Do you think IIT Guwahati certified course can help you in your career?
A syntax tree (also called a parse tree) is a graphical representation of the structure of a sentence or a piece of code in a programming language. It represents how different parts of the sentence or code relate and fit together according to grammar or syntax rules.
Each node in the syntax tree represents a word or a component of the sentence, and the connections between nodes show their grammatical connection. This helps to understand the meaning and structure of sentences or code.
An ordered rooted tree that describes the syntactic structure of a string according to context-free grammar is known as a parse tree, parsing tree, derivation tree, or syntax tree. The phrase parse tree is mostly used in computer linguistics; the word syntax tree is more commonly used in theoretical syntax.
Each leaf node represents an operand, whereas each inner node represents an operator in a syntax tree.
The Parse Tree is condensed into the Syntax Tree. In a syntax tree, each leaf node stands in for an operand and each inside node for an operator. Another option is to define a concrete syntax tree as an ordered, rooted tree that depicts a string's syntactic structure in terms of context-free grammar.
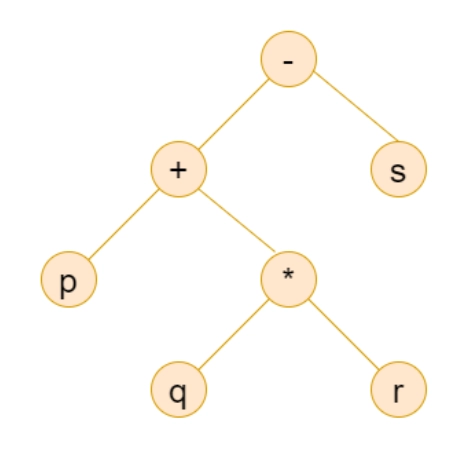
Example: Draw Syntax Tree for the string p + q ∗ r − s.
Rules for Constructing Syntax Tree
The syntax tree nodes can all be treated as data with several fields. The operator is identified by one node element, whereas the remaining areas include a pointer to the operand nodes. The node's label is also known as the operator. The following functions are used to generate the syntax tree nodes for expressions using binary operators. Each method returns a pointer to the most recently developed node.
mknode (op, left, right): It creates an operator node with the name op and two fields, containing left and right pointers.
mkleaf (id, entry): It creates an identifier node with the label id and the entry field, which contains a reference to the identifier's symbol table entry.
mkleaf (num, val): It creates a number node with the name num and a field containing the number's value, val. For example, construct a syntax tree for an expression p − 4 + q. In this sequence, a1, a2, … . . a5 are pointers to the symbol table entries for identifier 'p' and 'q' respectively.
The tree is constructed from the ground up. The leaves for p and 4 are created using mkleaf (id, entry p) and mkleaf (num 4), respectively. a1 and a2 are used to hold references to these nodes. The internal node with the leaves for p and 4 as children is created by using mknodes (′′, a1, a2). The syntax tree will look like this:
Syntax Tree for p - 4 + q
Syntax Trees Examples
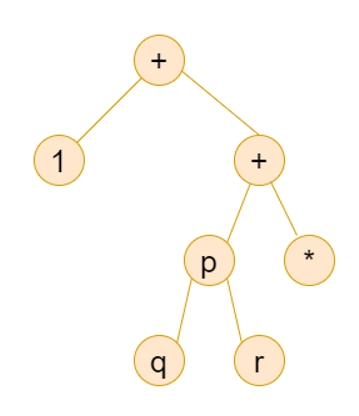
Example 1:- Draw the syntax tree for 1 + (3*4) + 1 ?
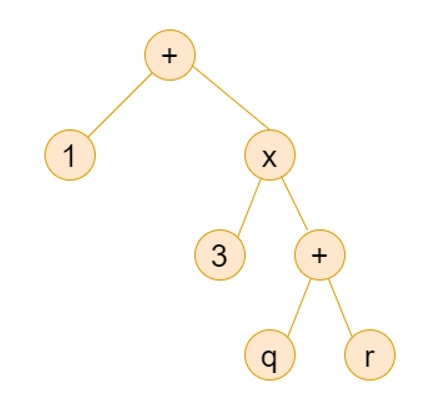
Example 2:- Draw the syntax tree for 1 + 3*(4+1)?
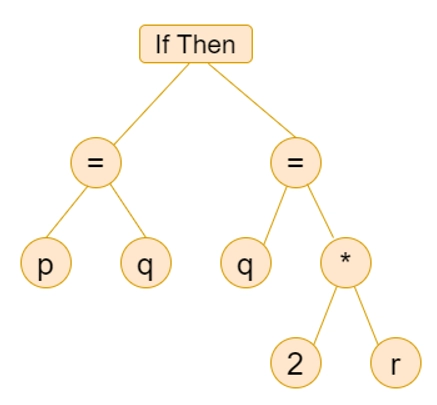
Example 3:- Construct a syntax tree for a statement.
If p = q then q = 2 * r
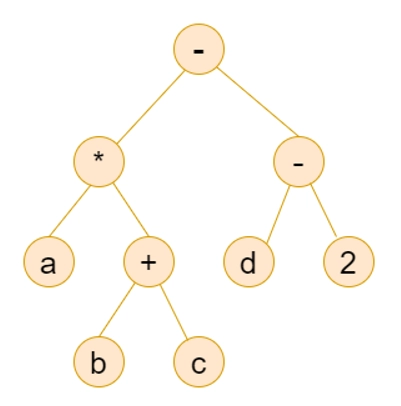
Example 4:- Draw syntax tree for following arithmetic expression a * (b + c) – d /2.
Variants of Syntax Tree
There are two variants of the syntax tree: Directed Acyclic Graph for Expressions(DAG) and The Value-Number Method for Constructing DAGs. Let us study them one by one.
Directed Acyclic Graph for Expressions(DAG)
A DAG has leaves that correspond to atomic operands and inside are the codes which correspond to operators. In it, the tree for a common subexpression will repeat as many times as the subexpression. Thus, it affects how the compiler will generate an effective code to evaluate the expressions.
It shows the structure of the fundamental blocks, allowing you to see the flow of the values among them and optimize them. It enables you to do simple transformations of the fundamental blocks.
Its properties are as follows:
The lead nodes are the identifiers, constants, or names.
Interior nodes denote operators and the results of expressions where the values are to be stored or assigned.
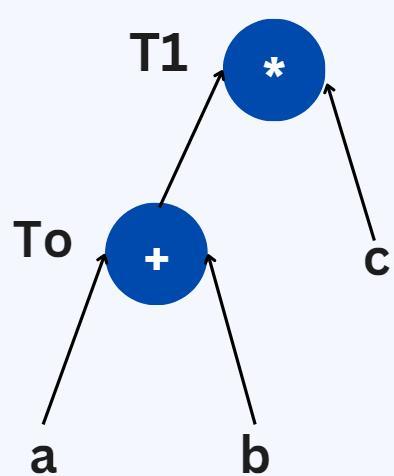
EXAMPLE
T0=a+b
T1=T0*c
Expression 1: T0=a+b
Expression 2: T1=T0*c
The Value-Number Method for Constructing DAGs
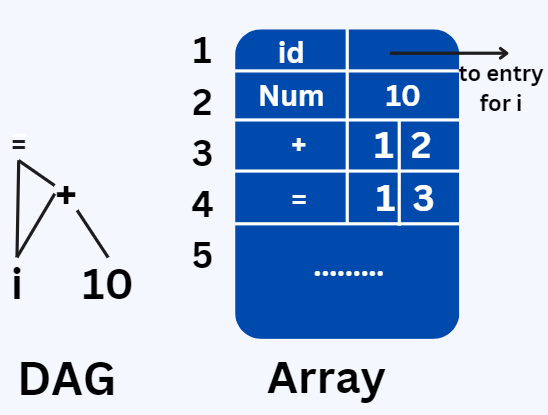
A collection of records is employed to store the elements of a syntax tree or directed acyclic graph (DAG). Each row in the collection represents a distinct record and, consequently, a unique node. The initial field in each record serves as an operation code, signifying the label of the node. In the provided diagram below, internal nodes possess two extra fields that represent the left and right children, while leaves have an additional field dedicated to holding the lexical value, which can be either a symbol-table pointer or a constant in this context.
The numeric identifier associated with a node within the array serves as a reference to nodes in this collection. In the past, this integer has been referred to as either the node's "value number" or the expression represented by the node. For instance, the node labeled as "-I-" has a value number of 3, with its left and right children having values of 1 and 2, respectively. Although, in practice, we may use pointers or object references instead of integer indexes, the reference to a node is still commonly called its "value number." When stored in the appropriate data format, value numbers can aid in constructing expressions.
ALGORITHM: The value-number approach for creating nodes in a Directed Acyclic Graph (DAG).
INPUT: Label op, left node I, and right node r.
OUTPUT: The value number associated with a node in the array with the signature (op, I, r).
METHOD: Search the array for a node M with label op, left child I, and right child r. If such a node exists, return the value number of M. If not, create a new node N in the array with label op, left child I, and right child r, and return its value number.
While the current algorithm accomplishes the desired result, it can be inefficient to scan the entire array each time a node is requested, particularly if the array contains expressions from an entire program. A more efficient strategy involves the use of a hash table, which segregates nodes into "buckets," each typically containing only a few nodes. The hash table is one of several data structures capable of effectively supporting dictionaries, a data type that facilitates adding and removing elements from a set and checking for the presence of a specific element within the set. A well-designed dictionary data structure, such as a hash table, executes each of these operations in constant or nearly constant time, regardless of the set's size. To establish a hash table for DAG nodes, a hash function denoted as "h" is essential. This function calculates the bucket index for a signature (op, I, r) in a manner that ensures the signatures are evenly distributed across buckets, preventing any single bucket from becoming overloaded with nodes. The bucket index h(op, I, r) is solely determined by the values of op, I, and r, guaranteeing that the calculation consistently maps each node (op, I, r) to the same bucket index.
The buckets can be implemented as linked lists, as depicted in the provided diagram. The headers for each bucket are stored in an array, indexed by the hash value. Each linked list within a bucket contains the value numbers of nodes that hash to that particular bucket. In other words, a node (op, I, r) can be found in the linked list associated with the array's header at index h(op, I, r).
We start by computing the bucket index, h(op, l, r), and then proceed to search through the list of cells within this particular bucket, using the provided input nodes op, l, and r. Typically, there are a sufficient number of buckets, ensuring that no list contains more than a few cells. However, in some cases, it may be necessary to examine all the cells within a bucket. For each value number, denoted as "v," encountered in a cell, we must validate whether the signature (op, l, r) of the input node matches the signature of the node with value number v in the list of cells (as illustrated in the diagram above). If a match is found, we return the value v. If no match is found, we construct a new cell, add it to the list of cells corresponding to the bucket indexed by h(op, l, r), and return the value number associated with the newly created cell.
Frequently Asked Questions
What is syntax tree with example?
The Parse Tree is condensed into the Syntax Tree. In a syntax tree, each leaf node stands in for an operand and each inside node for an operator. One can build a syntax tree for the string a + b c d, for instance.
What is the difference between DAG and syntax tree?
A DAG (Directed Acyclic Graph) has no cycles and represents dependencies, while a syntax tree represents the hierarchical structure of a language or expression.
What is a syntax tree in TOC?
In Theory of Computation (TOC), a syntax tree represents the grammatical structure of a string according to a formal grammar, showing syntax rules and derivations.
What is a syntax tree for code?
A syntax tree for code represents the structure of a program's source code, showing how its elements are syntactically related based on language grammar.
Conclusion
Syntax trees play a crucial role in understanding and analyzing the structure of languages, whether in programming or formal grammar. They provide a clear, hierarchical representation of how expressions, statements, or code are constructed according to specific rules. By visualizing the relationships between components, syntax trees help in parsing, compiling, and optimizing code, making them an essential tool for developers and linguists alike.
































 9+ registered
9+ registered 
