


























Introduction
Imagine you have taken an image in some blurry manner, this could be because of the quality of the camera lens, scaling features, blurred background captures, etc., but that image may be very important for you. Well, there are so many websites that can get you a high-resolution image of that, but what if you can make it on your own using your machine learning and deep learning concepts. Yes, I think you guys got this concept. Quality is very important. At last, after any work, the ultimate feature that people see is the high quality of work. It is in the case of images too. High-quality images will attract people and give a good impression of it. On the same problem, twitter scientists have researched it and developed a concept called Super-Resolution GANs shortly SRGAN. The concept is pretty simple. You will get this concept clearly in this article. I hope you will enjoy this article.
Why SRGANs
As technology grows, the quality of images and videos is getting improved. First, we have the quality of 144p, 240p, 360p,etc. Then as technology advances, the development of 480p,720p, and similarly 1080p, etc., have been done. But the technology improves, it is important to convert a low-resolution image to a high-quality image and vice-versa according to the need. This can be done by using GANs(Generative Adversarial Networks).
The conversion of low-resolution images to high-resolution images is a very challenging task. For example, for a deep learning model to get trained on images with low quality may result in lead to incapable of observing finer details of the image and may lead to low accuracy. Thus the concept of Super-Resolution GANs is implemented by extending the concept of GANs.
SRGANs
SRGANs are the Generative Adversarial Network model developed by Twitter for converting a low-resolution image to a high-resolution image without losing much information. Imagine in the olden days, we used 1-2p in our PDAs to take pictures, well, they look fine at the same, but what if we need to see them on big screens or on a zoom? This makes them blurry. Here comes the concept of Super-Resolution handy.

Blurred Image Vs. Clear Image
The main idea is to introduce a new loss function called Perceptual loss, which is a combination of both adversarial loss and content loss. This can be shown below:
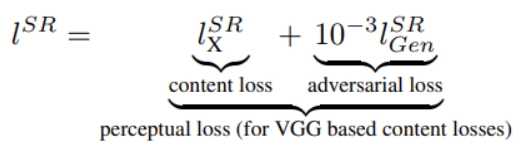
In many experiments, we came to know that this perceptual loss gives better results than the most popularly used MSE loss in dealing with images.
→ The SRGAN architecture
The architecture of SRGAN is similar to normal GAN architecture with the addition of one SR model. So this SRGAN also contains a generator and a discriminator, as shown below:
The SRGAN Generator

Input: Low-resolution image, the generator will take an input and pass it through a convolution layer with a kernel of size 9, with 64 channels, and with one stride (k9n64s1), and then a Parametric RELU (pReLU), a kind of Leaky ReLU, and so on as shown in the architecture. You can get more information about the architecture from this research paper.
The importance of the use of Leaky ReLU is that instead of setting the values less than zero to zero, it will set the values of less than zero to the number set by the user.
The SRGAN Discriminator

The discriminator works similar to the work of GAN, trying to discriminate between original and fake images. Here it is used to discriminate between super-resolution images and real/original images. This architecture is developed so as to solve the adversarial min-max problem by using the equation:

The overall architecture:



 8+ registered
8+ registered 

