Do you think IIT Guwahati certified course can help you in your career?
Introduction
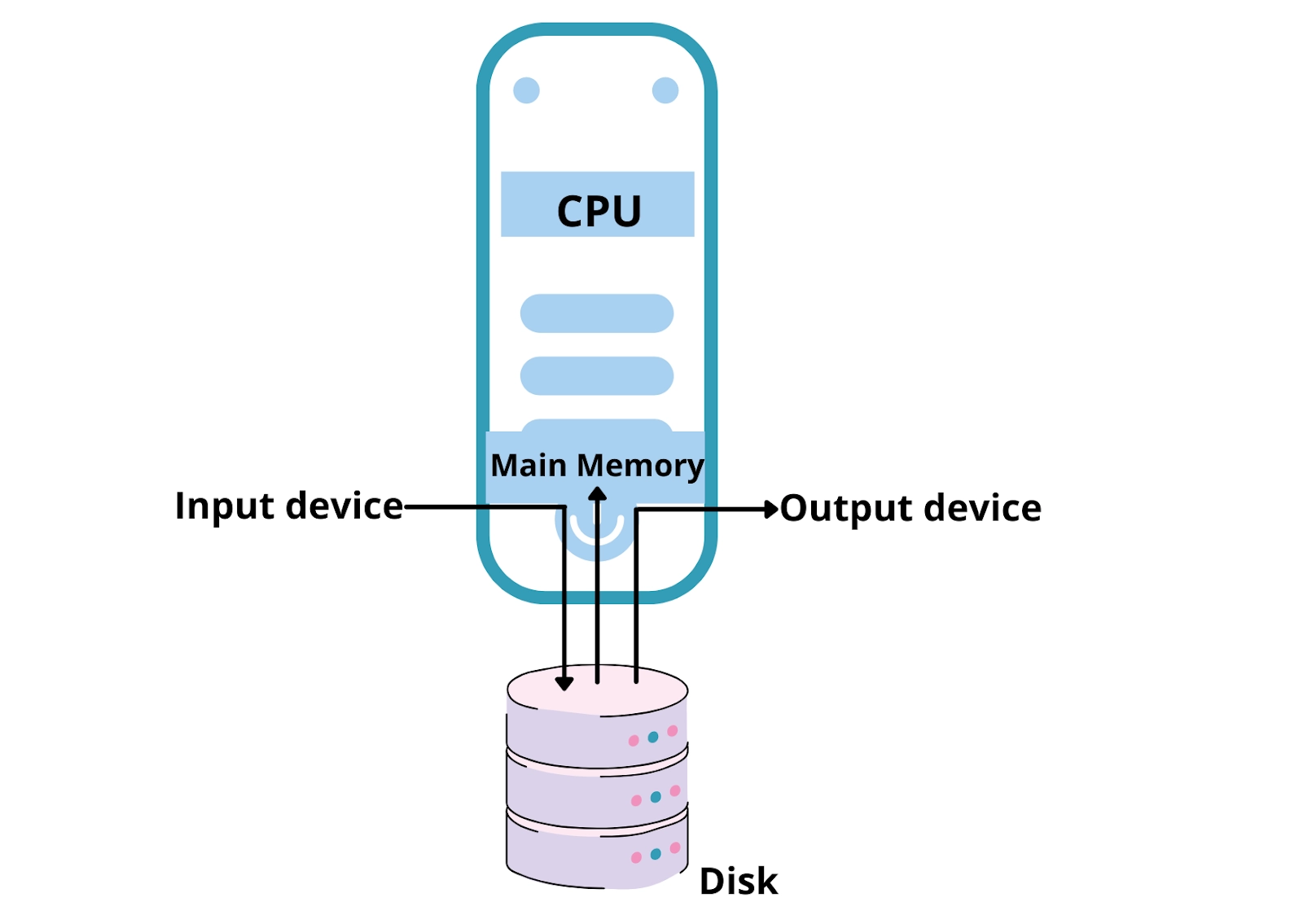
The CPU received input from the Operating System, processed the instructions, and produced the result. But there was a problem with this tactic.
Typically, we have to manage multiple processes at once, and we are aware that the time the CPU spends executing instructions is much less than the time it spends on I/O activities.
Therefore, in the previous way, the CPU is idle while one process provides input through an input device.
After carrying out the instruction, the CPU sits idle while the output is routed to a different output device. After the output is displayed, the next process is put into action.
The worst scenario for an operating system is when the CPU is idle for the majority of the time.
Here, the concept of spooling is relevant.
What is Spooling in Operating System?
Spooling is the temporary storage of data for usage and execution by a device, program, or system.
Data is transmitted to and held in memory or other volatile storage until the software or computer asks for it to be executed.
SPOOL stands for Simultaneous Peripheral Operations On-Line.
In most cases, the spool is kept in physical memory, buffers, or I/O device-specific interrupts on the computer.
The spool is processed in ascending order, using a first-in, first-out (FIFO) algorithm.
Spooling is the process of storing data from several I/O tasks in a buffer. This buffer is a particular memory or hard drive section that I/O devices can access.
An operating system performs the following tasks in a distributed environment:
Controls data spooling for Input/Output devices with varying data access speeds.
Maintains the spooling buffer, which acts as a data holding space while the slower device catches up.
The spooling procedure preserves parallel computing since a computer may perform Input/Output in parallel sequence.
Examples of Spooling
Here is an interesting example that we have all experienced. When your operating system hangs for any particular reason or your keyboard stops working while you are typing, have you noticed how all the alphabets that you pressed after the system hung suddenly get typed out very fast on their own even though you are not typing anymore? That is a classic example of spooling where the input or keys that you have pressed got registered and this data was sent to be stored.
When the computer or peripheral recovered from the malfunction, the tasks were then queued accordingly. This is why even when our system hangs, even if we type a lot of things very fast and click in multiple places, the alphabets will be processed in the original order or the exact same spots will be clicked. This is because all the input is being stored in its original order in the temporary or volatile storage and will be executed in the same order.
This can also be noticed while scanning or using Optical Character Recognition as well, as the characters or portion of the image that has been scanned is stored in temporary memory while the rest of it is processed and finally the total output is shown. Spooling in printers is one of the most common applications of spooling.
How Spooling Works in Operating Systems?
Spooling entails the creation of a buffer known as SPOOL, which is used to hold off jobs and data until the device in which the SPOOL is generated is ready to use and execute the job or act on the data.
When a faster device delivers data to a slower device to accomplish an operation, it uses any associated secondary memory as a SPOOL buffer. This data is stored in the SPOOL until the slower device is ready to process it. When the slower device is ready, the data in the SPOOL is put into the main memory for the necessary operations.
3. Spooling views the entire secondary memory as a massive buffer capable of storing multiple tasks and data for several processes. Spooling has the benefit of building a queue of tasks that execute in FIFO order to execute the jobs one by one.
4. A device can connect to a large number of input devices, each of which may require some data processing. As a result, all of these input devices may store their data in secondary memory (SPOOL), which may then be performed sequentially by the device. This prevents the CPU from becoming idle at any moment. As a result, Spooling is a mix of buffering and queuing.
5. After the CPU produces some output, it first saves it in the main memory. This output is transported from the main memory to the secondary memory and then to the appropriate output devices.
Applications of Spool
The most prevalent application is in I/O devices like keyboards, printers, and mouse. For example, in a printer, documents/files supplied to the printer are first saved in memory or the printer spooler. When the printer is ready, it reads from the spool and prints the data. Have you ever had a scenario where your mouse or keyboard suddenly stops working for a few seconds? Meanwhile, we normally click here and there on the screen to see if it is functioning or not. When it finally begins operating, anything and everywhere we pressed during the hanging stage is performed very quickly since all instructions were saved in the corresponding device's spool.
Spooling allows overlapping I/O operations for one job with processor operations for another. Hence, Multiple processes can simultaneously write documents to a print queue and then resume their work.
In batch processing systems, spooling is used to store a queue of ready-to-run jobs that may be started as soon as the system can handle them.
E-mail: An email is sent by an MTA (Mail Transfer Agent) to a temporary storage location where it awaits pickup by the MA (Mail User Agent)
Advantages of Spooling
It doesn't matter how many I/O devices or operations there are. Many I/O devices can operate concurrently without interfering with one another.
There is no communication between I/O devices and the CPU. This eliminates the need for the CPU to wait for I/O operations to complete.
The CPU is kept occupied most of the time and only enters the idle state when the queue is depleted.
It enables programs to function at the CPU's speed while I/O devices operate at their maximum speed.
Disadvantages of Spooling
Spooling needs a significant quantity of storage, which is determined by the number of requests made by the input and the number of input devices connected.
Because the SPOOL is generated on secondary storage, having several input devices working at the same time may take up a lot of space on secondary storage, increasing disk traffic. As a result, the disk becomes increasingly slower as the volume of traffic grows.
Frequently Asked Questions
What is spooling in printing?
Spool Printing allows print jobs transferred from a computer to be temporarily held before being printed following the transfer. This reduces printing time while increasing printer efficiency. Before printing, Spool Printing saves the print data to the hard drive.
What is a spooled device?
In a single-processor system, the spool device acts as a buffer between input devices and procedures that receive input data, as well as between routines that write output data and output devices.
What do you mean by spooling and buffering?
The primary distinction between spooling and buffering is that spooling is the way of temporarily storing data in a memory region so that a device or program may utilize it, whereas buffering is the method of temporarily storing data in a memory space while processing other remaining data.
What is a spooler in computer?
A spooler is a software program that manages the sequential processing of tasks or data by temporarily storing them in a queue (spool) until the system is ready to execute or print them.
What is spooling operating system?
A spooling operating system manages tasks by placing them in a queue (spool) for orderly processing. This technique optimizes resource utilization, especially for I/O devices, by allowing tasks to be executed in the background while others are being processed.
Conclusion
Cheers if you reached here! In this blog, we learned about Spooling in Operating systems.
We have covered the need for Spooling and its definition.
We have also seen its working with examples.
Further, we saw its several Applications.
We have also witnessed the Advantages and Disadvantages of Spooling in OS.
On the other hand, learning never ceases, and there is always more to learn. So, keep learning and keep growing, ninjas!






























 6+ registered
6+ registered 

