


























Introduction
Before going on to the main topic, let us briefly discuss generative adversarial networks (GAN). Generative Adversarial Network (GAN) is composed of two models that are trained to compete with each other alternatively. The generator G is optimized to replicate the true data distribution pdata by creating difficult pictures for discriminator D to distinguish from genuine images. Meanwhile, D is optimized to differentiate between real images and fake images generated by Generator(G). The training process is similar to a two-player min-max game with the following objective function,
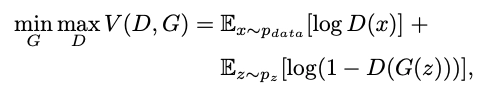
where x is a real image from the true data distribution pdata, and z is a noise vector sampled from distribution pz (e.g., uniform or Gaussian distribution).
StackGAN
The main idea behind stackGAN is to train a model in such a way that it should be able to generate images with the text description.
The stacked generative adversarial network, or stackGAN, is a GAN variant that uses a hierarchical stack of conditional GAN models to produce images from text.
Also see, Spring Boot Architecture
Architecture of StackGAN
We propose a basic yet effective two-stage generative adversarial network stackGAN, to generate high-resolution photos with photorealistic features. It divides the text-to-image generative process into two steps, as shown in the figure below.
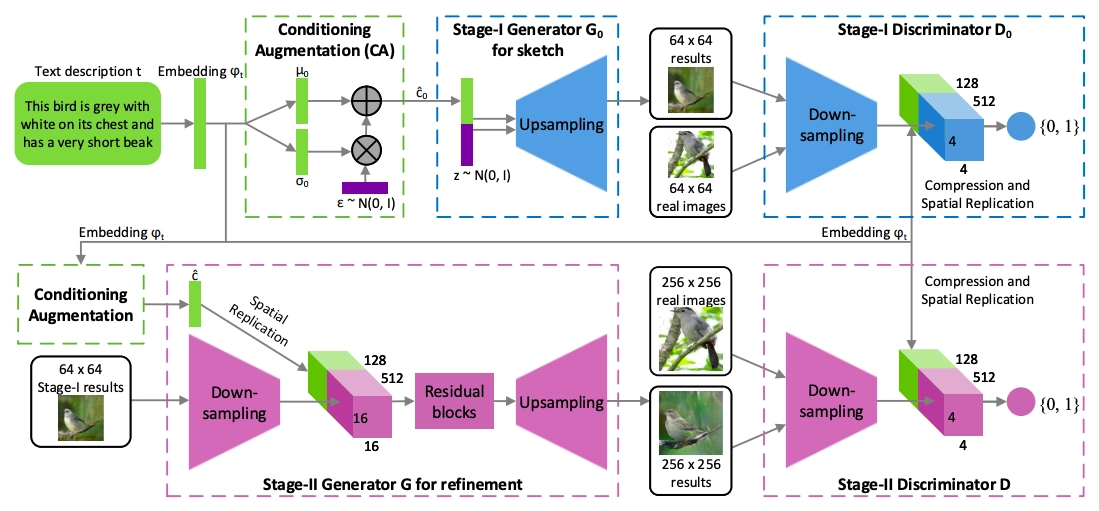
The model architecture of stack GAN consists of the following components.
- Embedding: Converts the input variable length text into a fixed-length vector. we will be using a pre-trained character level embedding.
- Conditioning Augmentation (CA)
- Stage I Generator: Generates low resolution (64*64) images.
- Stage I Discriminator
- Residual Blocks
- Stage II Generator: Generates high resolution (256*256) images.
- Stage II Discriminator
Embedding
While feeding data to a neural network, mapping all the words to some specific numbers is necessary, as neural networks cannot understand the language of ordinary humans.
Word embedding is a technique to represent the word with the vector of numbers. In simple terms, word embedding means text as numbers. To know more about embedding, refer to this blog.
Conditioning Augmentation
As shown in the above figure, the text description t is first encoded by an encoder, yielding a text embedding Ѱt. In previous works, the text embedding is nonlinearly transformed to generate latent conditioning variables as the input of the generator. However, latent space for the text embedding is usually of higher dimensions (greater than 100). It usually causes irregularity in the latent data manifold with a limited amount of data, which is not profitable for learning the generator. To solve this problem, we introduce a Conditioning Augmentation technique to produce additional conditioning variables ĉ. The proposed Conditioning Augmentation yields more training pairs given a small number of image-text pairs and thus encourages robustness to small perturbations along the conditioning manifold.
Stage 1
We simplify the work by first generating a low-resolution image with our Stage-I GAN, which focuses on drawing only the rough shape and correct colors for the object, rather than directly generating a high-resolution image conditioned on the text description.
Stage 2
Stage 1 GAN images with low resolution sometimes lack bright object elements and may have shape distortions. In the first stage, some text details may be deleted, which is crucial for creating photo-realistic graphics. To produce high-resolution images, our Stage 2 GAN is based on Stage 1 GAN results. To remedy faults in Stage 1 results, it is conditioned on low-resolution photos as well as text embedding. The Stage 2 GAN fills gaps in previously ignored text data, resulting in more photo-realistic features.
Residual Blocks
A residual block is a collection of layers in which the output of one layer is taken and added to a layer deeper in the block. After that, the nonlinearity is applied by combining it with the output of the relevant layer in the main path.


 8+ registered
8+ registered 

