Do you think IIT Guwahati certified course can help you in your career?
Introduction
Machine learning is a fascinating field of computer science used to generate results from previous data without being hardcoded. It enables the creation of many new technologies such as weather forecasting, driverless cars, etc. Machine learning is a vast topic, and it has many applications. In this blog, we will look at a machine learning topic called StyleGAN used to create fake samples of an image. Let us look at StyleGAN in detail.
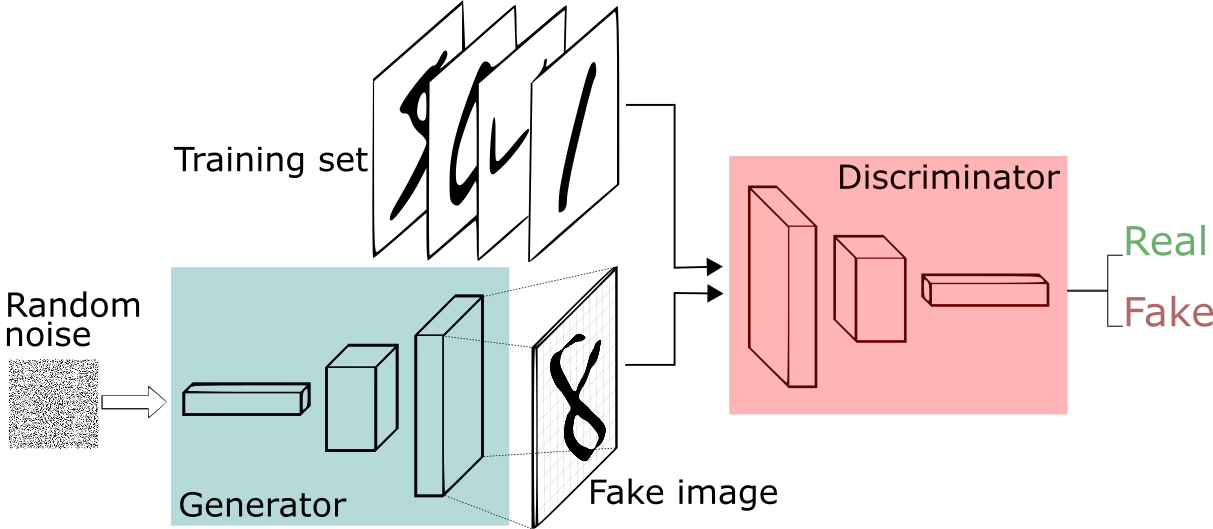
GANs (Generative Adversarial Networks) is a new Machine Learning concept described initially in 2014. The main objective of GAN is to create fake samples that are indistinguishable from real ones, such as pictures. For example, a GAN application can generate fake faces by learning from a collection of faces. GANs can produce realistic images but managing their output is difficult.
GANs have a generator and a discriminator. The generator generates fake data samples, and the descriptor distinguishes between the real and fake samples.
The GANs can be related to a minimax game, where the Discriminator is trying to minimize the loss of generator V(D, G), and the Generator tries to maximize the Discriminator’s loss.
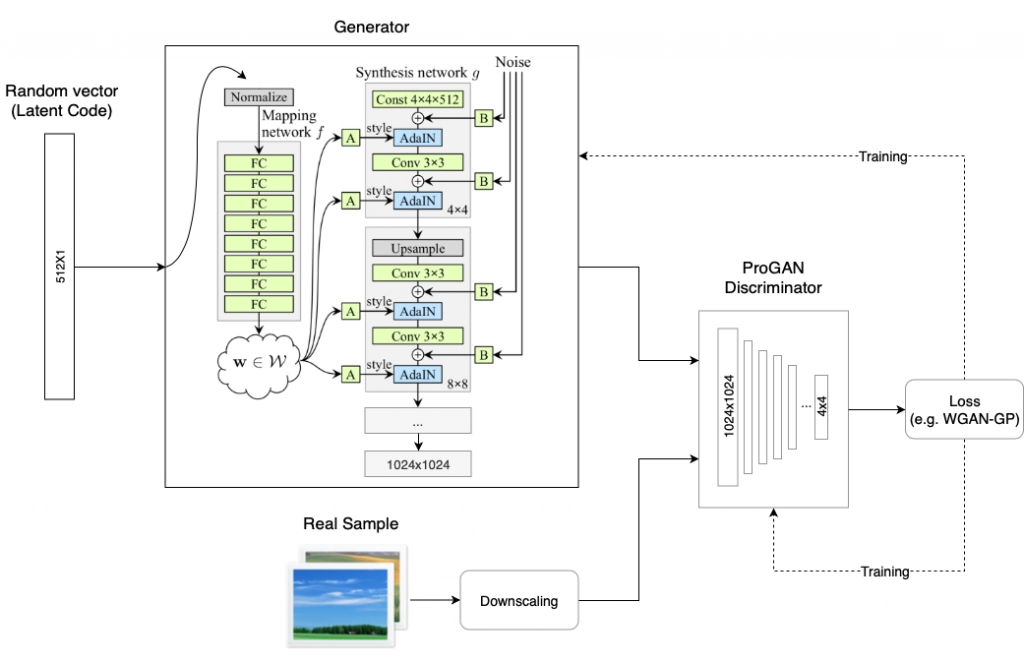
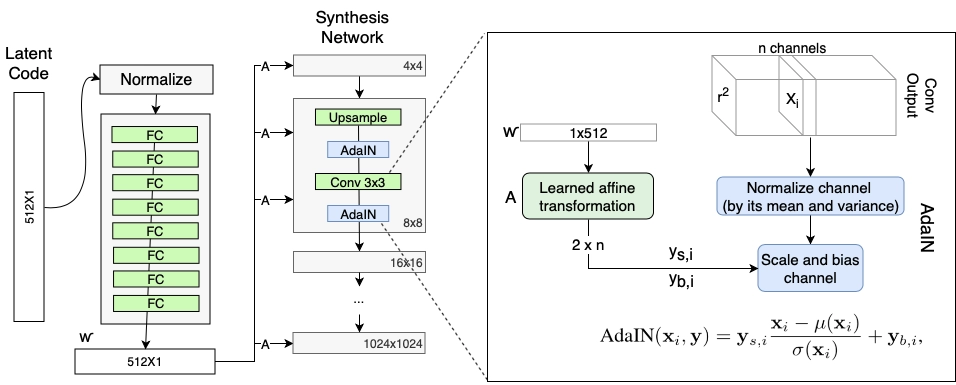
Style-based Generative Adversarial Networks (styleGAN) is a GAN architecture extension that modifies the generator model significantly. StyleGAN creates the simulated picture in stages, starting with a low resolution and increasing to a high resolution (1024X1024).
It uses a mapping network that maps the points in latent space to an intermediate latent space.
It controls style at each point in the generator model using the intermediate latent space.
It includes noise as a source of variation at each point in the generator model.
StyleGAN is capable of producing amazingly lifelike high-quality images of faces and providing control over the style of the generated image at various degrees of detail via style vectors and noise.
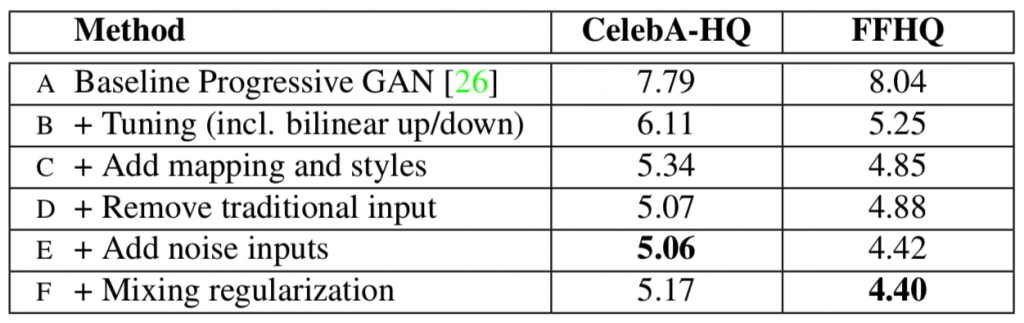
Style GAN used the baseline progressive GAN architecture and recommended various changes to the generator. The discriminator architecture remained similar to baseline progressive GAN. Let us examine particular architectural contrasts one at a time.
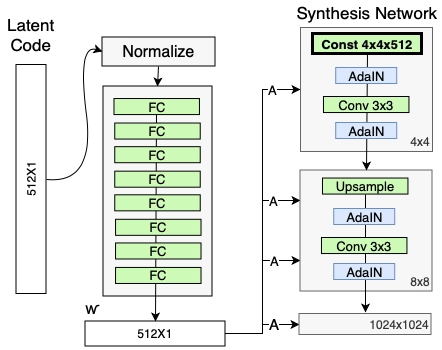
StyleGAN employs a baseline progressive GAN structure, which means that the volume of the generated image increases progressively from a low resolution (4X4) to a high resolution (1024 X 1024) by adding a new section to both models to maintain the larger resolution after applying the model to a lower resolution to make it more stable.
Bilinear Sampling
We employ a bi-linear sampling instead of the nearest neighbor up/down sampling in both the generator and the discriminator. Nearest neighbor up/down sampling is used in Baseline Progressive GAN architectures.
Mapping Network and AdaIN
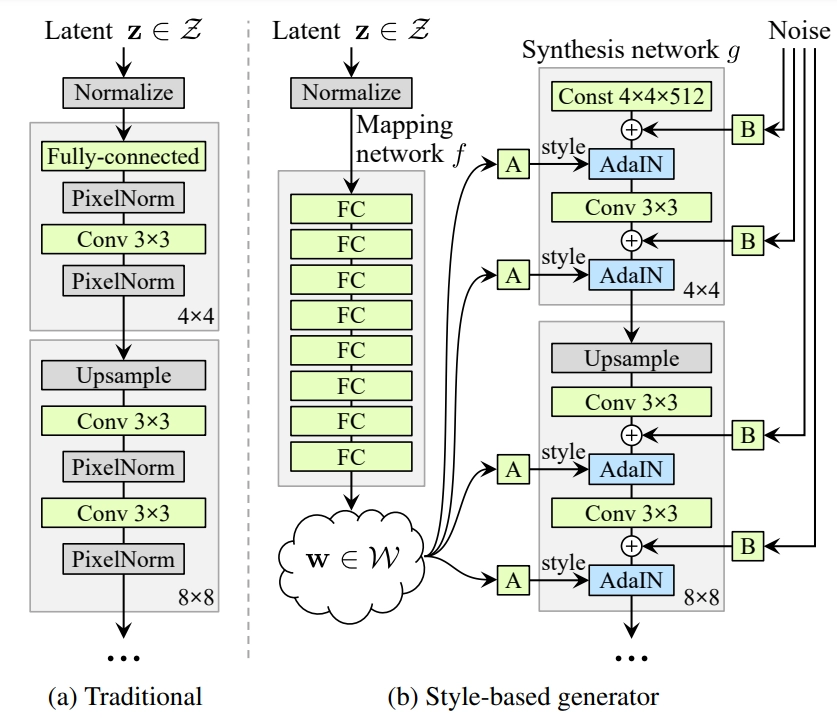
The mapping network's goal is to generate the latent input vector within the intermediate vector, whose unique elements influence various visual aspects. Mapping is performed instead of directly applying the latent vector to the input layer.
After the convolutional layers, the style vector is modified and included in each block of the generator model using a procedure known as adaptive instance normalization, or AdaIN.
The AdaIN layers begin by normalizing the output of the feature map to a standard Gaussian and then adding the style vector as a bias term.
The generator model is then modified to no longer accept a point from the latent space as input. The model has a constant 4x4x512 value input to begin the picture synthesis process.
Each convolutional layer in the synthesis network produces a block of activation maps. Before the AdaIN procedures, Gaussian noise is applied to each activation map. For each block, a separate noise sample is created and evaluated using per-layer scaling factors.
Regularization mixing
To begin mixing regularisation, the mapping network is used to generate two style vectors.
In the synthesis network, a split point is selected, and all AdaIN operations previous to the split point use the first style vector, while all AdaIN actions after the split point use the second style vector.
Introducing noise to Control Level of Detail
The authors altered the usage of noise at different degrees of detail in the model. The different levels are coarse, middle, and fine. As a result, noise provides control over the development of detail, ranging from the larger structure when noise is employed in big blocks of layers to the generation of tiny detail when noise is introduced to layers closer to the network's output. The synthesis network allows control over the style to multiple levels of detail to have greater control over the styles of the created picture (or resolution). The coarse, middle, and fine levels are as follows:
Coarse– resolution of (4X4 – 8x8 ) – influences stance, overall hairstyle, facial contour, and so on.
Middle – (16X16 – 32X32) resolution – influences finer face characteristics, hairstyle, eyes open/closed, and so forth.
Fine – resolution of (64X64 – 1024X1024) – impacts colors and micro characteristics for (eye and nose).




























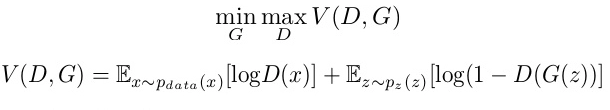





 18+ registered
18+ registered 

