Do you think IIT Guwahati certified course can help you in your career?
Introduction
Site Reliability Engineering (SRE) is an emerging field that focuses on the intersection of software engineering and IT operations. It involves creating reliable and scalable systems and processes to ensure high availability and performance of applications and services. SRE roles are becoming increasingly popular, and the interview process for these positions typically involves a range of technical and non-technical questions to assess a candidate's skills and experience. In this blog, we will explore the top SRE interview questions and provide insights into how to answer them effectively.
SRE Interview Questions for Freshers
1) What is SRE?
SRE stands for Site Reliability Engineering. It is a discipline that combines software engineering practices with operations principles to create scalable and reliable software systems.
2) What is the benefit of SRE?
The benefit of SRE lies in its focus on ensuring the reliability, scalability, and efficiency of systems and services, leading to improved user experience, reduced downtime, and enhanced performance.
3) What are SRE(Site Reliability Engineer) skills?
SRE skills include expertise in system architecture, automation, coding, monitoring, incident response, and communication. Additionally, SREs possess strong problem-solving abilities and a deep understanding of software development and operations.
4) What are SRE methodologies?
SRE methodologies encompass practices such as error budgeting, service level objectives (SLOs), service level indicators (SLIs), blameless postmortems, and the use of automation and monitoring tools to maintain and improve system reliability and performance. These methodologies emphasize collaboration between development and operations teams to achieve shared reliability goals.
5) What are the pillars of SRE?
The DevOps Institute's SRE blueprint identifies Nine Pillars of engineering practices: site reliability leadership and culture, work sharing, monitoring, SLOs and SLIs, error budgets, toil reduction, deployments, performance management, incident management, and anti-fragility.
6) What is an SRE example?
Site reliability engineering (SRE) is a set of principles and practices that cooperates with various software engineering perspectives and implies them to operations and infrastructure problems. The main targets are to create scalable and highly reliable software systems.
7) What are SRE challenges?
Following are the SRE Challenges:
Reliability—Maintenance of a high network level and application availability.
Monitoring—Implement performance metrics and establish distinctive marks to check the systems.
Warning—Easily recognizable any issues and ensure that there is a closed loop support process to solve them.
8) What is the critical aspect of SRE?
SRE takes the work that operations teams have previously done, often manually, not automatically, and gives them to engineers or operations teams who use software and automation methods to solve issues and manage production systems. SRE is a crucial practice when producing capable and highly reliable software systems.
9) What is the goal of SRE?
Site Reliability Engineering (SRE) is a practice that applies both software development skills and mindset to IT operations. The goal of SRE is to improve the reliability of high-scale systems, and this is done through automation and continuous integration and delivery.
10) Difference between TCP/UDP.
TCP
UDP
Reliable
Unreliable
Ordered
Unordered
Heavyweight
Lightweight
Connected
Connectionless
State Memory
Stateless
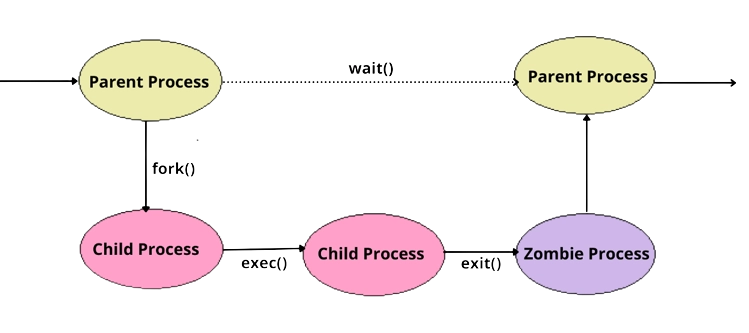
11) How does the process become a zombie process?
Zombie processes are those whose execution is completed but still has an entry in the process table. This can happen when the parent is not executing the wait() system call after forking.
12) What is the difference between DevOps and SRE?
DevOps focuses on bridging the gap between development and operations to ensure smooth software delivery, while SRE (Site Reliability Engineering) emphasizes the reliability of systems through automation, monitoring, and proactive troubleshooting. SRE often involves more metrics-driven decision-making, particularly around error budgets and service-level objectives (SLOs), whereas DevOps focuses on the continuous delivery pipeline.
13) Explain the concept of error budgets in SRE.
An error budget defines the acceptable amount of downtime or errors for a service over a certain period. It's based on service-level objectives (SLOs) and balances the need for system reliability with the need for innovation and change. If the error budget is exhausted, development slows down to focus on improving reliability. This approach ensures that the system remains stable while allowing room for growth and innovation.
14) What is a service-level objective (SLO)?
A service-level objective (SLO) is a specific target for system reliability or performance that must be achieved. For instance, an SLO could be that 99.9% of requests must succeed over a month. SLOs help define the acceptable level of reliability for users, and meeting these objectives is critical in ensuring that service-level agreements (SLAs) are honored.
15) What are service-level indicators (SLIs)?
Service-level indicators (SLIs) are metrics used to measure the performance or reliability of a service. These could include metrics like response time, error rate, and system uptime. SLIs provide insight into whether a system is meeting its service-level objectives (SLOs), thus giving actionable data to maintain reliability.
16) How do you prevent burnout in an SRE role?
Burnout can be a serious concern in SRE roles due to the constant monitoring and responsibility for uptime. Preventive measures include automating repetitive tasks, setting clear expectations about work-life balance, rotating on-call duties, and maintaining realistic error budgets. Regular communication and stress management techniques are also vital in preventing burnout.
17) What is the importance of monitoring in SRE?
Monitoring in SRE is crucial because it helps track system performance, detect issues early, and ensure that the service-level objectives (SLOs) are met. By implementing effective monitoring, SRE teams can proactively address incidents before they become critical and can make data-driven decisions to improve system reliability.
18) What is a runbook, and why is it important in SRE?
A runbook is a document that provides step-by-step instructions for handling system operations, especially during incidents. Runbooks help streamline the response process and ensure that even junior engineers can handle outages or performance issues effectively, reducing downtime and minimizing errors.
19) What is the role of automation in SRE?
Automation is a key component of SRE, aimed at reducing human errors, minimizing toil, and increasing system reliability. SRE teams often automate repetitive tasks like deployments, incident response, and monitoring setups. This allows teams to focus on more complex problem-solving and innovation while maintaining system stability.
20) Explain the term "Toil" in SRE.
“Toil” in SRE refers to manual, repetitive work that tends to be tedious and not directly related to system improvement. This could involve tasks like manual scaling, log analysis, or repetitive monitoring. Reducing toil through automation is a key objective in SRE to improve efficiency and allow more focus on creative problem-solving.
SRE(Site Reliability Engineer) Interview Questions and Answers for Experienced
21) Define the Error budget policy.
An error budget policy explains how a business makes decisions to trade off reliable work instead of another featured work when SLO indicates a service is not reliable enough.
22) What are Error Budgets? And for what error budgets are used?
Error budget describes the time a technical system can collapse without prescribed effects.
Error budget motivates the teams to minimize actual incidents and maximize innovation by taking risks within acceptable limits.
23) How do you calculate budget errors in SRE?
An error budget is one minus the SLO of the service. A 99.9% SLO service has a 0.1% error budget. If our service receives 1,000,000 requests in four weeks, a 99.9% availability SLO gives us a budget of 1,000 errors over that period.
24) Explain the fundamental difference between atime, mtime, and time.
atime described when someone accessed a file for the last time. For example, if you opened the file to view it.
mtime tells when someone has modified a file for the last time. For example- someone has changed some of the texts in the file if it's a text(.txt) file.
time tells when the inode contents of a file were changed, for instance, the mode or owner.
25) What is the fundamental difference between a process and a thread?
A thread is also a kind of process. But it is a lightweight process. Each process has a distinct heap, text, data, and stack. Threads have their stack but share data, heap, and text with the process. Text is the actual set of instructions; data is the input to the program, and the heap is the memory that stores files, locks, and sockets.
26) Explain Data Structure. Name some data structures.
The data structure is a framework for organizing, managing, and storing data, making it easy to access and modify. A data structure is a grouping of data values with the connections between them and the functions or operations that may be performed on the data.
Here is a list of various data structure types:
Linear: Arrays, lists
Tree: Binary, heaps
Graphs: Decision, Acyclic, etc
Hash: Distributed hash table, hash tree, etc
27) How character device and a block device are distinguished from each other?
Block devices are generally buffered and read/written in fixed sizes, such as hard drives and cd-roms. Characters' devices read/write one character at a time, such as from a keyboard or a tty, and are not buffered.
28) What is a zombie process?
A zombie process is a type of process that has completed execution. But still, its entry is present in the process table that allows the parent to read the child's exit status. The process became a zombie since its parent hasn't "reaped" it yet, even though it is "dead."
To read the child's exit status, parent processes often send the wait system call. After which the zombie is eliminated.
The zombie process is not affected by the kill command. A SIGCHLD signal is sent to the parent after a child passes away. Except the minimal amount of space they occupy when they appear in the process id table, zombie processes do not consume any system resources.
29) What is proc in file system?
In a Linux-based operating system, /proc is a special virtual filesystem that provides an interface to kernel data structures and system information. It doesn't contain regular files but rather exposes information about processes, system resources, hardware configuration, and more in a hierarchical structure. It allows users and processes to read and sometimes write to kernel data structures, providing insight into the system's state and enabling system monitoring and debugging.
30) What is DHCP, and for what is it used?
A DHCP server assigns each device in the network a dynamic IP address. Other network configuration parameters to communicate with other IP networks. DHCP is a network management protocol used on Internet Protocol (IP) networks.
Few used DHCP servers are as follows:
Automatically asking the Internet service provider for IP addresses and networking parameters (ISP)
Reducing the need for a network administrator or user to assign IP addresses to all network devices manually.
31) What are the Linux kill commands? Enlist all the Linux kill commands with their functions
In Linux, the kill command is used to terminate processes. Here are some common variations of the kill command:
kill - Sends a signal to a process. By default, it sends the SIGTERM signal, which is a graceful termination request.
kill -9 or kill -SIGKILL - Sends the SIGKILL signal to a process, forcing it to terminate immediately. This signal cannot be caught or ignored by the process.
killall - Terminates all processes with the specified name. It's useful when multiple instances of a process need to be stopped.
pkill - Terminates processes based on criteria such as process name, user, group, or other attributes.
32) How do you apply OOPs principles in server design?
Applying Object-Oriented Programming (OOP) principles in server design involves structuring the codebase around objects and classes to promote modularity, reusability, and maintainability. Here's how OOP principles can be applied:
Encapsulation: Encapsulate data and functionality within objects to hide implementation details and expose only necessary interfaces.
Inheritance: Utilize inheritance to create hierarchies of classes, promoting code reuse and facilitating polymorphism.
Polymorphism: Implement polymorphism to enable objects of different classes to be treated uniformly through interfaces and inheritance.
Abstraction: Abstract complex functionalities into class interfaces, allowing clients to interact with objects without needing to know their internal implementations.
33) Describe CDN and its uses?
Content Delivery Network (CDN) is a distributed network of servers strategically located across different geographical regions. Its uses include:
Content Distribution: CDN caches content, such as web pages, images, videos, and other static files, closer to end-users, reducing latency and improving load times.
Load Balancing: CDN distributes incoming traffic across multiple servers, balancing the load and preventing server overload.
Security: CDNs often provide security features, such as DDoS protection and Web Application Firewall (WAF), safeguarding websites and applications against cyber threats.
Global Scalability: CDN allows websites and applications to scale globally without the need for significant infrastructure investment, ensuring consistent performance across different regions.
34) Explain the term SLO?
Service Level Objective (SLO) is a key performance indicator that defines the reliability and availability goals of a service. It represents a target level of performance that a system aims to achieve within a specific time frame. SLOs are typically defined based on metrics such as uptime, response time, and error rate.
35) Define Service Level Indicators
A Service Level Indicator (SLI) is a way to gauge how well a service provider is serving a client. SLOs, in turn, serve as the foundation for SLAs, which serve as the foundation for SLAs (SLAs). An SLA metric is another name for an SLI.
Although the services offered by each system vary, common SLIs are used quite frequently. Other SLIs include:
Durability (in storage systems).
End-to-end latency (for complicated data processing systems, notable pipelines).
Correctness.
Common SLIs include latency, throughput, availability, and error rate.
36) What do you mean by TCP?
TCP stands for Transmission Control Protocol. It is a connection-oriented protocol used in computer networks for reliable and ordered delivery of data between devices. TCP provides features such as error checking, flow control, and congestion control to ensure that data packets are transmitted and received accurately and efficiently.
37) What is TCP best used for?
TCP is best used for applications that require reliable, ordered, and error-checked delivery of data, such as web browsing, email communication, file transfer (FTP), remote access (SSH), and online gaming. TCP ensures that data sent from one device is received accurately and in the correct order by the receiving device.
38) Explain iNodes?
Inodes, short for index nodes, are data structures used in Unix-like file systems to represent files and directories. Each file or directory on the file system is associated with an inode, which stores metadata about the file or directory, such as its permissions, ownership, size, and location on disk. Inodes also contain pointers to the data blocks where the actual file contents are stored.
39) What is an SLA(Service-Level Agreement)?
A Service-Level Agreement (SLA) is a contract between a service provider and a customer that defines the expected level of service quality, including performance metrics, uptime guarantees, response times, and penalties for failing to meet the agreed-upon service levels. SLAs help ensure accountability and establish clear expectations between parties.
40) What is SNAT and DNAT in networking?
SNAT (Source Network Address Translation) and DNAT (Destination Network Address Translation) are techniques used in computer networking to modify the source and destination IP addresses of packets as they pass through a network device, such as a router or firewall. SNAT changes the source IP address of outgoing packets, while DNAT changes the destination IP address of incoming packets, allowing for routing and security enhancements.
41) What do you mean by virtualization?
Virtualization is the process of creating virtual instances of computer hardware, software, storage, or network resources. It allows multiple virtual machines (VMs) or containers to run on a single physical server, enabling greater resource utilization, flexibility, and scalability. Virtualization abstracts physical hardware, allowing for the efficient allocation and management of computing resources.
42) What is a container on server?
A container on a server is a lightweight, portable, and isolated environment that encapsulates an application and its dependencies, enabling it to run consistently across different computing environments. Containers share the host operating system's kernel and resources, making them more efficient than traditional virtual machines. Containers provide a standardized and efficient way to package, deploy, and manage applications in a variety of environments.
43) Explain when you would use a hardlink instead of softlink?
Because changing the source does not delete the hardlink relationship. A hard link is helpful when the source file is moving about. On the other hand, a weak link is broken if the source is changed to a soft link. This is because softlink uses the source filename in its data section, hardlink shares the same inode.
44) How will you secure your Docker containers?
You must adhere to the following rules to secure your Docker container:
Choose third-party containers carefully
Enable Docker content trust
Set resource limits for your containers
Consider a third-party security tool
Use Docker Bench Security
45) Discuss the Best SRE Tools you know for each Stage/Level of DevOps.
The following SRE tools are suitable for each DevOps stage:
Create: Source-control tools like GitHub
Plan: Pivotal, Jira, Tracker, and other task management tools
Package: Container orchestration services like Mesosphere or Kubernetes.
Verify: CI/CD tools like CircleCI or Jenkins
Configure: Tools like Ansible and Terraform
46) What is observability, and how to enhance organizations' systems observability?
Observability is essentially a discussion of how to measure and use an organization.
To enhance an organization's observability, you need to:
Discover how your strategy makes sense of the data by distilling, filtering, and transforming it into valuable insights about the performance of your systems. Gain a clear understanding of what matters to a team.
Recognize the many data kinds that come from an environment and determine which of them are pertinent to and valuable for your observability goals.
Observability provides potentially helpful hints regarding the DevOps maturity level of an organization.
47). Write a Python program to check if a given number is prime.
This program uses a simple loop to check if a number is prime by testing divisibility. It runs efficiently by checking divisors up to the square root of the number.
def is_prime(num):
if num <= 1:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
number = int(input("Enter a number: "))
print(f"{number} is prime") if is_prime(number) else print(f"{number} is not prime")
48). Write a function to reverse a linked list in Python.
This function reverses a linked list by adjusting the pointers iteratively. It runs in O(n) time, where n is the length of the linked list.
class Node:
def __init__(self, data):
self.data = data
self.next = None
def reverse_linked_list(head):
prev = None
current = head
while current:
next_node = current.next
current.next = prev
prev = current
current = next_node
return prev
49). Write a Python program to implement a basic queue using lists.
This code implements a basic queue using Python lists, where elements are added to the end and removed from the front.
class Queue:
def __init__(self):
self.queue = []
def enqueue(self, item):
self.queue.append(item)
def dequeue(self):
if not self.is_empty():
return self.queue.pop(0)
return "Queue is empty"
def is_empty(self):
return len(self.queue) == 0
q = Queue()
q.enqueue(10)
q.enqueue(20)
print(q.dequeue()) # Outputs: 10
50). Write a function to find the maximum element in an array.
This function iterates through an array and returns the maximum element. It operates with a time complexity of O(n).
def find_max(arr):
max_val = arr[0]
for num in arr:
if num > max_val:
max_val = num
return max_val
arr = [10, 20, 30, 40, 50]
print(f"The maximum element is: {find_max(arr)}")
51). Write a Python function to sort an array using bubble sort.
Bubble sort repeatedly swaps adjacent elements if they are in the wrong order. Though simple, its time complexity is O(n^2), making it inefficient for large datasets.
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("Sorted array is:", arr)
52). Write a Python function to check for balanced parentheses in an expression.
This function checks for balanced parentheses using a stack. It returns True if all parentheses are balanced and False otherwise.
def is_balanced(expression):
stack = []
pairs = {')': '(', '}': '{', ']': '['}
for char in expression:
if char in "({[":
stack.append(char)
elif char in ")}]":
if not stack or stack.pop() != pairs[char]:
return False
return not stack
53). Implement a basic stack in Python.
This code implements a stack, where elements are added and removed from the top. The stack follows a LIFO (Last In, First Out) structure.
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
def pop(self):
if not self.is_empty():
return self.stack.pop()
return "Stack is empty"
def is_empty(self):
return len(self.stack) == 0
s = Stack()
s.push(1)
s.push(2)
print(s.pop()) # Outputs: 2
54). Write a Python function to merge two sorted arrays.
This function merges two sorted arrays in O(n+m) time, where n and m are the sizes of the input arrays.
def merge_arrays(arr1, arr2):
result = []
i = j = 0
while i < len(arr1) and j < len(arr2):
if arr1[i] < arr2[j]:
result.append(arr1[i])
i += 1
else:
result.append(arr2[j])
j += 1
result.extend(arr1[i:])
result.extend(arr2[j:])
return result
arr1 = [1, 3, 5]
arr2 = [2, 4, 6]
print(merge_arrays(arr1, arr2))
SRE MCQ Questions
1) What is the main goal of SRE?
A) Increase system complexity
B) Enhance system reliability
C) Focus on manual processes
D) Reduce automation Answer: B) Enhance system reliability
2) Which metric defines the acceptable level of system reliability?
A) SLA
B) SLO
C) SLI
D) KPI Answer: B) SLO
3) What is the role of error budgets in SRE?
A) To prevent changes
B) To allow more system errors
C) To balance reliability with innovation
D) To increase downtime Answer: C) To balance reliability with innovation
4) Which of the following is a key SRE tool for monitoring systems?
A) Docker
B) Kubernetes
C) Prometheus
D) Jenkins Answer: C) Prometheus
5) What is an important SRE practice to reduce toil?
A) Increase human intervention
B) Automate repetitive tasks
C) Focus on manual scaling
D) Disable monitoring tools Answer: B) Automate repetitive tasks
6) What is the primary responsibility of an SRE?
A) Writing application code
B) Ensuring system reliability
C) Managing marketing campaigns
D) Reducing system performance Answer: B) Ensuring system reliability
7) Which tool is commonly used for container orchestration in SRE?
A) Ansible
B) Terraform
C) Kubernetes
D) Nagios Answer: C) Kubernetes
8) What does SLI stand for in the context of SRE?
A) System-Level Integration
B) Service-Level Indicator
C) Software-Level Indicator
D) Service-Line Integration Answer: B) Service-Level Indicator
9) In SRE, what is a runbook used for?
A) Developing new features
B) Automating code deployment
C) Documenting incident response procedures
D) Monitoring system performance Answer: C) Documenting incident response procedures
10) What is a key benefit of automation in SRE?
A) Increased system complexity
B) Reduced human error
C) Manual intervention
D) Delayed system response Answer: B) Reduced human error
Conclusion
This article explores a variety of SRE interview questions for freshers and experienced candidates. The freshers section consists of fundamental concepts essential for newcomers to the field, while the experienced section delves deeper into advanced topics that evaluate your technical expertise. By preparing with these questions, you'll strengthen your interview skills and demonstrate a solid understanding of site reliability engineering principles.






























 9+ registered
9+ registered 

