Do you think IIT Guwahati certified course can help you in your career?
Introduction
The Gated Recurrent Unit or GRU is a kind of Recurrent Neural Network. It is younger than the more popular Long Short-Term Memory (LSTM) network (RNN). GRUs, like their sibling, can retain long-term dependencies in sequential data. Furthermore, they can address the "short-term memory" problem that plagues vanilla RNNs. Given the legacy of Recurrent architectures in sequence modelling and predictions, the GRU is poised to outperform its elder sibling due to its superior speed while achieving comparable accuracy and effectiveness. In this article, we'll go over the concepts of GRUs and compare their mechanisms to those of LSTMs. We'll also look at the differences in performance between these two RNN variants.
Prerequisites
If the reader is unfamiliar with RNNs or LSTMs, they should have a look through the following topics:
1. Recurrent Neural Networks.
2. Long Short-Term Memory.
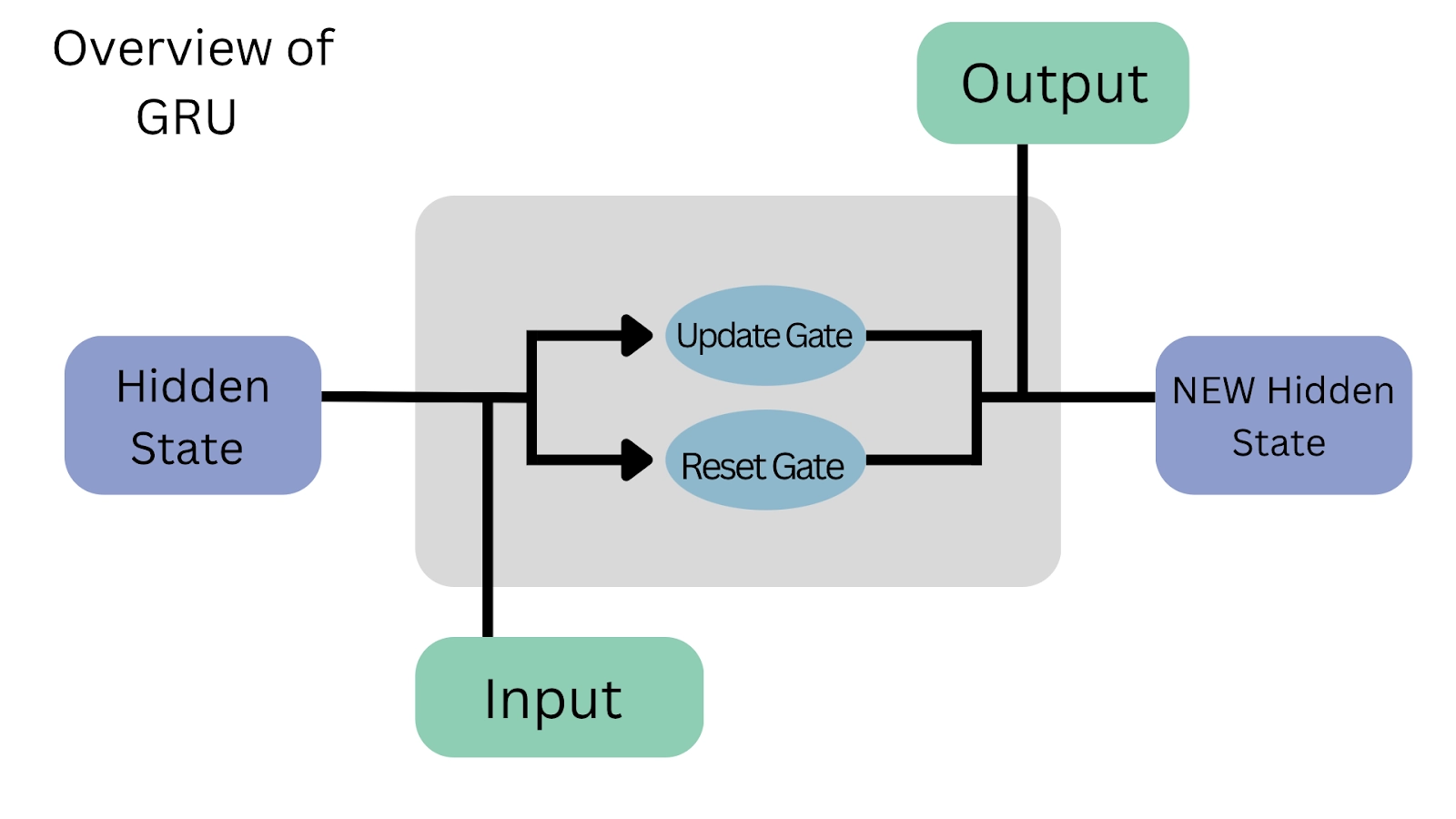
Gated Recurrent Units
As the name implies, a Gated Recurrent Unit (GRU) is a variant of the RNN architecture. It controls and manages the flow of information between cells in the neural network using gating mechanisms. Cho and colleagues first introduced GRUs in 2014. It is a relatively new architecture, especially when compared to Sepp Hochreiter and Jürgen Schmidhuber's widely used LSTM, which was proposed in 1997.
The GRU's structure lets it capture dependencies from big data sequences in an adaptive style without throwing away data from earlier parts of the sequence. This gets accomplished through gating units similar to those found in LSTMs, which solve the vanishing/exploding gradient problem of traditional RNNs. These gates control whether the information is retained or discarded at each time step. Later in this article, we'll get into the specifics of how these gates work and how they overcome the abovementioned issues.
How Does GRU Work
GRUs operate in the same manner as traditional RNNs. GRUs are analogous to Long Short Term Memory (LSTM). Gated Recurrent Units, like LSTM, control the flow of data using gates. They are a newer technology than LSTM. This is why they beat LSTM and have a simpler architecture.
LSTM VS GRU
The GRU's ability to retain long-term dependencies or memory arises from the computations performed within the GRU cell to produce the hidden state. While LSTMs transfer two states between cells — the cell state and the hidden state, which carry long and short-term memory, respectively — GRUs only transfer one hidden state between time steps. Because of the gating mechanisms and computations that the hidden state and input data go through, this hidden state can hold both long-term and short-term dependencies at the same time.
Gates
Even though both GRUs and LSTMs contain gates, the main distinction between these structures is the number of gates and their specific functions. The Update gate in the GRU performs a similar function to the Input and Forget gates in the LSTM. The control of new memory content added to the network, on the other hand, differs between these two.
The Forget gate in the LSTM determines which part of the previous cell state to retain, while the Input gate determines how much new memory to add. These two gates are independent of one another, meaning that the amount of new information added via the Input gate is altogether independent of the data retained via the Forget gate.
Regarding the GRU, the Update gate determines which information from the last memory to retain and also controls the new memory to be added. It means that the GRU's memory retention and addition of new information are NOT independent processes.
Cells
Another significant distinction between the structures is the absence of cell state in the GRU. Simultaneously, the LSTM stores its long-term dependencies in the cell state and its short-term memory in the hidden state. Both are kept in a single hidden state by the GRU. However, both architectures have been shown to achieve this goal effectively in terms of long-term information retention.
Speed Differences
GRUs train faster than LSTMs because there are fewer weights and parameters to update during training. This is because the GRU cell has two fewer gates than the LSTM, which has three.
In this article's code walkthrough, we'll directly compare the speed of training an LSTM versus a GRU on the same task.
Performance Evaluations
When deciding which model to use for a task, the model's accuracy, whether evaluated by the margin of error or the proportion of proper and accurate classifications, is generally the most crucial factor to consider. GRUs and LSTMs are RNNS variants that can be used interchangeably to achieve comparable results.
Code Implementation
We've learned about the GRU's theoretical concepts. It's now time to put what we have understood to use.
We will be writing code to implement a GRU model. To supplement our GRU-LSTM comparison, we will perform the same task with an LSTM model. Then we will make a comparison between the performance of the two models.
Code
Let us have a look at an example. Through this code, we will also compare GRU with LSTM. We will also give a Time-series Prediction.
%reset
You can also try this code with Online Python Compiler
#To run the experiment, change the values.
experiment = 1 #BANKEX = 1; ACTIVITIES = 2
f = 20
#The length of the future window in days.
#Change f to represent the number of steps ahead. 1 or 20.
thepath = 'sample_data'
#Change the path to where you want the models saved.
You can also try this code with Online Python Compiler
from numpy.random import seed
seed(1)
import tensorflow
tensorflow.random.set_seed(2)
import math
import numpy as np
import pandas as pd
from keras.layers import Dense, LSTM, Dropout, GRU
from numpy import genfromtxt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
import matplotlib.pyplot as plt
from pandas_datareader import data as pdr
import matplotlib.cm as cm
from sklearn.metrics import mean_squared_error
from scipy.stats import mannwhitneyu
You can also try this code with Online Python Compiler
#Based on the Video :
# "Computer Science: Stock Price Prediction Using Python and Machine Learning."
#Link: "https://www.youtube.com/watch?v=QIUxPv5PJOY"
def data_preparation(w, scaled_data, N, f):
X=[]
window = w + f
Q = len(scaled_data)
for i in range(Q-window+1):
X.append(scaled_data[i:i+window, 0])
X = np.array(X)
X = np.reshape(X, (X.shape[0],X.shape[1],1))
trainX, trainY = X[0:N,0:w], X[0:N,w:w+f]
testX, testY = X[N:Q-w,0:w], X[N:Q-w,w:w+f]
X = trainX
return trainX, trainY, testX, testY, X
You can also try this code with Online Python Compiler
#The last known value is repeated f times.
def baselinef(U,f):
last = U.shape[0]
yhat = np.zeros((last, f))
for j in range(0,last):
yhat[j,0:f] = np.repeat(U[j,U.shape[1]-1], f)
return yhat
You can also try this code with Online Python Compiler
#Normalizing the data between 0 and 1
def scaleit(DATAX):
mima = np.zeros((DATAX.shape[0], 2)) #To save min and max values
for i in range(DATAX.shape[0]):
mima[i,0],mima[i,1] = DATAX[i,:].min(), DATAX[i,:].max()
DATAX[i,:] = (DATAX[i,:]-DATAX[i,:].min())/(DATAX[i,:].max()-DATAX[i,:].min())
return DATAX, mima
You can also try this code with Online Python Compiler
#This is Based on suggestions from
#The link: "https://stackoverflow.com/questions/12236566/setting-different-color-for-each-series-in-scatter-plot-on-matplotlib"
#This code is to plot series of different colors
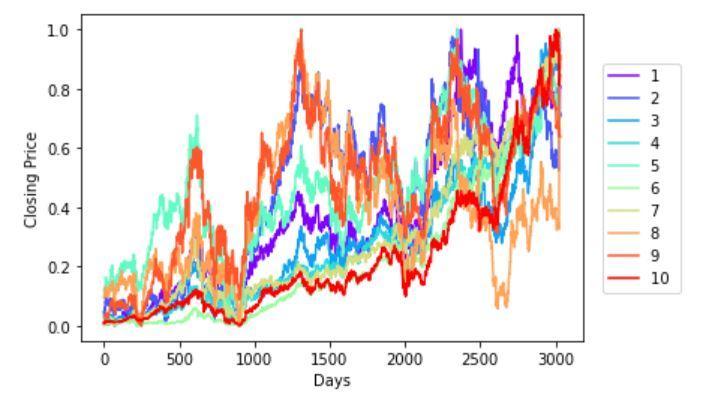
def plot_series(X):
x = np.arange(10)
ys = [i+x+(i*x)**2 for i in range(10)]
colors = cm.rainbow(np.linspace(0, 1, len(ys)))
for i in range(10):
plt.plot(X[i], label='%s ' % (i+1), color=colors[i,:])
plt.legend(bbox_to_anchor=(1.04,0.5), loc="center left", borderaxespad=0)
plt.xlabel("Days")
plt.ylabel("Closing Price")
You can also try this code with Online Python Compiler
selected_series = 0 #Select one signal arbitrarily to train the dataset
scaled_data = DATAX[selected_series, :]
scaled_data = np.reshape(scaled_data, (len(scaled_data),1))
scaled_data.shape
You can also try this code with Online Python Compiler
# Training the LSTM model
lstm_trained = lstm_model.fit(trainX, trainY, shuffle=True, epochs=epochs)
# Training the GRU model
gru_trained = gru_model.fit(trainX, trainY, shuffle=True, epochs=epochs)
You can also try this code with Online Python Compiler
#To save the models, use this code.
if experiment == 1:
ex = 'B'
else:
ex = 'A'
gru_model.save(thepath+'/GRU_'+str(ex)+str(f)) #Saves GRU
lstm_model.save(thepath+'/LSTM_'+str(ex)+str(f)) #Saves LSTM
You can also try this code with Online Python Compiler
A gated recurrent unit (GRU) is a type of recurrent neural network that uses connections through a series of nodes to perform machine learning tasks related to memory and clustering, such as speech recognition.
Does GRU have a forget gate?
The GRU functions similarly to a long short-term memory (LSTM) with a forget gate, but with fewer parameters because it lacks an output gate.
Can we combine LSTM and GRU?
Although LSTM came before GRU and GRU contains less computation, LSTM is roughly on par with GRU in terms of performance. Stacking LSTM and GRU or any other cells may be interesting, but it will not significantly improve performance over simply stacking LSTM or GRU cells.
Conclusion
In the article, we read about time series prediction with GRU. We also saw the prerequisites and compared GRU with LSTM. Finally, we implemented a code to see and compare the time series prediction. Time series prediction can come to good use when forecasting an outcome. You can learn about Cloud Computing and find our courses on Data Science and machine learning. Do not forget to check out more blogs on GRU to follow.




































 9+ registered
9+ registered 

