


























Introduction
Imagine a world where your computer could read text from any image or scanned document, freeing you from the tedious task of manual data entry. Sounds like magic, right? Well, in the realm of Optical Character Recognition (OCR), this magic exists, and one of its most powerful wizards is Tesseract OCR.

In this article, we'll explore how to wield this wizardry using Java, allowing you to turn images into editable text with just a few lines of code.
What is Tesseract OCR?
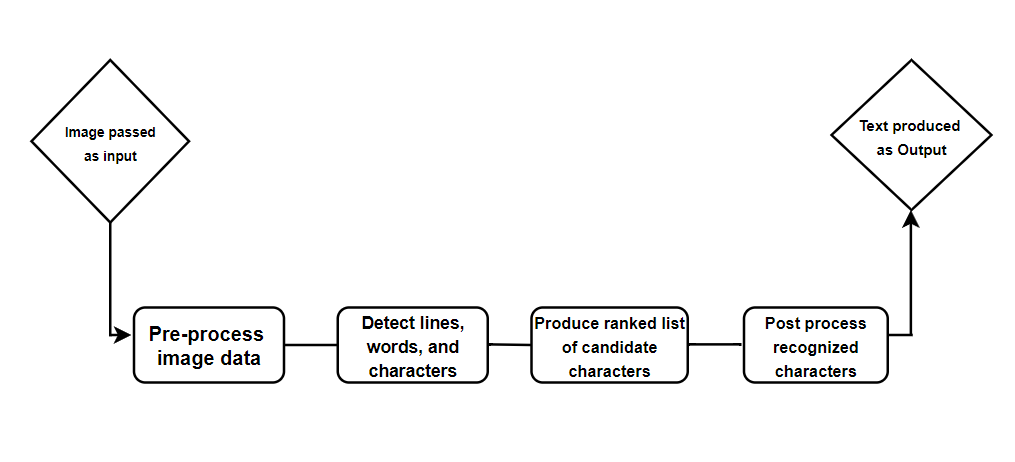
Tesseract OCR (Optical Character Recognition) is a free and open-source software that can recognize text from images. Developed initially by HP and now sponsored by Google, it is one of the most accurate OCR engines available today. Tesseract OCR is highly and most accurate OCR software that helps in fetching the text from the images and converting it into machine-readable code.
Why Choose Tesseract?
-
High Accuracy: Tesseract is trained on a vast dataset, making it incredibly accurate in text recognition.
-
Multi-language Support: From English to Zulu, Tesseract can recognize a multitude of languages.
-
Ease of Use: With simple command-line or API usage, integrating Tesseract into your project is a breeze.
-
Open-Source: It is an open-source software that is free of cost to use with the highest accuracy.
-
Extensibility: It is highly extensible. The software can work on operating systems like Windows, macOS, and more.
- Command Line Interface: Tesseract OCR provides you a simple command line interface that makes it easy to use through commands and scripts.
Setting Up Tesseract OCR in Java
Before diving into the code, you'll need to set up your Java environment to work with Tesseract.
Installation Steps
Download Tesseract: You can download the executable from the official Github repository.
Install Java Libraries: You'll need to add the Tesseract library to your Java project. If you're using Maven, just add the following dependency:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>Writing Your First Java Code with Tesseract OCR
Once the setup is complete, you can start writing your Java code to extract text from an image.
import net.sourceforge.tess4j.*;
public class OCRDemo {
public static void main(String[] args) {
Tesseract tesseract = new Tesseract();
try {
tesseract.setDatapath("C:/Tesseract-OCR/tessdata");
String text = tesseract.doOCR(new File("sample.jpg"));
System.out.println(text);
} catch (TesseractException e) {
e.printStackTrace();
}
}
}In this example, setDatapath points to the location of the Tesseract data files, and doOCR performs the OCR operation on the image file sample.jpg.
Fine-Tuning and Optimization
While Tesseract is highly accurate, you can fine-tune its performance further.
Using Preprocessing Techniques
Improving image quality through preprocessing techniques like binarization can enhance OCR accuracy. Java provides a plethora of libraries to do this, such as OpenCV.
Language Configuration
For non-English text, you can specify the language using the setLanguage method:
tesseract.setLanguage("deu");

 8+ registered
8+ registered 

