Why Use a Trie Data Structure?
A Trie data structure is used for efficient storage and retrieval of words, especially when dealing with a large set of strings. It offers several advantages:
- Fast Search Operations: Tries allow for searching strings in O(m) time complexity, where m is the length of the string. This makes it much faster than traditional data structures like hash tables or arrays for tasks such as autocomplete, dictionary lookups, and spell checking.
- Prefix-based Search: Unlike other data structures, a Trie is designed to efficiently support prefix-based search. This is useful for tasks like predictive text input and prefix matching, where you need to find words that start with a particular prefix.
- Memory Optimization: A Trie can save memory by sharing prefixes of words. Instead of storing each word separately, it stores only one copy of the common prefix, leading to better space utilization when storing words with similar starting characters.
- Sorted Order Retrieval: Since children of nodes in a Trie are sorted alphabetically, traversing the Trie naturally returns words in lexicographical order without needing additional sorting.
Properties of a Trie Data Structure
The Trie data structure comes with several important properties:
Root Node:
- The root node of a Trie is always null or empty and acts as the starting point for all string insertions and searches. It doesn't store any character.
Children of Nodes:
- Each node in a Trie can have up to 26 children (for English alphabets, A to Z). Each child node represents a character, and the combination of nodes forms words in the Trie.
Alphabetical Sorting:
- The children of any node are arranged alphabetically. This property makes it easy to retrieve words in lexicographical order, ensuring efficient word searches and prefix lookups.
Single Letter Storage per Node:
- Every node in the Trie, except the root, stores a single letter of a word. The sequence of nodes from the root to a leaf node represents the complete word stored in the Trie.
End of Word Marker:
- In some implementations, a special marker is added to nodes to indicate the end of a word, ensuring that words that are prefixes of longer words are still recognized as complete words in the Trie.
Representation of a Trie Node
A ‘TrieNode’ class consists of the following things:
- An array of TrieNodes of size 26. Each index represents one character from 26 English alphabets(A - Z).
- A boolean variable ‘isEnd’ representing if this is the last level of your current word.
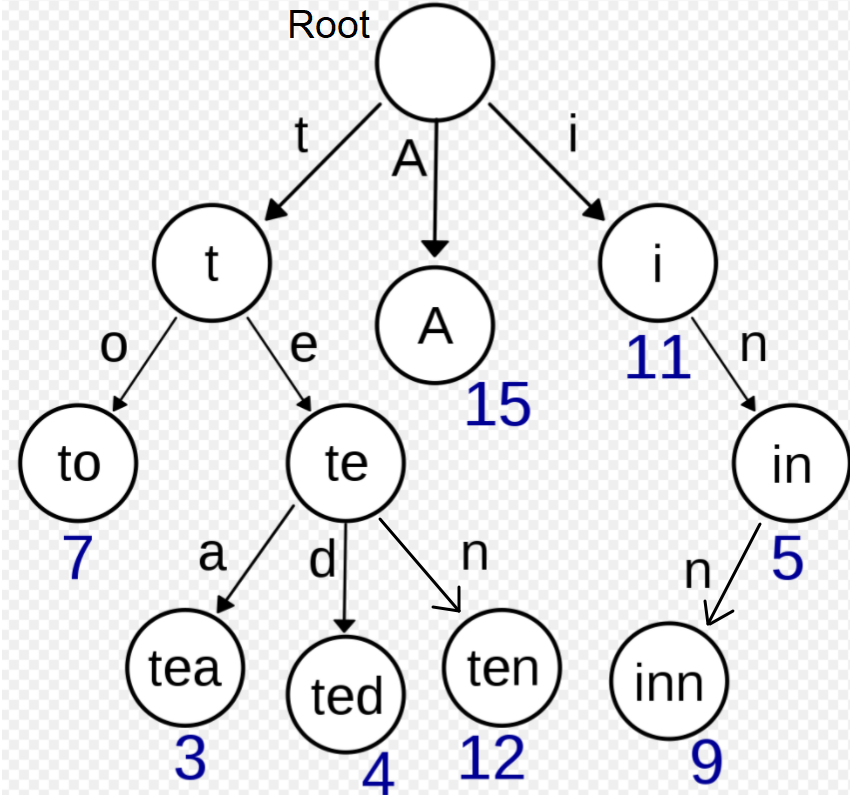
Source: wikipedia
In the above picture - to, tea, ted, ten, inn, A are stored in the Trie.
Operations in a Trie Data Structure
There are three operations we can perform in a Trie:
- Insertion of a word
- Searching of a word
- Deletion of a word
Insertion of a word in a Trie
- Every word starts inserting below the root level.
- If the present character node is already present in the Trie, use that node to form your word. But, if there is no present character node at the current level, make a new TrieNode and add its reference to its parent’s TrieNode array. Remember, in the latter case, you need to update the ‘isEnd’ boolean also.
- The word’s length determines the depth of the Trie Tree.
Searching a word in a Trie
We start comparing the characters of the words with the nodes present in the Trie. Now, there can be the following two cases:
- If there is no node present for the current character at any moment, that means the current word is not present in the Trie.
2. Suppose you reach the end of your word. You need to check if ‘isEnd’ for your current node is set to ‘True’ or ‘False.’ If it’s true, that means the word is present in the Trie else no.
Also see, Introduction to C#
Deleting a Word in a Trie
In trie, we delete any word in a bottom-up manner consider the following cases:
- If the current word is not present in the Trie, your delete operation should not modify the Trie.
- If the current word is present as the prefix to another word, just update the ‘isEnd’ boolean variable of the last character node of your current word.
- If the current word is not present as the prefix to any word, delete all the references of the character’s node in the Trie from the bottom until you find a Node with its ‘isEnd’ variable set to true.
Implementation
#include <bits/stdc++.h>
using namespace std;
const int aSize = 26;
// trie node
struct TrieNode {
struct TrieNode* children[aSize];
/*
isEndOfWord is true if the node represents
end of a word
*/
bool isEnd;
};
// Returns new trie node (initialized to NULLs)
struct TrieNode* getNode(void)
{
struct TrieNode* parentNode = new TrieNode;
parentNode->isEnd = false;
for (int i = 0; i < aSize; i++){
parentNode->children[i] = NULL;
}
return parentNode;
}
/*
If the key is not present, this function
inserts key into the trie.
If the key is prefix of any trie node, just
marks leaf node
*/
void insert(struct TrieNode* root, string key)
{
struct TrieNode* curNode = root;
for (int i = 0; i < key.length(); i++) {
int idx = key[i] - 'a';
if (!curNode->children[idx]){
curNode->children[idx] = getNode();
}
curNode = curNode->children[idx];
}
// Mark last node as leaf
curNode->isEnd = true;
}
// This function returns true if the key is present in trie, else false
bool search(struct TrieNode* root, string key)
{
struct TrieNode* curNode = root;
for (int i = 0; i < key.length(); i++) {
int idx = key[i] - 'a';
if (!curNode->children[idx]){
return false;
}
curNode = curNode->children[idx];
}
return (curNode != NULL && curNode->isEnd);
}
// Returns true if the root has no children, else false
bool isEmpty(TrieNode* root)
{
for (int i = 0; i < aSize; i++){
if (root->children[i]){
return false;
}
}
return true;
}
// Recursive function to delete any key from the given Trie Tree
TrieNode* remove(TrieNode* root, string key, int depth = 0)
{
// If the Trie tree is empty
if (!root){
return NULL;
}
// If the last character of the key is getting processed
if (depth == key.size()) {
/*
This node is no more end of any word after
removal of the given key
*/
if (root->isEnd){
root->isEnd = false;
}
// If given key is not the prefix of any other word
if (isEmpty(root)) {
delete (root);
root = NULL;
}
return root;
}
/*
If not the last character, recur for the child
obtained using the ASCII value
*/
int index = key[depth] - 'a';
root->children[index] = remove(root->children[index], key, depth + 1);
/*
If the root does not have any child (it's only child got
deleted), and it is not the end of another word.
*/
if (isEmpty(root) && root->isEnd == false) {
delete (root);
root = NULL;
}
return root;
}
int main()
{
/*
Input keys (consist of only 'a' through 'z'
and int lower case only)
*/
string keys[] = { "man", "a", "where","answer", "any", "by","bye", "their", "hero", "heroplane" };
int n = sizeof(keys) / sizeof(keys[0]);
struct TrieNode* root = getNode();
// Construct trie
for (int i = 0; i < n; i++){
insert(root, keys[i]);
}
// Search for different keys
if(search(root, "the")){
cout << "Yes\n"
}
else{
cout << "No\n";
}
if(search(root, "these"){
cout << "Yes\n"
}
else{
cout << "No\n";
}
remove(root, "heroplane");
if(search(root, "hero")){
cout << "Yes\n"
}
else{
cout << "No\n";
}
return 0;
}

You can also try this code with Online C++ Compiler
Time Complexity
All the operations, including Insert, Delete, and Search function works in O(Word_Length) time because we iterate the entire word and keep inserting the node for each node if it is not present. And as soon we iterate the entire word, out word gets inserted, deleted or searched.
Space Complexity
Implementing trie takes O(Alphabet_Size * numberOfWords * Word_Length) because we are inserting each word in the Trie and each alphabet of the word takes up some memory.
Advantages of Trie Data Structure
- Efficient Search Operations: Tries allow for quick searches with a time complexity of O(m), where m is the length of the word, making it highly efficient for string lookups.
- Prefix Matching: Tries are ideal for prefix-based searches, enabling operations like autocomplete and word suggestions based on input prefixes.
- Lexicographical Order: Since the children of nodes are stored alphabetically, retrieving words in sorted order is straightforward without additional sorting algorithms.
- Memory Efficiency for Common Prefixes: By sharing prefixes among words, Tries can save memory when storing a large number of words with similar starting sequences.
- Fast Insertions and Deletions: Trie allows for inserting and deleting words in O(m) time, providing quick updates to the data structure.
- No Collisions: Unlike hash tables, where different keys may produce the same hash (causing collisions), Tries avoid this issue as each node uniquely represents a letter.
Disadvantages of Trie Data Structure
- High Memory Usage: Although Tries save space through prefix sharing, they can still consume significant memory due to the potential number of nodes (especially when storing sparse data).
- Complex Implementation: Tries are more complex to implement compared to other data structures like hash tables or arrays, requiring careful handling of nodes and children.
- Inefficient for Small Datasets: For small datasets or a small number of strings, using a Trie may be overkill compared to simpler data structures that achieve similar performance.
- Wasted Space: If many words don’t share common prefixes, a Trie can result in a lot of wasted space, as many nodes will only have a single child.
- Difficult to Scale for Non-alphabetic Data: Tries are typically designed for alphabet-based data. Extending the data structure for other character sets (like Unicode or numbers) can complicate its design and increase memory usage further.
Frequently Asked Questions
Why is it called a trie?
Trie is derived from the word "retrieval," reflecting its primary purpose of efficiently retrieving strings using their prefixes.
What is a trie used for?
Trie is used for efficient storage and retrieval of strings, supporting operations like prefix-based searches, autocomplete, and dictionary implementations.
Why is trie better than Hashmap?
Trie is better than Hashmap for prefix-based searches, as it allows for faster lookups of keys with common prefixes without hash collisions.
Is trie a good data structure?
Trie is an excellent data structure for managing large sets of strings efficiently, especially for tasks involving prefix searches or lexicographical sorting.
Conclusion
In this blog, we have covered the following things:
- What operations we can perform on a Trie.
- How to implement all three functions of Trie.
- Time Complexity and Space Complexity of Trie.
If you want to learn more about Heaps and practice some questions requiring you to take your basic knowledge on Heaps a notch higher, you can visit our Guided Path for Trie.
Until then, All the best for your future endeavors, and Keep Coding.






























 9+ registered
9+ registered 

