Do you think IIT Guwahati certified course can help you in your career?
Introduction
Stacking is an ensemble machine learning technique that allows combining different prediction models to make a single model that make the final prediction out of the provided dataset.
What is Ensemble Learning in Machine Learning?
Ensemble learning is a technique in machine learning that combines multiple models to improve predictive performance. By aggregating the outputs of various algorithms, such as decision trees or neural networks, ensemble methods reduce the risk of overfitting and enhance accuracy, leading to more robust and reliable predictions.
What is Stacking in Machine Learning
Stacking, or stacked generalization, is an ensemble learning technique that involves training multiple base models to make predictions and then using another model, called a meta-model, to combine these predictions. The meta-model learns how to weigh the outputs of the base models optimally, improving overall prediction accuracy. Stacking can handle various algorithms and is effective in leveraging their individual strengths for better results.
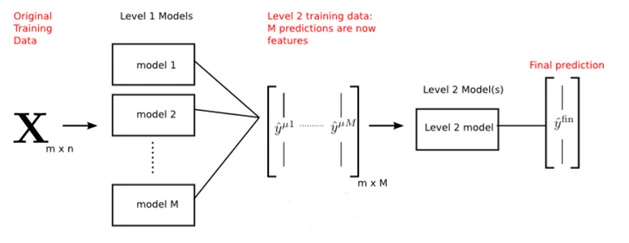
Architecture of a Stacking Model
The above figure is the exact architecture of stacking
The details of the figure are as follow.
the dataset has m rows and n columns which are m data points with n features per datapoints.
There are M different models with different functions that work on X training dataset in the mode of K-folds.
Each model provides prediction which is then provided to the second level training and this data has a dimension of m x M, that is m rows which is the number of data points and M columns which is the number of features which is the output of M base models.
Level-2 model will be trained on the data produced by the base-model dataset in order to produce the final result. This level-2 model is also referred to as a meta-model.
Steps to Implement Stacking Models
Select Base Models: Choose a diverse set of base models (e.g., logistic regression, decision trees, SVM) to capture different patterns in the data.
Train Base Models: Fit each base model on the training dataset, ensuring they learn to make predictions independently.
Generate Meta-Features: Use the predictions from the base models as input features for the meta-model. This often involves generating predictions on the training set and possibly on a validation set using cross-validation.
Select and Train Meta-Model: Choose a meta-model (e.g., a logistic regression or another algorithm) and train it on the generated meta-features to combine the predictions of the base models effectively.
Evaluate the Ensemble Model: Test the performance of the stacking ensemble on a separate test dataset, comparing its accuracy and other metrics against individual base models to assess improvement.
Implementing Classification with Stacking
Here’s a Python implementation of stacking for a classification problem using the scikit-learn library. In this example, we will use the Iris dataset for simplicity.
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.base import BaseEstimator, ClassifierMixin
# Load dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define base models
base_models = [
RandomForestClassifier(n_estimators=100, random_state=42),
GradientBoostingClassifier(n_estimators=100, random_state=42)
]
# Create a function to generate meta-features
def get_meta_features(X_train, y_train, X_test, models):
meta_train = np.zeros((X_train.shape[0], len(models)))
meta_test = np.zeros((X_test.shape[0], len(models)))
kf = KFold(n_splits=5)
for i, model in enumerate(models):
for train_index, val_index in kf.split(X_train):
X_fold_train, X_fold_val = X_train[train_index], X_train[val_index]
y_fold_train, y_fold_val = y_train[train_index], y_train[val_index]
model.fit(X_fold_train, y_fold_train)
meta_train[val_index, i] = model.predict(X_fold_val)
model.fit(X_train, y_train)
meta_test[:, i] = model.predict(X_test)
return meta_train, meta_test
# Generate meta-features
meta_train, meta_test = get_meta_features(X_train, y_train, X_test, base_models)
# Define the meta-model
meta_model = LogisticRegression()
# Train the meta-model
meta_model.fit(meta_train, y_train)
# Make predictions
final_predictions = meta_model.predict(meta_test)
# Evaluate the model
accuracy = accuracy_score(y_test, final_predictions)
print(f'Accuracy of the Stacked Model: {accuracy:.2f}')
Output
When you run the above code, you should see an output similar to this, indicating the accuracy of the stacked model:
Accuracy of the Stacked Model: 1.00
Stacking in Regression
Regression is basically a representation of a set of independent quantity on a unit dependent quantity, that dependent quantity in machine learning is our output value produced from the set of input that is independent values or records.
The main algorithms that can be used for Regression are Linear Regression, Support Vector Machine, Decision Tree, k-nearest Neighbours all these algorithms can be used for the base model of stacking technique, the output from base models can be feed to the meta-model in order to obtain the final real value term that satisfies the relationship between the dependent and independent data of provided dataset.
Using a Stacking score of individual Regression algorithms can be identified on the basis of that it will be easy of select which algorithms need to be added in our combined layer-0 which will deal with raw portions of datasets and their input will be feed to meta-model for final prediction of real value.
Steps in which stacking works In order to work with stacking we need to follow its architecture in proper way.
First, the complete data is divided into test and train using train_test_split from model_selection.
Now the training data is divided using K-folds, these K-folds are mostly used for validation purpose and this can be said that they work as k-fold cross-validation.
Now the base model is fit on a certain portion of the dataset or it can be said that model is going to be fit on one of the folds of the dataset and then the prediction is made for the validation part od that portion of the dataset.
The base model is now used to fit on a complete dataset in order to calculate the performance to test set.
Above step from 2-3 is repeated for other base models to check for the efficiency of a complete model.
Predictions are obtained from each base model and these predictions are used as the features for the meta-model for final prediction.
The metamodel is used to obtain the final prediction on the test data of train_test_split.
Commonly Used Ensemble Techniques Related to Stacking
Bagging: Involves training multiple models independently on random subsets of the data, then averaging their predictions to reduce variance, such as in Random Forests.
Boosting: Sequentially trains models where each new model focuses on the errors made by previous ones, improving overall performance, as seen in AdaBoost and Gradient Boosting.
Blending: Similar to stacking, blending combines predictions from different models but typically uses a holdout validation set instead of cross-validation to train the meta-learner.
Voting: Involves combining the predictions of multiple models by majority voting (for classification) or averaging (for regression) to enhance accuracy.
Training a Meta-Learner on Stacked Predictions
Training a meta-learner on stacked predictions involves using the outputs of base models as input features for the meta-model. After generating meta-features from cross-validated predictions of base models, the meta-learner learns to weigh these predictions optimally. This process allows the ensemble to leverage the strengths of each base model, ultimately improving the overall predictive performance.
Frequently Asked Questions
What types of models can be used as base models in stacking?
Stacking can utilize a variety of base models, including decision trees, support vector machines, neural networks, and ensemble methods like random forests and gradient boosting. The key is to choose diverse models that capture different patterns in the data.
How does stacking improve model performance compared to individual models?
Stacking enhances model performance by combining the strengths of multiple models while mitigating their weaknesses. The meta-learner learns to weigh the predictions of base models optimally, which can lead to better generalization and reduced overfitting compared to using a single model.
Is stacking suitable for all types of datasets?
While stacking can improve performance across many datasets, its effectiveness depends on the nature of the data and the base models chosen. For small or simple datasets, the additional complexity of stacking might not yield significant benefits and could even lead to overfitting.
Conclusion
In this article, we have discussed Stacking in Machine Learning. Incorporating stacking into machine learning significantly enhances predictive performance by effectively leveraging the strengths of multiple models. By combining diverse algorithms and training a meta-learner on their predictions, stacking reduces errors and increases accuracy. Understanding and implementing stacking can empower data scientists to build more robust models, ultimately leading to improved outcomes in various applications, from classification to regression tasks.






























 8+ registered
8+ registered 

