Do you think IIT Guwahati certified course can help you in your career?
Introduction
String searching or matching is you’ll be given a pattern and you have to look for that pattern in the given string if it exists or not. In other words, matching all occurrences of a pattern in a given string but the only thing to keep in mind is that the pattern should be consecutive (substring) in the given string.
What is String matching?
String Matching means to find the occurrence of pattern within another string or text or body. There are many algorithms for performing efficient string matching. String Matching is used in various fields like plagiarism, information security, text mining, etc.
What is Naive String Matching Algorithm?
String Matching Algorithm is an algorithm needed to find a place where particular or multiple strings are found within the larger string. All the alphabets of patterns(searched string) should be matched to the corresponding sequence.
Example: S: a b c d a b g | P: b c d
Now if you look for the pattern “bcd“ in the string then it exists.
There are five major string matching algorithms:
Naïve Algorithm (Brute Force)
KMP Algorithm
Rabin-Karp Algorithm
Z Algorithm
Boyer-Moore String Search Algorithm
But Naïve algorithm is more of a brute force approach rather than an algorithm. It is also simplest among the other algorithms and easy to implement. Although it might be possible that this algorithm doesn’t work every time or for solving problems in competitive programming because of its time complexity but if we don’t think for time complexity and think just for a solution then this is the first thing or a normal approach which would come in mind as the name suggests.
Different Approaches to Follow Naive String Algorithm
Naive Pattern Searching Approach
Alternate Approach - using 2 pointers
Work Mechanism
Pattern and Text: We have a pattern and textual content
Comparison: Start from the start of the text and examine every character with the pattern
Match Check: If the characters match, continue evaluating the next characters in each text and pattern
Mismatch: If there may be a mismatch, one character in advance inside the text and start evaluating from the beginning of the pattern.
Repeat: Keep repeating this system till you discover a match or attain the end of the text.
Result: When a suit is observed, or you look at the textual content, you know whether the pattern exists in the text.
Naive Pattern Searching Approach
Naive Pattern Searching Approach is one of the easy pattern-searching algorithms. All the characters of the pattern are matched to the characters of the corresponding/main string or text. In this approach, we will check all the possible placements of our input pattern with the input text.
Refer to the algorithm below for a better understanding.
Algorithm
There will be two loops: the outer loop will range from i=0 to i≤n-m, and the inner loop will range from j=0 to j<m, where ‘m’ is the length of the input pattern and n is the length of the text string.
Now, At the time of searching algorithm in a window, there will be two cases:
Case 1: If a match is found, we will match the entire pattern with the current window of the text string. And if found the pattern string is found in the current window after traversing, print the result. Else traverse in the next window.
Case 2: If a match is not found, we will break from the loop(using the 'break' keyword), and the j pointer of the inner loop will move one index more and start the search algorithm in the next window.
Code Implementation
The code implementation of the approach for Naive String Matching in C++, Java, and Python language.
C++ Code
#include <bits/stdc++.h>
using namespace std;
void Pattern(string p, string s1, int m, int n) {
for (int i = 0; i <= n - m; i++) {
int j;
for (j = 0; j < m; j++)
if (s1[i + j] != p[j])
break;
if (j == m)
{
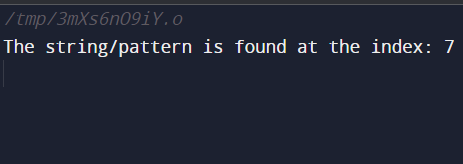
cout << "The string/pattern is found at the index: " << i << endl;
return;
}
}
cout << "Oops!!! No match found!" << endl;
}
int main() {
string s1 = "Coding Ninjas";
string p = "Ninjas";
Pattern(p, s1, p.size(), s1.size());
return 0;
}
You can also try this code with Online C++ Compiler
public class ExamplePattern {
static void Pattern(String p, String s1, int m, int n) {
int i = 0, j = n - 1;
for (i = 0, j = n - 1; j < m;) {
if (s1.equals(p.substring(i, j + 1))) {
System.out.println("The string/pattern is found at the index: " + i);
return;
}
i++;
j++;
}
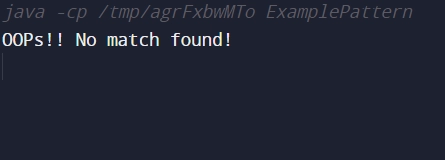
System.out.println("OOPs!! No match found!");
}
public static void main(String[] args) {
String s1 = "Coding Ninjas";
String p = "Hello";
Pattern(p, s1, p.length(), s1.length());
}
}
You can also try this code with Online Java Compiler
def Pattern(p, s1, m, n):
for i in range(n - m + 1):
j = 0
while(j < m):
if (s1[i + j] != p[j]):
break
j += 1
if (j == m):
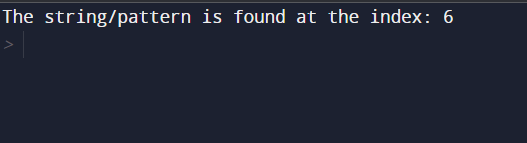
print("The string/pattern is found at the index:", i)
return
print("OOPs!! No match found!")
if __name__ == '__main__':
s1 = "Coder Platform"
p = "Platform"
Pattern(p, s1, len(p), len(s1))
You can also try this code with Online Python Compiler
Naive Pattern Matching using 2 pointers is an effective approach, where the input pattern is matched with the input string or text using 2 pointers. Through this approach we get the information about the repeating mismatched characters present in the next various windows that will help us avoid searching again and again.
Refer to the algorithm below for a better understanding.
Algorithm
The algorithm for this approach is as follows:
Initialize two pointers i and j.
The i pointer will be for the input string and j pointer will be for the input pattern.
Compare the text and the pattern, and keep iterating i and j pointers until both the text and pattern match.
Now when they are not the same:
The character of the pattern from the 0th index to the j-1th index matches with the input text string from the i-j to the i-1 index. Also, pattern 0…j-1 is a proper suffix and prefix.
These two sequences need not always be matched.
Perform the same algorithm for the next window too(For the next window, we already know the proper suffix and proper prefix).
We will store the longest prefix inside a string named ‘longest’ (It is also a suffix), which is why processing becomes easier.
Code Implementation
The code implementation of 2 pointers approaches for Naive String Matching in C++, Java, and Python language.
C++ Code
#include <bits/stdc++.h>
using namespace std;
void Compute(string pattern, int m, int *longest) {
int len = 0;
longest[0] = 0;
int i = 1;
while (i < m) {
if (pattern[i] == pattern[len]) {
len++;
longest[i] = len;
i++;
}
else {
if (len != 0)
len = longest[len - 1];
else {
longest[i] = 0;
i++;
}
}
}
}
void Pattern(string p, string s1, int m, int n) {
int longest[m];
Compute(p, m, longest);
int i = 0;
int j = 0;
while ((n - i) >= (m - j)) {
if (p[j] == s1[i]) {
j++;
i++;
}
if (j == m) {
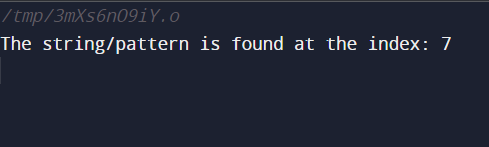
cout << "The string/pattern is found at the index: " << i - j << endl;
return;
j = longest[j - 1];
}
else if (i < n && p[j] != s1[i]) {
if (j != 0)
j = longest[j - 1];
else
i = i + 1;
}
}
cout << "OOPs!! No match found!" << endl;
}
int main() {
string s1 = "Coding Ninjas";
string p = "Ninjas";
Pattern(p, s1, p.size(), s1.size());
return 0;
}
You can also try this code with Online C++ Compiler
public class ExamplePattern {
static void Compute(String pattern, int m, int longest[]) {
int len = 0;
longest[0] = 0;
int i = 1;
while (i < m) {
if (pattern.charAt(i) == pattern.charAt(len)) {
len++;
longest[i] = len;
i++;
} else {
if (len != 0)
len = longest[len - 1];
else {
longest[i] = 0;
i++;
}
}
}
}
static void Pattern(String p, String s1, int m, int n) {
int longest[] = new int[m];
Compute(p, m, longest);
int i = 0;
int j = 0;
while ((n - i) >= (m - j)) {
if (p.charAt(j) == s1.charAt(i)) {
j++;
i++;
}
if (j == m) {
System.out.println("The string/pattern is found at the index: " + (i - j));
j = longest[j - 1];
}
else if (i < n && p.charAt(j) != s1.charAt(i)) {
if (j != 0)
j = longest[j - 1];
else
i = i + 1;
}
}
System.out.println("OOPs!! No match found!");
}
public static void main(String[] args) {
String s1 = "Coding Ninjas";
String p = "World";
Pattern(p, s1, p.length(), s1.length());
}
}
You can also try this code with Online Java Compiler
def Compute(pat, m, longest):
Total_len = 0
longest[0]
i = 1
while i < m:
if pat[i] == pat[Total_len]:
Total_len += 1
longest[i] = Total_len
i += 1
else:
if Total_len != 0:
Total_len = longest[Total_len-1]
else:
longest[i] = 0
i += 1
def Pattern(p, s1, m, n):
longest = [0]*m
Compute(p, m, longest)
i = 0
j = 0
while (n - i) >= (m - j):
if p[j] == s1[i]:
i += 1
j += 1
if j == m:
print("The string/pattern is found at the index: " + str(i-j))
return
j = longest[j-1]
elif i < n and p[j] != s1[i]:
if j != 0:
j = longest[j-1]
else:
i += 1
print("OOPs!! No match found!")
# The main function
if __name__ == '__main__':
s1 = "Coder Platform"
p = "Platform"
Pattern(p, s1, len(p), len(s1))
You can also try this code with Online Python Compiler
In the best-case situation of the Naïve Pattern Search, the pattern is discovered properly at the start of the text. This approach is that we discover a fit as soon as we start comparing the pattern with the text. There aren't any pointless comparisons, and the algorithm finishes quickly.
Imagine you are studying an ebook and want to discover a particular phrase right at the start of the ebook. You open the book, and the first word you spot is the one you're looking for. That's like the excellent case for the Naïve Pattern Search – you find the pattern within the text immediately without searching through the whole textual content. It's the fastest and most efficient outcome for this simple seek approach.
Worst Case of Naïve Pattern Search
Imagine you have a long e-book (the text) and need to discover a selected word (the pattern) in it. The worst-case scenario for the naïve pattern seek is when you must check every unmarried man or woman in the e-book to locate the phrase.
In this situation, you would start at the start of the e-book and compare each letter with the primary letter of the phrase you are searching for. If they don't match, you pass to the subsequent letter inside the e-book and begin comparing again. This keeps until you either discover the word or look at the complete e-book.
This worst-case condition of affairs happens when the word is found at the very end of the book.
Advantages of Naive String Matching Algorithm
The comparison of the pattern with the given string can be done in any order.
There is no extra space required.
The most important thing that it doesn’t require the pre-processing phase, as the running time is equal to matching time
Disadvantages of Naive String Matching Algorithm
The one thing that makes this algorithm inefficient (time-consuming) is when it founds the pattern at an index then it does not use it again to find the other index. It again starts from the beginning and starts matching the pattern all over again.
It doesn’t use information from the previous iteration.
Frequently Asked Questions
Which of the algorithms is used for string matching?
There are many algorithms for string Matching, like Naive string matching, Rabin Karp, KMP string matching algorithm, Knutt Morris Pratt, Boyer-Moore, etc. Out of these, the most intuitive approach is the Naive String matching algorithm.
What is the complexity of the naive string-matching algorithm?
The time complexity of the naive string matching algorithm is O(n-m+1), where n = size of input string or text, and m = size of input pattern. The space complexity of the naive string-matching algorithm is O(1).
Are naive and brute-force algorithms the Same?
They are different. A naive approach is a direct approach to the problem, which can be both optimal and non-optimal. At the same time, the brute force approach is an approach that considers all the possible solutions to the problem and picks the best one.
Conclusion
We have completed the blog on Naive String Matching Algorithm, where we learned about the string machine, two different algorithms to perform string matching in C++, Java, and Python language, and about its advantages and disadvantages.
Refer to more articles similar to this on Coding Ninjas Platform.































 9+ registered
9+ registered 

