorted based on their keys. At last, all these pairs are divided by the segments, where each segment has pairs having the same key.
Frequently Asked Questions
What is the role of the partitioner in the Shuffle and Sort Phase of MapReduce?
The partitioner in the MapReduce Shuffle and Sort Phase ensures that all the key-value pairs with the same key are sent to the same Reducer. It uses a hash function to assign each key-value pair a specific partition number.
What are the best practices for optimizing Shuffle and Sort in MapReduce?
The best practices to optimize the Shuffle and Sort Phase are using combiners to reduce the network traffic, efficient Sorting algorithms, and custom partitioners due to their constant time operation.
How does the Shuffle and Sort Phase affect the performance of a MapReduce job?
The Shuffle and Sort Phase affect a MapReduce job's performance, as it involves transferring a large amount of data across the network and grouping the related data, reducing the processing time.
Conclusion
In this article, you’ve learned the Shuffle and Sort in MapReduce, along with the Map and Reduce phases and their key aspects. We’ve also covered an example to visualize the phases of MapReduce and the implementation details of Shuffle and Sort in MapReduce.































 9+ registered
9+ registered 

