Apriori Algorithm:
This algorithm uses the frequent itemsets to derive an association rule, which is used to classify items that are correlated together or predict the possibility of such association in the future. Its basic concept if the subset of a frequent set may also be a frequent set of items. It is used in a database of huge transactions and finding useful patterns in such transactions
It uses two attributes:
-
Support: Simply the ratio of the frequency of the items upon the total number of items.
-
Confidence: It is the possibility or probability of an association of two or more items in the set.
-
Lift: It is the ratio of Support of an association upon the product of supports of the items.
Let us see an example to make it clearer: Suppose in an e-commerce website a person buys a laptop, now it is more likely for the person to buy a laptop bag or a laptop cover. Hence there is an association between laptop and laptop bag now. Let’s call this a transaction and the respective buying of items as A & B.

We define in our algorithm the initial values of support and confidence i.e. filter out the associations which are less frequent. Finally, we are left with fewer correlations and hence more analysis can be done on these. Like if buying A and B together gives a discount, the person can also buy an USB stick. Hence more such associations can be analyzed now for better customer engagement.
Advantage Of Apriori Algorithm:
- Highly efficient – better time complexity.
Disadvantage Of Apriori Algorithm:
- High memory usage, as it runs through the whole database.
AdaBoost Algorithm
This is a boosting algorithm which is used to classify the data for various machine learning algorithms and combines them. It takes the help of decision trees (using stumps) and produces its output from a randomly generated forest. Successive use of AdaBoost produces more elegant data sets which are easier to analyze. It can combine a large number of learning algorithms and can work on a large variety of data.
The main purpose is to convert a weak learner to a strong learner assessing from a stump (a tree with one root node and two child nodes or a one-level decision tree). Now let us understand this algorithm with an example: Let there be a series of transactions of buying two products and the last product3 is predicted to be bought based on product1 and product2.
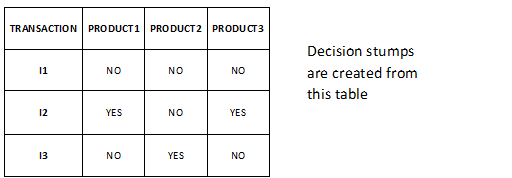
Example of one such stump is:
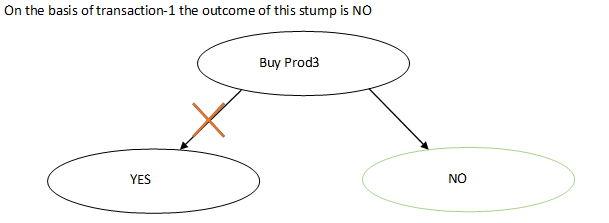
This is applied again and again on the transactions until a valid set of items are derived. This is called supervised learning, when one outcome produces some unorganised data set, it is then passed to other algorithm and so on until a valid data set is found.
Advantages of AdaBoost Algorithm
- Simple to implement, straight forward
- Generally fast
Disadvantages of AdaBoost Algorithm
- When the decision trees are fairly large, the stumps become weaker.
C4.5 Algorithm
It is one of the best algorithms available. This algorithm works on the basis information gain while generating decision trees. It generates a classifier in the form of a decision tree and in the nodes of this tree, fills with attributes which will be best suited for the decision tree. Each such node is called a data point.
Classifier: It is data mining tool that takes a set of input variables and tries to classify and predict their type. The attribute with the highest normalized information gain is taken into consideration for making the decision of that class of decision tree. This repeats over each node and thus the tree goes on building up from top to bottom. In order to control discrete attributes, it splits the nodes into groups that are more than and less than a threshold value which is defined by the user. It also removes the branches which don’t help in the decision-making & replace them with leaf nodes.
C4.5 uses the entropy of data as the key classifier attribute.
Advantages Of C4.5 Algorithm
- Efficient in terms of both memory and time.
Expectation Maximisation – EM Algorithm
This represents a class of iterative algorithms for finding the maximum estimation in a set of data. Simply means in a set of data, it evaluates the mathematical expectation of the data over its neighbourhood. This consists of two steps –
-
E-Step: Estimation of expectation of missing values in a set of data.
-
M-Step: Maximising the likelihood of the parameters computed in the previous step i.e. expectation.
Let us discuss this further. Let X – Labelled or Data, Y – Missing values, Z – Unknown parameters.
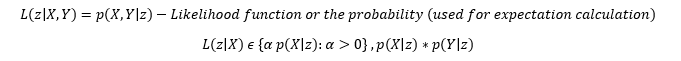
Note: Prerequisite of probability distribution is suggested.
Using the above formulas for estimation, the likelihood of unknown parameters is calculated. Accuracy from this can be calculated as:
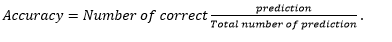
Advantages of EM Algorithm
- Semi-supervised algorithm-increase of efficiency.
- Fewer errors are due to less human intervention.
Disadvantages of EM Algorithm
- If the data or set of data fails to lie in any type, then this algorithm fails.
k-means Algorithm:
This is a central type clustering algorithm (grouping algorithm). The set of data is divided into groups or clusters and then the mean of these clusters is calculated in a repeated fashion until the means of the clusters are nearly equal.
These involve the following steps:
- Taking the mean value
- Finding the nearest number to mean
- Inserting that means in the cluster
- Repeating the above steps till we get the same mean
Advantages of k-means Algorithm:
- Simple algorithm-easier implementation
- Faster in already clustered data set

k-NN or k-Nearest Neighbor Algorithm
This algorithm is slow learning but supervised algorithm. It also classifies items in data set in k – clusters. This process does not analyse the data while storing i.e. only analyses the data if unlabeled input is given.
This has two basic steps:
- Finds the k nearest neighbours in the training data set.
- Uses the above neighbour classes to classify the new sets of unlabeled inputs.
It works similar to the k-means algorithm in terms of continuous data sets, i.e. it uses Euclidean Geometry to cluster data.
Disadvantages of k-Nearest Neighbor Algorithm
- This algorithm is computationally expensive i.e. the value of k and dataset can be huge
- Erroneous data sets can cause large deviations
- When the value of k is large, this process requires more storage
Naive Bayes Algorithm
This algorithm represents supervised learning using a probabilistic model based on Bayes Probability Theorem. It also finds the maximum likelihood of the event to be predicted occurring based on the trained dataset. Each attribute must be different and does not depend on another attribute. This is used to predict the class given a set of features using probability. Let us recall the Bayes Theorem of probability to understand this algorithm.
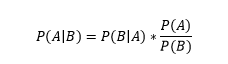
It gets a naive data set containing past outcomes and the algorithm is trained over this data set. Now, when an unlabeled data set is given input, the outcome is predicted on the basis of the trained data already present in the memory using probability of occurrence.
CART Algorithm
Classification and Regression Tree algorithm is based on decision tree architecture. It can handle both classification & regression tasks. The main formula involved in CART is:
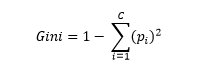
This formula uses a metric system named Gini index as a parameter. Steps for the algorithm is briefly described as-
- Calculating the Gini index for each attribute
- Calculating the weighted sum of Gini indexes
- Selecting the attribute with the lowest Gini index value
- Repeating the above steps until the decision tree is formed
Support Vector Machines Algorithm
This algorithm is fairly similar to the C4.5 algorithms except that this does not use decision trees. It uses a hyperplane equation i.e. a straight-line equation to classify its data into two clusters or classes. It is a supervised learning algorithm. Although for complex data sets, the equation can be multidimensional. The implementation of SVM refers to the techniques of mathematical programming & kernel functions. This when extended to regression technique we use another function called ε-insensitive loss function.
PageRank Algorithm
The most common algorithm used by search engines is this PageRank Algorithm. It classifies and ranks the pages according to their importance which is derived by the importance or ranks of the pages it is linked to. It is an unsupervised algorithm. The most common variant of this algorithm is the Random Surfer Model which is described below:
In this model, the user clicks on any random page A, its rank is then calculated using:
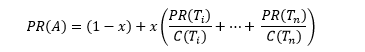
PR (A) is the rank of page A, is the page rank of and so on. is the number of outbound links from page A and x is the damping factor which can have a value from 0-1. This algorithm is patented by Stanford University now & extensively used by Google.
Frequently Asked Questions
What are some major data mining methods and algorithms?
Some data mining methods and algorithms include – apriori algorithm, adaboost algorithm, c4.5 algorithm, expectation maximisation algorithm, k-means algorithm, knn algorithm, naive bayes algorithm, CART algorithm, support vector machines algorithm, pagerank algorithm etc.
What is an algorithm in data mining?
An algorithm in data mining is like any other algorithm where mathematical calculations are performed on data to create a model.
What is the most common algorithm for classification?
The top 5 classification algorithms are – logistic regression, naive bayes classifier, k-nearest neighbors, decision trees/random forest and support vector machines.
What is the most frequently used data mining method?
Prediction is the most frequently used data mining method.g






























 9+ registered
9+ registered 

