Trie insertion and search operation code in C++
// program for trie insertion and search in C++
#include<bits/stdc++.h>
using namespace std;
struct TrieNode
{
char data;
// word count
int wc;
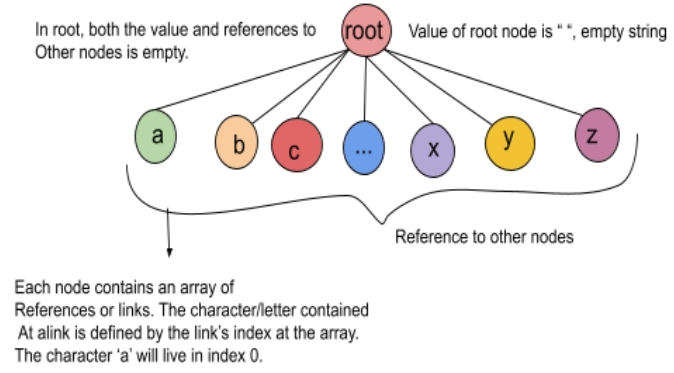
TrieNode *child[26];
};
// Pool of 100K Trienodes is created
TrieNode nodepool[100000];
// Root of Trie is created globally
TrieNode *root;
// Always points to next free Trienode of the trie
int poolcount;
// Initializer function
void init()
{
poolcount = 0;
root = &nodepool[poolcount++];
root->data = '/';
/*
loop from i-0 till 26
as there are 26 alphabets in total
*/
for(int i=0;i<26;++i)
{
root->child[i] = NULL;
}
}
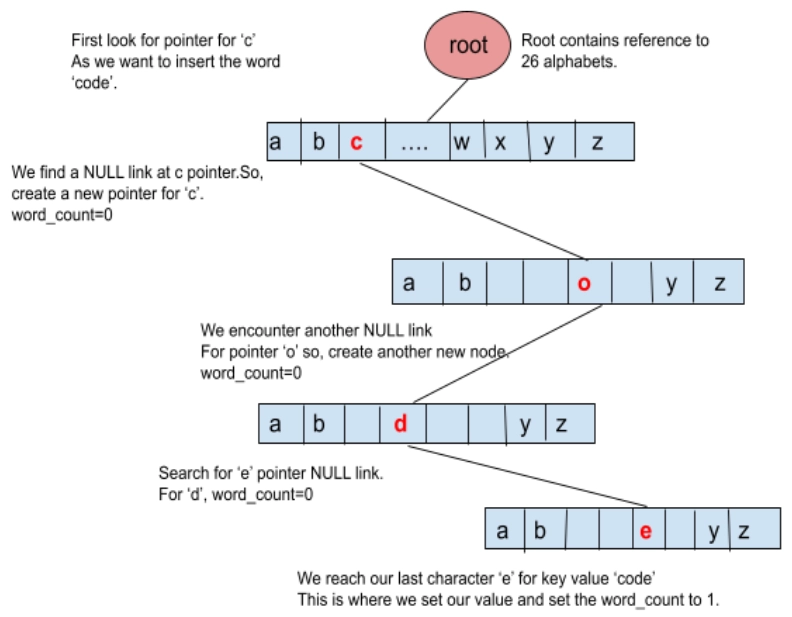
TrieNode *getNode(char c)
{
TrieNode *newnode = &nodepool[poolcount++];
newnode->data = c;
for(int i=0;i<26;++i)
{
newnode->child[i] = NULL;
}
newnode->wc=0;
return newnode;
}
/**
Insert function inserts the key values
letter by letter in the trie
**/
void insert(char *str)
{
TrieNode *curr = root;
int index;
for(int i=0; str[i]!='\0'; ++i)
{
index = str[i]-'a';
if(curr->child[index]==NULL)
{
curr->child[index] = getNode(str[i]);
}
curr->child[index]->wc += 1;
curr = curr->child[index];
}
}
/*
The boolean function returns true.
if the key is found otherwise
false for the search key
*/
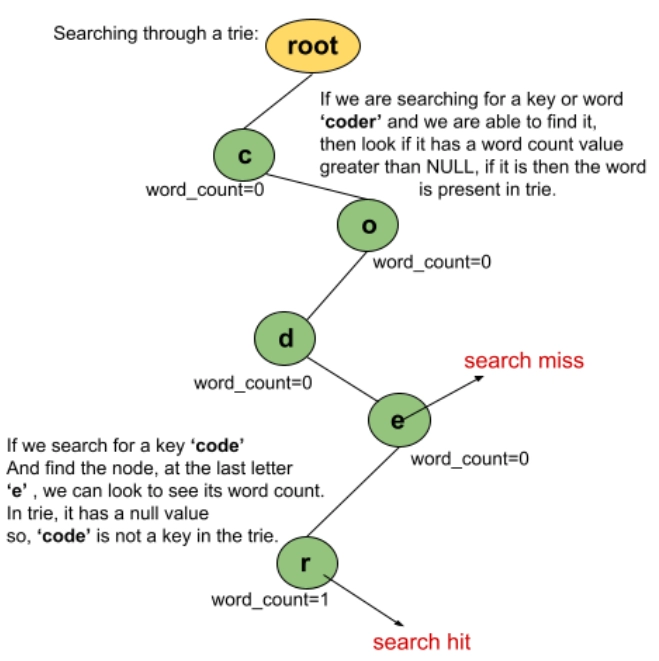
bool Search_key(char *s)
{
TrieNode *curr = root;
int index;
for(int i=0; s[i]!='\0'; ++i)
{
index = s[i]-'a';
if(curr->child[index]==NULL || curr->child[index]->wc == 0)
{
return false;
}
curr = curr->child[index];
}
return true;
}
int CountPrefix(string str)
{
TrieNode *curr = root;
int index;
for(int i=0; str[i]!='\0'; ++i)
{
index = str[i]-'a';
// No string with given prefix is present
if(curr->child[index]==NULL || curr->child[index]->wc == 0)
{
return 0;
}
curr = curr->child[index];
}
return curr->wc;
}
int main()
{
init();
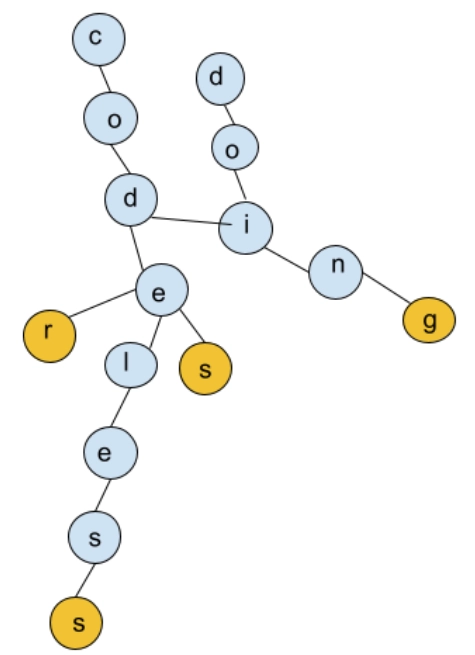
char arr[10] = {'c','o','d','e','l','e','s','s'};
char brr[10] = {'c','o','d','e','r'};
char crr[10] = {'c','o','d','e','s'};
char drr[10] = {'c','o','d','i','n','g'};
char err[10] = {'d','o','i','n','g'};
char frr[10] = {'c','o','d','e'};
/**
Above key values are inserted.
in trie
**/
insert(arr);
insert(brr);
insert(crr);
insert(drr);
insert(err);
insert(frr);
/**
Search operation is done.
printing the prefixes count with
Their count in the trie.
**/
cout<<"Program for trie insertion and search :"<<"\n";
printf("No of strings with prefix'c' = %d\n",
CountPrefix("c"));
printf("No of strings with prefix 'er' = %d\n",
CountPrefix("er"));
printf("No of strings with prefix 'code' = %d\n",
CountPrefix("code"));
printf("No of strings with prefix 'coding' = %d\n",
CountPrefix("coding"));
printf("No of strings with prefix 'codes' = %d\n",
CountPrefix("codes"));
printf("No of strings with prefix 'coder' = %d\n",
CountPrefix("coder"));
return 0;
}
Output:
Search
No of strings with prefix'c' = 5
No of strings with prefix 'er' = 0
No of strings with prefix 'code' = 4
No of strings with prefix 'coding' = 1
No of strings with prefix 'codes' = 1
No of strings with prefix 'coder' = 1
Time and space complexity for trie insertion and search
Trie insertion Time Complexity: O(M * N)
Trie search Time Complexity: O(M * N)
Where ‘M’ is the longest word length and ‘N’ is the total number of words. The worst-case time complexity for searching the record associated with the key is O(M * N), and insertion of key-value pair(key, record) also takes O(M * N).
The main points to ponder why the time complexity squeezes with trie is:
- As a trie grows in size, less work needs to be done to add a value since the “intermediate nodes” or the tree branches have already been built up.
-
Each time we add a word’s letter, we need to look at 26 references since there are only 26 letters in the alphabet. This number never changes in the context of our trie, so it is a constant value.
Space complexity: O(M * N)
The space complexity is O(M * N). As at max the size required can be of the maximum word length multiplied with the total possible words.
Advantages of trie
- Tries are like tree data structures. It can perform insert, search, and delete operations in O(N) time, where ‘N’ is the word/ key-value length.
- Key values can be easily printed in alphabetical order, which is not possible in hashmaps.
- Prefix-search can be easily performed in tries.
FAQs
-
What is the fundamental difference between hash tables and trie?
One significant difference between hash tables and tries is that a trie doesn’t need a hash function; every path to an element is unique. However, a trie takes up a lot of space with empty or NULL pointers.
-
What is the time complexity of trie insertion and search?
The complexity of the search, insert and delete operation in tries is O(M * N), containing, let’s where M is the length of the longest string and N is the total number of words.
-
What is trie used for?
Trie data structure is used to store the strings or key values which can be represented in the form of string. It contains nodes and edges. At max, 26 children connect each parent node to its children.
-
Does Google use trie for some purpose?
Yes, Google also uses trie to store each word or string value.
-
How is trie pronounced?
A trie is generally pronounced as “try”, although it is derived from the word “retrieval”.
Key Takeaways
In this article, we have discussed trie insertion and search techniques, a discussion around its time and space complexity, and finally, understand why every time trie wins over trees. If you want to practice more such problems then you can visit our Code Studio.
But this isn’t the end, right?
Keeping the theoretical knowledge at our fingertips helps us get about half the work done. To gain complete understanding, practice is a must. A variety of coding questions from interviews are available. If you think that this blog helped you, then share it with your friends!.
Happy learning




























 8+ registered
8+ registered 

