Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hashing is converting an input of any size into a fixed-size number or String using algorithms.
In hashing, the thought is to utilize a hash work that changes a given key over to a more modest number and uses the fair number as a record in a hash table.
Why do we use String Hashing?
Hashing calculations are useful in taking care of a large number of issues.
We need to take care of the issue of contrasting strings productively. The savage power method of doing so is to think about the letters of the two strings, which has a period intricacy of O(min(n1,n2)) if n1 and n2 are the measures of the two strings. We need to improve. The thought behind strings is the accompanying: we convert each String into a number and think about those rather than the strings. Contrasting two strings is then an O(1) activity.
For the change, we need a purported hash work. Its objective is to change over a string into a whole number, the purported Hash of the String. The accompanying condition needs to hold: on the off chance that two strings s and t are equivalent (s=t), likewise, their hashes must be identical (hash(s)= Hash (t)). If not, we can not look at strings.
Notice, the other way doesn't need to hold. Assuming the hashes are equivalent (hash(s)= Hash (t)), the strings don't need to be comparable. For example, a substantial hash capacity would be just Hash (s)=0 for every s. Presently, this is only a dumb model since this capacity will be futile, yet it is a substantial hash work. The motivation behind why the other way doesn't need to hold is because there are dramatically many strings. If we just need this hash capacity to recognize all strings comprising of lowercase characters of length more modest than 15, then, at that point, currently the Hash wouldn't squeeze into a 64-bit whole number (for example, unsigned long) anymore, because there are such large numbers of them. Furthermore, we would prefer not to analyze long discretionary numbers since this will likewise have the intricacy O(n).
So ordinarily, we need the hash capacity to plan strings onto quantities of a decent reach [0,m); then, at that point, looking at strings is only an examination of two numbers with a proper length. Also, we need Hash (s)≠hash(t) to be possible if s≠t.
That is the significant part that you need to remember. Utilizing hashing won't be 100% deterministically right since two various complete strings may have a similar hash (the hashes impact). In any case, this can be securely disregarded in a wide more significant part of undertakings as the likelihood of the hashes of two unique strings impacting is still tiny. Furthermore, we will talk about specific procedures in this article more straightforward to keep the possibility of impacts shallow.
The tremendous and generally utilized approach to characterize the Hash of a string s of length n is :
Where p and m are some picked, positive numbers, it is known as a polynomial moving hash work.
It is sensible to make p an indivisible number generally equivalent to the number of characters in the information letters in order. For instance, if the info is made out of just lowercase letters of the English letters in order, p=31 is a decent decision. On the off chance that the info might contain both capitalized and lowercase letters, p=53 is a potential decision. The code in this article will utilize p=31.
Clearly, m ought to be an enormous number since the likelihood of two irregular strings impacting is about ≈1m. Now and again, m=264 is picked; from that point forward, the number floods of 64-digit numbers work precisely like the modulo activity. In any case, a technique exists that creates impacting strings (which work freely from the decision of p). So by and by, m=264 isn't suggested. A decent decision for 'm' is some enormous indivisible number. The code in this article will simply utilize m=109+9. This is a vast number yet at the same time little enough so we can perform an increase of two qualities using 64-bit whole numbers.
Here is an instance of ascertaining the Hash of a string s, which contains just lowercase letters. We convert each character of s to a number. Here we utilize the transformation a→1, b→2, …, z→26. Changing over a→0 is anything but a smart thought, then the hashes of the strings a, aa, aaa, … all assess to 0.
Psedo_Code:
longlongclaculate_hash(stringconst& s) { int p = 31; int m = 1e9 + 9; longlong hashing_value = 0; longlong power_p = 1; for (char c : s) { hash_value = (hashing_value + (c - 'a' + 1) * power_p) % m; power_p= (power_p * p) % m; } return hashing_value; }
Various Task of String Hashing:
Various Tasks on String Hashing is:
1:-Searching for Duplicate String in Array:
Issue: Given a rundown of n strings si, each no longer than m characters, track down every one of the copy strings and separate them into gatherings.
From the undeniable calculation, including arranging the strings, we would get a period intricacy of O(n*m*log(n)) where the arranging requires O(n*log N) examinations and every correlation take O(m) time. Notwithstanding, by utilizing hashes, we decrease the correlation time to O(1), giving us a calculation that runs in O(nm+nlogn) time.
We work out the Hash for each String, sort the hashes along with the files, and afterwards bunch the records by indistinguishable hashes.
Pseudo code:-
vector<vector<int>> identical_group_strings(vector<string> const& s) { int n = s.size(); vector<pair<longlong, int>> hash_vector(n); for (int i = 0; i < n; i++) hash_vector[i] = {compute_hash(s[i]), i};
sort(hash_vector.begin(), hash_vector.end());
vector<vector<int>> group_s; for (int i = 0; i < n; i++) { if (i == 0 || hash_vector[i].first != hash_vector[i-1].first) group_s.emplace_back(); groups.back().push_back(hash_vector[i].second); } return group_s; }
2:- Fast hashing calculation of substring of a string given
Issue: Given a string s and lists I and j, discover the hash of the substring s[i… j].
Source : https://cp-algorithms.com/
So by realizing the hash worth of each prefix of the string s, we can register the hash of any substring straightforwardly utilizing this recipe. The main issue that we face in ascertaining it is that we should have the option to partition hash(s[0… j])−hash(s[0… i−1]) by pi. Accordingly, we need to track down the particular multiplicative backwards of pi and afterwards increase with this converse. We can precompute the backwards of each pi, which permits processing the hash of any substring of s in O(1) time.
Nonetheless, there exists a simpler way. As a rule, instead of working out the hashes of substring precisely, it is sufficient to register the hash duplicated by some force of p. Assume we have two hashes of two substrings, one increased by pi and the other by PJ. Assuming i<j, we duplicate the principal hash by pj−i, in any case, we increase the second hash by pi−j. By following this, we get both the hashes increased by an equal force of p (which is the limit of I and j) and presently, these hashes can measure up effectively with no requirement for any division.
Application of Hashing:
Here are some common uses of Hashing:
Rabin-Karp calculation for design coordinating in a string in O(n) time.
Ascertaining the number of various substrings of a string in O(n2logn) (see underneath).
It is ascertaining the number of palindromic substrings in a string.
Finding the no of different substrings in a string:
Issue: Given a string s of length n, comprising just of lowercase English letters, track down the number of various substrings in this string.
To take care of this issue, we repeat overall substring lengths l=1… n. For each substring length l, we develop a variety of hashes of all substrings of length l increased by a similar force of p. The quantity of various components in the cluster is equivalent to the number of unmistakable substrings of length l in the string. This number is added to the last reply.
For accommodation, we will utilize h[i] as the hash of the prefix with I characters and characterize h[0]=0.
Pseudo code:
intno_of_unique_substrings(stringconst& s) { int n = s.size();
int p = 31; int m = 1e9 + 9; vector<longlong> power_p(n); power_p[0] = 1; for (int i = 1; i < n; i++) power_p[i] = (power_p[i-1] * p) % m;
vector<longlong> h(n + 1, 0); for (int i = 0; i < n; i++) h[i+1] = (h[i] + (s[i] - 'a' + 1) * power_p[i]) % m;
int cnt = 0; for (int l = 1; l <= n; l++) { set<longlong> hs; for (int i = 0; i <= n - l; i++) { longlong cur_h = (h[i + l] + m - h[i]) % m; cur_h = (cur_h * power_p[n-i-1]) % m; hs.insert(cur_h); } cnt += hs.size(); } return cnt; }
Frequently the previously mentioned polynomial hash is adequate, and no crashes will occur during tests. Keep in mind, the likelihood that impact happens is just ≈1m. For m=109+9, the possibility of helpful information; in is ≈10−9, which is very low. In any case, notice that we just did one examination. Imagine a scenario where we contrasted a string s and 106 unique strings. The likelihood that something like one impact happens is presently ≈10−3. What's more, assuming we need to contrast 106 unique strings and one another (for example, by counting the number of one of a kind strings that exists), then, at that point, the likelihood of somewhere around one impact happening is as of now ≈1. It is essentially ensured that this undertaking will end with a consequence and returns some unacceptable outcome.
There is a truly simple stunt to improve probabilities. We can simply register two different hashes for each string (by utilizing two unique p and various m) and analyze these sets. In case m is around 109 for every one of the two hash capacities, then this is pretty much comparable to having one hash work with m≈1018. When contrasting 106 strings and one another, the likelihood that somewhere around one impact happens is currently diminished to ≈10−6.
What is Hashing? Hashing is a process of converting an input of any size into a fixed-size number or string using algorithms.
What is String Hashing? String hashing is the best approach to change over a string into a whole number known as a hash of that string.
Why do we use String Hashing? An ideal hashing is the one wherein there are least possibilities of the crash (i.e., in two unique strings having a similar hash).
What is The Time Complexity and Space Complexity of String Hashing? Time complexity: O(N) Space complexity: O(1)
List some applications of Hashing? Rabin-Karp calculation. Counting no of substring possible from the string. (Important) Counting no of palindrome substring
Key Takeaways:
In this blog, we discussed Hashing in the Introduction; then we discussed String Hashing, then we discussed how to compute the hash for the given string then we discussed various applications on it.



























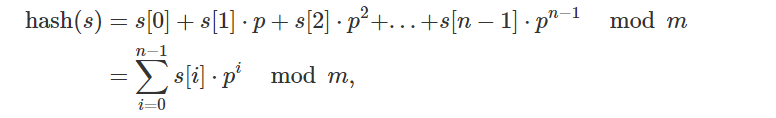
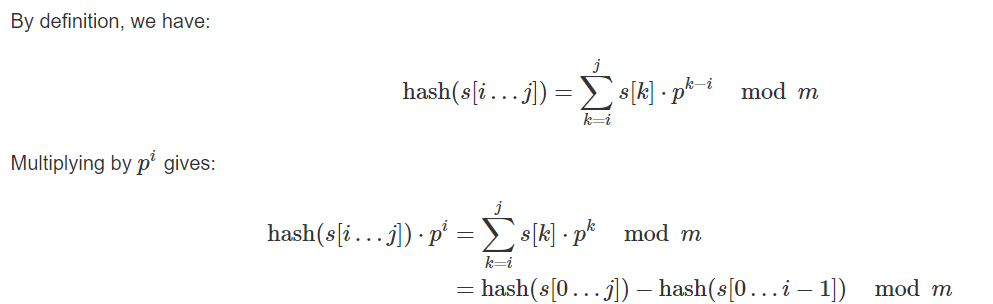

 9+ registered
9+ registered 

