Do you think IIT Guwahati certified course can help you in your career?
Introduction
Sigmoid functions are the fundamental building block of the deep neural network. Sigmoid functions are similar to perceptrons and MP Neuron Model, but the significant difference is that sigmoid neurons are smoother at the boundary than perceptrons and MP Neuron Model.
In a sigmoid neuron, for every input xi, it weights wi associated with it. The weights depict the importance of the input in the decision-making process. The output from sigmoid ranges between zero to one, which we can interpret as a probability rather than zero or one like in the perceptron model. One of the most commonly used sigmoid functions is the logistic function, characteristic of an "S" shaped curve.
The perceptron model takes several real-valued inputs and gives a single binary output. In the perceptron model, for every input xi, weight wi is associated. The weights depict the importance of the information in the decision-making process. We decide the model output by a threshold of Wₒ. If the weighted sum of the inputs xi exceeds the threshold outcome will be one; otherwise, the result will be zero. In other words, the perceptron model will fire if the weighted sum of inputs is greater than the threshold.
Let's take an example, we have a person's salary in thousands and based on that, and we are trying to decide whether the person can buy a car or not. Our Perceptron model has a threshold of 50k. So model says that a person with a 50.1k salary can likely buy a car, and the person with a 49.9k wage can not. This decision made by Perceptron is very harsh in real-time, whereas we generally make a smooth decision. If we think practically, isn't it a bit odd that a person with 50.1K can buy a car, but someone with 49.9K can not buy a car? The slight change in the input to a perceptron can sometimes cause the output to flip, say from zero to one ultimately. This behavior showed by the perceptron model is not a characteristic of the specific problem we choose or the particular weight or the threshold we define. This is the behavior of the perceptron neuron itself, which behaves like a step function. We can overcome this problem by introducing a new artificial neuron called a sigmoid neuron.
Now, let's look at the building process of the sigmoid neuron:
Data and Task
We can use the sigmoid neuron for both binary classification and regression. The inputs of the sigmoid neuron can be real numbers, unlike the boolean inputs in Multi-layer Perceptron Neuron, and the output will also be an actual number ranging between 0–1. In the sigmoid neuron, we try to regress the relationship between X and Y in terms of probability. Even though we know that the output is between 0–1, we can still use the sigmoid function for binary classification tasks by taking some threshold values.
Model
The sigmoid function gives us an "S-shaped function," much smoother concerning 0/1 perceptron. Given X(high dimensional real value input) and Y(real value output between 0-1), the approximate relationship between the two is given by the Sigmoid function.
In the case of one-dimensional input X,
In the case of multi-dimensional input X,
Loss Function
We will use the well-known loss function technique, i.e., the squared error loss function. It is the sum of the square difference between the actual and predicted output.
We can use another technique to measure loss function, i.e., Cross-entropy loss function.
Learning Algorithm(Gradient Descent)
Under this tag, we will study how an algorithm learns the parameters w and b of the sigmoid neuron model by using a gradient descent model. The main objective of this learning algorithm is to determine the best optimal values of w and b such that the predicted output is as close to the actual output, i.e., minimize the loss function.
Initially, we randomly chose the value of w and b. We then iterate over the training data inputs. We calculate the predicted outcome using the sigmoid function for each observation, then compute the loss using the loss function(squared-error loss). Based on the loss value, we update the value of the weights and bias, such that the loss due to these new parameters is less than the previous one.
We will keep on repeating the above process until we reach the following three conditions:
The loss of the model becomes zero.
We have already performed enough iterations based on the computational capacity.
The overall loss of the model becomes negligible or closer to zero.
If any of the three conditions are met, we stop the process.
We saw how the weights are getting updated based on the loss value. This section will know why this specific update rule would reduce the model's loss. To understand why the update work rule works, we need to understand its math.
Maths Behind Learning Algorithm
We can represent the two parameters in the sigmoid function in a vector theta.
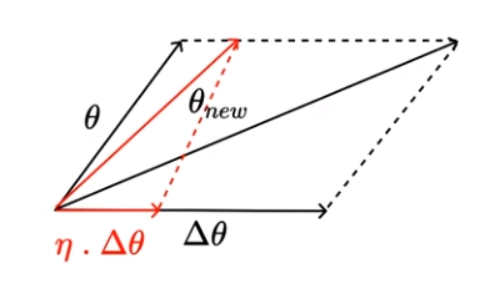
So the geometric representation of theta and new theta. As both are vectors, they should follow the parallelogram vectors law, so the resulting new theta is diagonal of the parallelogram. From the geometrical representation, it is clear that there is a large change between the value of theta and new theta, so to take small conservative steps, we multiply the delta theta with a constant known as the learning rate. So the new theta will have value:
Geometrical Representation
Now the question arises how to decide the value of delta theta? Well, we have to find such value of the new theta such that the loss due to the new theta is less than that of the old theta. The answer to this question is given from the Taylor series.
Taylor Series
Taylor series states that if we know the values of a function f at x, then the value at a new point that is too close to x is given by:
We will now reduce the Taylor series in terms of sigmoid neuron parameters and loss function. For simplicity, let’s assume delta theta=u, then the equation reduces to,
We have to find the optimal value of the change vector uT such that the value after L(theta) turns out to be negative. If the value is negative, we can say that the loss at the new theta is less than the loss at the old theta.
For simplicity, let us approximate the above equation as the learning rate is minimal. Any positive value raised to the learning rate will be too negligible to consider reducing the above Taylor series to the second equation in the above image.
To solve the above equation, let’s apply a bit of linear algebra. As we know, the cosine angle between two vectors is cos(θ), ranging from -1 to 1.
So the final equation is marked red above; in the case of two data points, the equation changes to:
Evaluation
With the help of the actual output and the predicted output, we can find the accuracy of the regression model by using RMSE(Root Mean Squared Error). While in the case of the classification model, we can evaluate the accuracy by :
accuracy=(total correct predictions)/(total number of predictions).
Implementation
Now moving into the implementation part,
X = [1.4,2.5] Y = [0.6,0.9]
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D %matplotlib inline w_values = [] b_values = [] loss_values = []
deff(w,b,x): return1. / (1. + np.exp(-(w*x)+b)) deferror(w,b): err = 0.0 for x,y in zip(X,Y): fx = f(w,b,x) err += 0.5*(fx-y)**2 return(err)
defgradient_descent(): w,b,eta = 0, -8, 1.0 for i in range(1000): dw, db = 0, 0 for x, y in zip(X, Y): dw += grad_w(w,b,x, y) db += grad_b(w,b,x, y) w -= eta*dw b -= eta*db w_values.append(w) b_values.append(b) loss_values.append(error(w,b))
gradient_descent()
Frequently Asked Questions
What is the difference between Sigmoid and ReLU? Relu is more computationally efficient than Sigmoid functions since Relu finds the max(0,x) and does not perform expensive exponential operations as in the case of Sigmoids.
What are the properties of the sigmoid neuron? In the sigmoid neuron, a slight change in the input causes a small change in the output instead of the stepped work–many functions characteristic of an "S" shaped curve known as sigmoid functions.
What are the limitations of the sigmoid neuron? The two significant limitations with sigmoid activation functions are: Sigmoid saturation and kill gradients: The output of sigmoid saturates (i.e., the curve becomes parallel to the x-axis) for a significant positive or negative number. Thus, the gradient at these regions is almost zero.
Key Takeaways
Let us brief the article.
Firstly, we saw the limitation of the perceptron neuron that led to the discovery of the sigmoid neuron. Furthermore, we saw how sigmoid neurons overcome the limits of the Perceptron. We saw the building blocks to develop a sigmoid neuron, then moving forward, we saw the in-depth intuition of the learning algorithm with the help of the Taylor series, linear algebra, and partial derivatives. And at last, we saw the implementation of the learning algorithm.
That's the end of the article. Stay updated for more exciting articles like these.



























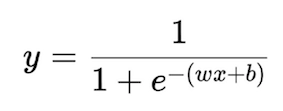
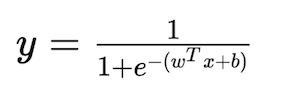

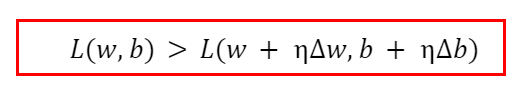
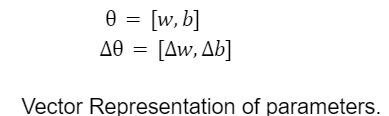
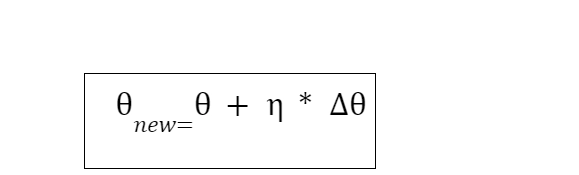
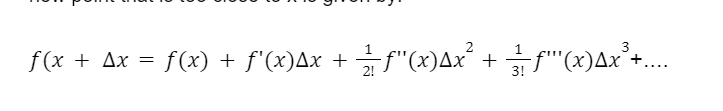
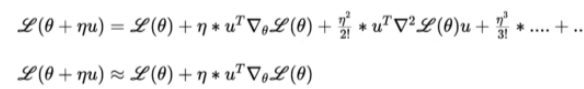

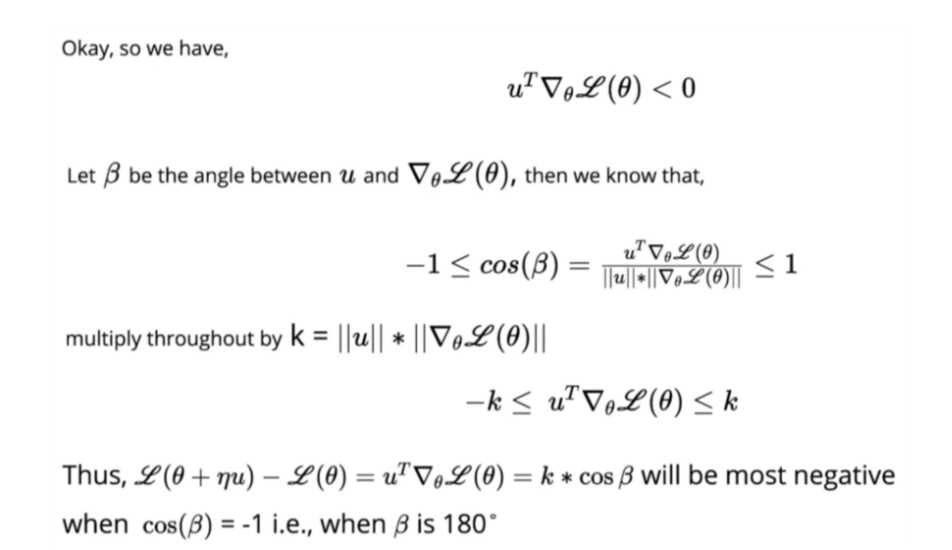
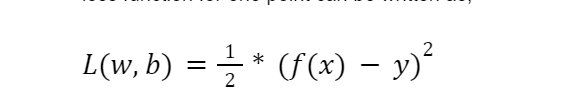
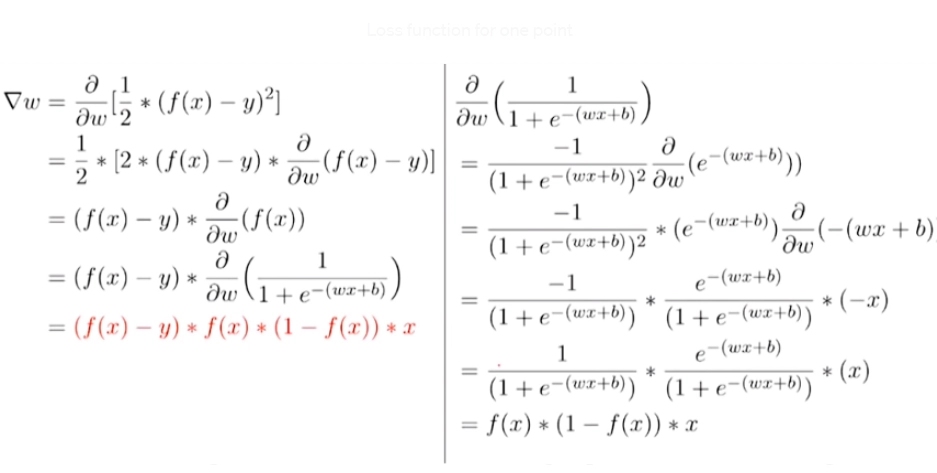
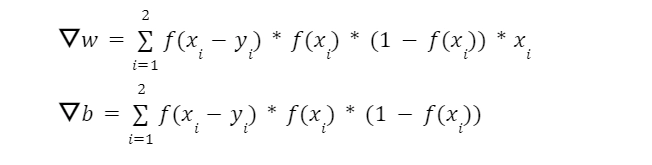

 8+ registered
8+ registered 

