Do you think IIT Guwahati certified course can help you in your career?
Introduction
LR Parsing is a bottom-up parsing method. It is used to parse context-free grammar, which is primarily used by compilers. Shift-Reduce Parsing (SLR Parsing) is a type of LR Parsing that is used to examine the syntax of a given input string. Head over to the below blog to get a better understanding of SLR Parser.
The article thoroughly covers the key elements of the Shift-Reduce Parsing (SLR Parsing) algorithm. It describes how the algorithm works, constructing a parsing table from the input symbols along with the stack implementation of a test input.
What is a Parser?
A parser is a piece of software that typically comes with a compiler. It receives input using defined interfaces such as markup tags, interactive online commands, and sequential source program instructions. The information that parsers receive is divided into components such as nouns (things), verbs (methods), and their characteristics or alternatives. A parser may additionally verify that all required input has been supplied. There are two types of parsers in compiler technology; top-down parsers and bottom-up parsers.
When parsing is done top-down, the input symbol is first transformed into the start symbol. The bottom-up method of parsing builds the parse tree from the input symbol to the start symbol by reversing the rightmost string derivations.
LR Parsers
The LR parser is a bottom-up, shift-reduced, non-recursive parser. It employs a broad class of context-free grammar, making it the most effective syntax analysis tool. LR parsers are also referred to as LR(k) parsers, where L stands for left-to-right scanning of the input stream, R for building the right-most derivation backward, and k is the number of lookahead symbols to be used for decision-making. Programming languages of all kinds can be handled by LR parsers, which are strong and effective. They are utilized by a number of well-known interpreters and compilers, including the Python interpreter and the GCC compiler.
Advantages of LR Parsing
Some of the significant advantages of LR parsing are given as follows:
LR parsers can parse a strictly larger class of grammars than (top-down) predictive parsers.
LR parsers can usually recognize all programming language constructs specified by a context-free grammar.
It understands almost every programming construct that CFG may be expressed in.
LR parsers detect errors quickly.
Types of LR Parsing Methods
LR parsing contains three types of methods which are discussed below:
Simple LR(SLR): Execution is relatively simple and inexpensive. But for particular classes of grammar, it is unable to create a parsing table. It creates parsing tables that aid in performing input string parsing. SLR Parsing is possible with the provision of context-free grammar.
Canonical LR(CLR): The CLR (1) parsing table is built using the canonical set of LR (1) entries. Compared to SLR (1) parsing, the CLR (1) parsing table creates more states. It can only find the reduction node in the lookahead symbols in the CLR (1).
Look-Ahead LR(LALR): it has a medium level of power as compared to SLR and CLR parsers. The tables that result from this will be smaller than those from the CLR Parser because it is compacted.
SLR(1) Parser
SLR (1) refers to simple LR Parsing. It is similar to LR(0) parsing because LR(0) parsing requires just the canonical items for the construction of a parsing table, The only thing that differentiates the LR(0) parser from the SLR parser is the possibility of a shift reduced conflict because we are entering reduce corresponding to all terminal states in the LR(0) parsing table. This issue can be resolved by entering "reduce" in the terminating state, which corresponds to the FOLLOW of the LHS of production. This collection of items is known as SLR(1). A collection of rules is used to create the table using the provided grammar in order to determine the closure and goto operations for each state. The SLR parsing algorithm is reasonably easy to use and effective.
The various steps involved in the SLR (1) Parsing are shown in the given flowgraph:
Working of SLR(1) Parser
An SLR (Simple LR) parser is a bottom-up parsing technique that uses a deterministic finite automaton (DFA) to recognize the valid syntax of a language. A parse table is produced by this parser from a collection of grammar rules and the DFA. The grammar rule to apply at each stage of the parsing process is subsequently determined using the parse table.
Let's look at an example to better understand how the SLR parser functions.
Implement SLR Parser for the given grammar:
1. E→E + T
2. E→T
3. T→T * F
4. T→F
5. F→(E)
6. F→id
Step 1: Create augmented grammar using the provided grammar.
Augmented grammar:
E'→E
E→E + T
E→T
T→T * F
T→F
F→(E)
F→id
Step 2: Find LR(0) canonical Items
GOTO (I0, E)
l1: E’->E.
E->E.+T
GOTO (I0, T)
l2: E->T.
T->T.*F
GOTO (I0, F)
l3: T->F.
GOTO (I0, ( )
I4: F->(.E)
E->.E+T
E->.T
T->.T*F
T->.F
F->.(E)
F->.id
GOTO (I0, id)
I5: F->id.
GOTO (I1, +)
I6: E->E+.T
T->.T*F
T->.F
F->.(E)
F->.id
GOTO(I2, *)
I7: T->T*.F
F->.(E)
F->.id
GOTO(I4, E)
I8: F->(E.)
E->E.+T
GOTO(I4, T)
I2: E->T.
T->T.*F
GOTO(I4, F)
I3: T->F.
GOTO(I4, ( )
I4: F->(.E)
E->.E+T
E->.T
T->.T*F
T->.F
F->.(E)
F->.id
GOTO(I4, id)
I5: F->id.
GOTO(I6, T)
I9: E->E+T.
T->T.*F
GOTO(I6, F)
I3: T->F.
GOTO(I6, ( )
I4: F->(.E)
GOTO(I6, id)
I5: F->id.
GOTO(I7, F)
I10: T->T*F.
GOTO(I7, ( )
I4: F->(.E)
E->.E+T
E->.T
T->.T*F
T->.F
F->.(E)
F->.id
GOTO(I7, id)
I5: F->id.
GOTO(I8, ) )
I11: F->(E).
GOTO(I8, +)
I6: E->E+.T
T->.T*F
T->.F
F->.(E)
F->.id
GOTO(I9, *)
I7: T->T*.F
F->.(E)
F->.id
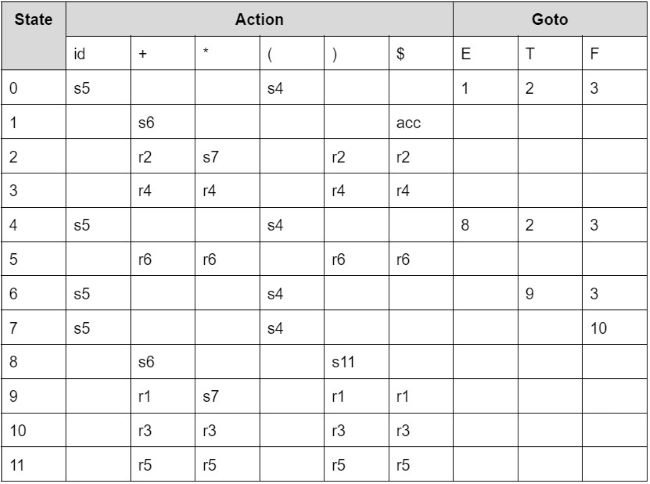
Step 3: Construct the Parsing table
To fill the reduction action in the ACTION section of the table, computation of FOLLOW is necessary.
Follow(E): {$, ), +}
Follow(T): {$, +, ), *}
Follow(F): {*, +, ), $}
In the above parsing table:
si means to shift and stack state i.
rj means reduce by production numbered j.
acc means accept.
Blank means error.
Step 4: Parse the given input. Parse the string id*id+id using stack implementation.
Stack
Input
Action
0
id*id+id$
s5 Shift 5
0 id 5
*id+id$
r6 Reduce by F->id
0 F 3
*id+id$
r4 Reduce by T->F
0 T 2
*id+id$
s7 Shift 7
0 T 2 * 7
id+id$
s5 Shift 5
0 T 2 * 7 id 5
+id$
r6 Reduce by F->id
0 T 2 * 7 F 10
+id$
r3 Reduce by T->T*F
0 T 2
+id$
r2 Reduce by E->T
0 E 1
+id$
s6 Shift 6
0 E 1 + 6
id$
s5 Shift 5
0 E 1 + 6 id 5
$
r6 Reduce by F->id
0 E 1 + 6 F 3
$
r4 Reduce by T->F
0 E 1 + 6 T 9
$
r1 Reduce by E->E+T
0 E 1
$
Accept
Using the SLR parser, the given input string has been fully parsed as shown in the table above.
Frequently Asked Questions
What is the limitation of the SLR parser?
One of the key limitations of SLR is that it can only handle grammars that fall under the SLR(1) class, which implies that the grammar must be straightforward and have only one lookahead symbol.
What is a symbol table?
The Symbol Table is an essential data structure that the compiler creates and maintains to keep track of the semantics of variables, which means, it keeps the information about the scope and binding of names, information about instances of various things, etc.
What is bootstrapping in compiler design?
Bootstrapping is the process of translating more complex programs into basic language, which may then be used to manage more complex programs. This complex program can manage still more complex programs, and so on.
Conclusion
This article explains the concepts of LR parsers, their advantages, and a complete working of SLR parsers using an example. We sincerely hope you enjoyed reading the article and learned a lot about this topic. For a better understanding of the subject, you can further refer to the Recursive Descent Parser, Bottom-Up Parsing, and LR Parsing.































 8+ registered
8+ registered 

