Do you think IIT Guwahati certified course can help you in your career?
Introduction
Graphs form the backbone of any coding interview. Thus it's very important to have a good grasp of this topic. Knowing the space and time complexities of each of its algorithms is as much important as knowing how to code them. But don't you worry about any of it. Ninjas are here for you, and today we will are going to discuss the time and space complexities of various graph algorithms, namely BFS, DFS, 0-1 BFS, Topological sort, and flood fill algorithm.
BFS
BFS stands for breadth-first search. It starts from the root of the given graph and then traverse all nodes at the current depth level before moving on to nodes at the next depth level. You can read more about it Here.
The time complexity of BFS depends upon the Data Structure used to store the graph.
If, for example, an adjacency list is used to store the graph.
In adjacency, the list node keeps track of all of its neighboring edges. Let's say that there are V nodes and E edges in the graph.
We can find all the neighbors of a node just by traversing its adjacency list only once, that too in linear time.
The sum of the sizes of the adjacency lists of all nodes in a directed graph is E. Thus, for a directed graph, the time complexity is O(V) + O(E) = O(V + E).
In an undirected graph, each edge appears twice. Once at either end of the adjacency list for the edge. Thus, in this case, the time complexity is O(V) + O (2E) ~ O(V + E).
If we use an adjacency matrix to store the graph, then.
To find all the neighboring nodes, we have to traverse a full row of length V in the matrix.
Each row in an adjacency matrix corresponds to a node in the graph, and each row stores information about the edges that emerge from that node. As a result, in this situation, the time complexity of BFS is O(V * V) = O(V ^ 2).
Space complexity
Because we're using a queue (FIFO architecture) to keep track of the visited nodes, the queue would take the size of the graph's nodes (or vertices). As a result, the space complexity is O (V).
DFS
DFS stands for depth-first search. The algorithm starts from the root node of the graph and explores as far as possible along each branch, and then after going at the depth most point possible, it backtracks. You can read more about it Here
Similar to that of BFS time complexity of DFS Algorithm depends upon the data structure used to store the graph. If it's an adjacency list, then the time complexity is O(V + E); otherwise, if it's an adjacency matrix, the time complexity is O(V ^ 2). Reasons are the same as that of BFS as in this also we are traversing each node of the graph.
Space complexity
We are using a stack to keep track of the last visited node. Thus it would take the size of the number of nodes (vertices) in the tree. Hence, the space complexity is O(V).
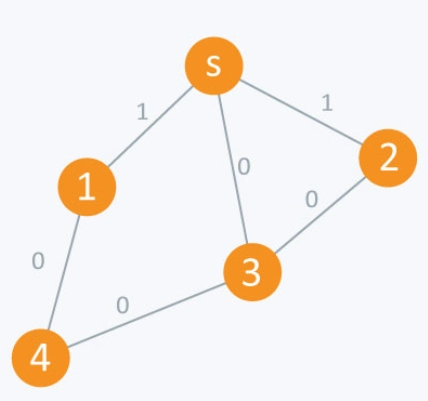
This version of BFS is used to identify the shortest path or distance between two nodes in a graph having edge values of 0 or 1.
When the weights of edges are 0 or 1, regular BFS techniques produce incorrect results because the weights of edges in the graph are supposed to be equal in normal BFS techniques.
Instead of utilizing a bool array to mark visited nodes, we will check for the optimal distance condition in this strategy.
To store the node details, we will use a double-ended(dequeue) queue. If we face a weight = 0 edge when executing BFS, the node is pushed to the front of the double-ended queue, and if we find a weight = 1 edge, the node is moved to the back of the double-ended queue.
The time complexity is similar to that of regular BFS as in 0-1 BFS also. We are visiting every node only once. Thus the time complexity is O(V + E). Where ‘V’ is the number of vertices, and ‘E’ is the number of edges.
Space complexity
Instead of using a regular queue, we are using a double-ended queue, which will also store ‘V’ nodes; thus, the space complexity is O(V).
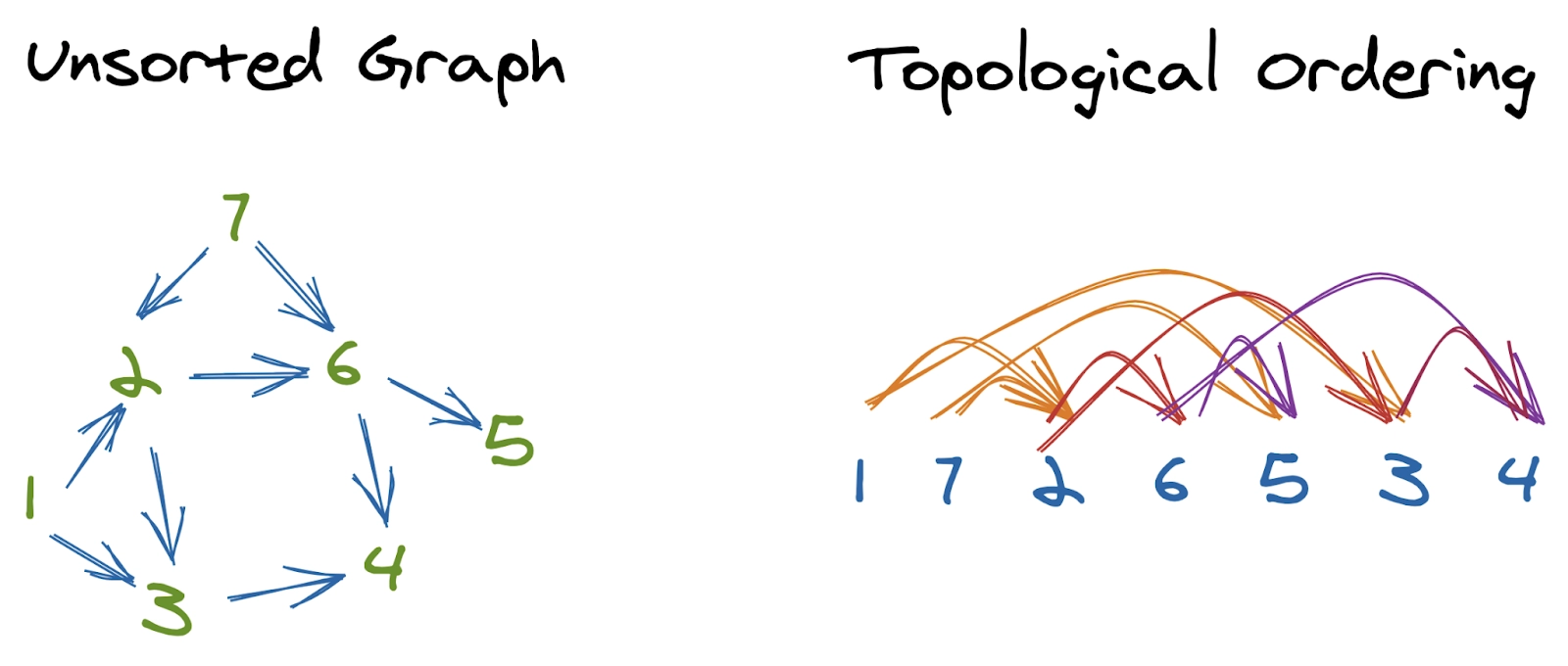
Topological Sorting
A topological ordering of a directed graph is a linear ordering of its vertices in such a way that if there exists a directed edge from ‘u’ to ‘v,’ then ‘u’ should come before ‘v’ in the ordering. It is implemented using Kahn’s algorithm. You can read more about it Here.
Now we know that topological sort is implemented using Kahn’s algorithm, i.e., using BFS. Thus the time complexity would be the same as that of BFS, which is O(V + E). Where ‘V’ is the number of vertices, and ‘E’ is the number of edges.
Space complexity
As the core of Kahn’s algorithm is BFS thus, it will take O(V) space as that taken by BFS.
Flood Fill Algorithm
The flood fill algorithm helps in the visitation of all points within a specified area. In a multi-dimensional array, it specifies the region associated with a specific cell.
We would be traversing over all the elements in the matrix, making the time complexity O(M * N). Where ‘M’ is the number of rows and ‘N’ is the number of columns in the matrix.
Space complexity
We will be using a queue to perform the traversing operation, which will cost us O(M * N) space. Where ‘M’ is the number of rows and ‘N’ is the number of columns in the matrix.
What is a Graph? A graph is a non-linear data structure made up of nodes and edges. The edges represent some correlation between the nodes. Nodes are sometimes known as vertices, while edges are lines or arcs that connect any two nodes in the network.
How do directed and undirected graphs differ? The directed graph contains ordered pairs of vertices, while the undirected contains unordered pairs of vertices. In a directed graph, edges represent the direction Of vertices, while edges do not represent the direction of vertices.
What is the maximum number of edges in the undirected graph of Nodes N? Each node can have an edge with every other N-1 node in an undirected graph. Thus, the total number of edges possible, will be N*(N-1), but here, in the undirected graph, the two edges between two nodes will be same. So we need to remove one of them. Therefore the total number of edges possible are N * (N - 1)/2.
How can we Implement BFS? BFS can be implemented using a queue. We keep adding the nodes present at the same level into the queue and pop out the nodes of the previous level from the queue. When we finish traversing one level, all next level’s nodes are there in the queue at that time.
How can we Implement DFS? DFS can be implemented using a stack. The nodes encountered are stored in a stack. And once all the children of a node are traversed, it is popped out of the stack.
Key Takeaways
We saw the time and space complexities of different graph algorithms, namely BFS, DFS, 0-1 BFS, Topological Sort, Flood-fill algorithm. After reading the theory, it’s time to head over to our practice platform Coding Ninjas Studio to practice top problems on every topic, interview experiences, and many more. Till then, Happy Coding!































 9+ registered
9+ registered 
