Do you think IIT Guwahati certified course can help you in your career?
Introduction
An input string is passed through several Phases of Compiler. The first phase is the Lexical Analysis, where the input is scanned and is divided into tokens. Syntax analysis is the second phase of a compiler. The output of syntax analysis is used as input to the semantic analyzer.
In syntax analysis, the compiler checks the syntactic structure of the input string, i.e., whether the given string follows the grammar or not. It uses a data structure called a parse tree or syntax tree to make comparisons. The parse tree is formed by matching the input string with the pre-defined grammar. If the parsing is successful, the given string can be formed by the grammar, else an error is reported.
Syntax analysis, also known as parsing, is a key process in computer science, particularly in the area of compilers, which are programs that translate code written in a programming language into a form that a computer can understand. The role of syntax analysis is to check the code for correct syntax and to organize the code into a structured format that the computer can use to execute the program.
Key Functions of Syntax Analysis:
Error Checking: Ensures that the code written adheres to the defined syntax rules of the programming language.
Structure Organization: Converts code into a structured format, such as a parse tree or an abstract syntax tree, which represents the hierarchical relationship of code elements.
Steps Involved in Syntax Analysis:
Tokenization: Breaks down the code into basic elements or tokens (e.g., keywords, variables, operators).
Rule Application: Applies the programming language's syntax rules to the tokens to verify their correct arrangement.
Tree Construction: Builds a parse tree or abstract syntax tree from tokens if they follow the syntax rules correctly, illustrating the syntactic structure of the code.
Importance of Syntax Analysis
It is used to check if the code is grammatically correct or not.
The parsing techniques can be divided into two types:
Top-down parsing:The parse tree is constructed from the root to the leaves in top-down parsing. Some most common top-down parsers areRecursive Descent Parser and LL parser.
Bottom-up parsing: The parse tree is constructed from the leaves to the tree’s root in bottom-up parsing. Some examples of bottom-up parsers are the LR parser, SLR parser, CLR parser, etc.
Derivation
The derivation is the process of using the production rules (grammar) to derive the input string. There are two decisions that the parser must make to form the input string:
Deciding which non-terminal is to be replaced. There are two options to do this: a) Left-most Derivation: When the non-terminals are replaced from left to right, it is called left-most derivation. b) Right-most Derivation: When the non-terminals are replaced from right to left, it is called right-most derivation.
Deciding the production rule using which the non-terminal will be replaced.
Parse Tree
Parse tree is a graphical representation of the derivation. It is used to see how the given string is derived from the start symbol. The start symbol is the root of the parse tree, and the characters of the input string become the leaves.
Example
Consider the following set of production rules where ‘E’ is a non-terminal and ‘id’ is a terminal:
E -> E + E (This means that E can be replaced with E + E)
E -> E * E (This means that E can be replaced with E * E)
E -> id (This means that E can be replaced with ‘id’. Since ‘id’ is a non-terminal, it will not be replaced further, thus, it will form a leaf.)
We will construct a parse tree using the left-most derivation of “id + id * id”.
Steps
Parse Tree
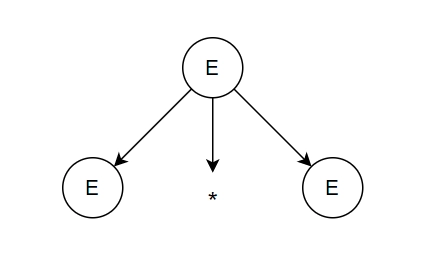
Step-1: Replace E with E * E.
Result: E * E
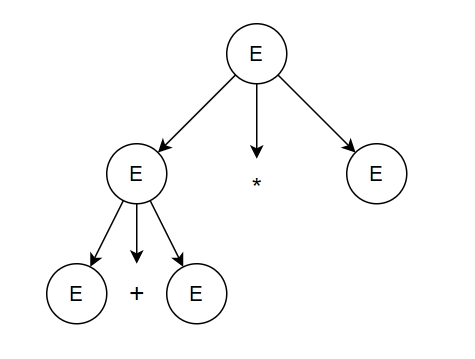
Step-2: Replace leftmost E with E + E
Result: E + E * E
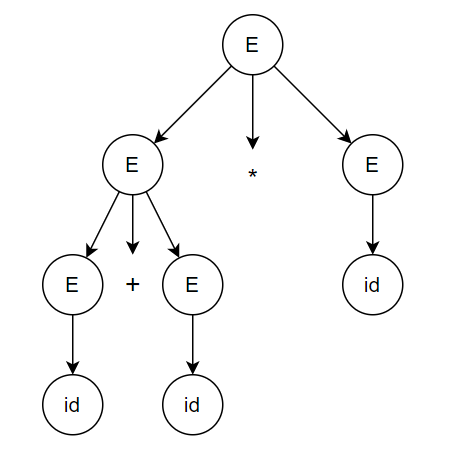
Step-3,4,5: Replace all E’s with id.
Result : id + id * id
Thus, we can generate a given string by following the production rules using the parse trees.
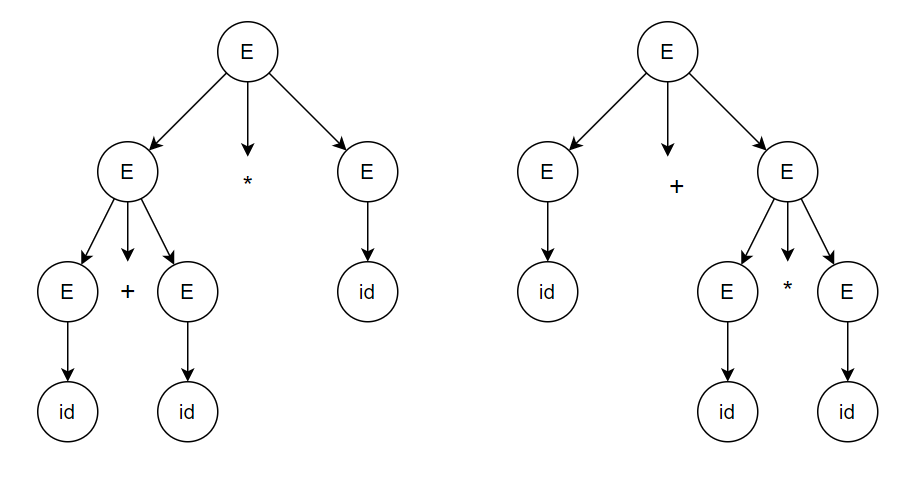
Ambiguity: Grammar is ambiguous if there is more than one parse tree for any string.
For example, for the above string and grammar, we can construct two parse trees:
Ambiguous grammar is not considered suitable for a compiler design. There is no method that can detect ambiguity or remove ambiguity. If there is an ambiguity in the grammar, one has to remove it by either rewriting the whole grammar or by following associativity and precedence constraints.
Limitations of Syntax Analysis
It cannot determine if the token is a valid token or not.
It cannot determine whether a token is used before or not.
It cannot determine whether the operation performed on tokens is valid or not.
It cannot tell whether the token was initialized or not.
Frequently Asked Questions
What are Parse Trees?
Parse trees or syntax trees are the data structures used by Syntax Analyzer to check if the input string can be formed using the given production rules or not. The start symbol forms the root of the parse tree and the string characters from the leaves.
What is ambiguity in syntax analysis?
A grammar is said to be ambiguous if there is more than one parse tree for any string. Such grammar is not considered suitable for a compiler design.
Conclusion
In this article, we learned about syntax analysis in compiler design. We discussed the importance and limitations of syntax analysis. We also how a compiler does syntax analysis using derivations and parse trees.






























 9+ registered
9+ registered 
