Do you think IIT Guwahati certified course can help you in your career?
Introduction
Nowadays, for any Software engineering interview, there is a round dedicated to System Design. In the interview, the interviewer will check the problem-solving skills of candidates. System Design is one of the ways to check the problem-solving ability on a larger scale. In a system design interview, the interviewer will present a problem in front of you, and you are expected to gather knowledge about the system and finally propose the best possible solution.
Some common system design questions are Designing Netflix, Designing Uber, Designing URL Shortener, etc. In this blog, we will discuss Twitter system design in detail.
System Design is all about designing a system's components, architecture, modules, and data flow pattern from one element to another. In System Design, the focus is on solving a problem by specifying all necessary components for a complete system.
If you are a beginner in system design, check out this blog, System Design Concepts For Job Interviews, to understand the concepts better.
Twitter
Before approaching the solution, it is essential for the candidate to deep dive into how Twitter works and know the basic functionalities.
Twitter is a social networking service where a user can post and read posts which are called tweets. Over the years, there has been an exponential increase in the user base of Twitter. The frequent tweets about various political issues, tech news, etc., add to heavy daily traffic. On average, 600 tweets are generated per second, and almost 600,000 tweets are read by the users every second.
An average user has nearly 200 followers, and the celebrities can have followers in millions. Hence, Twitter deals with a massive amount of tweets and has a heavy user base.
The basic functionalities of Twitter are as follows:-
Create an account
Create tweets
Read tweets
Users can delete their tweets but not update/edit their posted tweets.
Users can comment, retweet, share, and like the tweets.
View timelines: Home Timeline, User Timeline, Search Timeline
Follow other users
Users must be able to check the trending hashtag in their region.
Twitter System Design
Generally, candidates attempt to design a monolithic application, i.e., a single unified unit, in a System Design Interview. However, designing a service like Twitter as a monolithic service shows that the candidate is not experienced in designing distributed systems. Nowadays, companies also have started building applications using microservices architecture, i.e., breaking the service into a collection of smaller independent units.
Hence, the candidates should discuss Twitter system design as a microservices architecture instead of a monolithic architecture.
After going through the functionalities, we can notice the following:-
Operations are read-heavy rather than write.
Space won't be an issue as there is a character limit of 140.
The system need not be strongly consistent. Eventual consistency would be fine as it won't be an issue if the user sees the tweet a bit delayed.
Requirements
Before jumping into the solution, let's discuss the requirements for the application.
Before going to the optimized approach, one can always start by giving the naive approach to design the platform by communicating the initial thoughts on the system. We can start with a system supporting a few hundred users and scale it afterward.
The basic requirement for the platform would be a Database. One can go for relational databases like MySQL, MS SQL Server, or cloud relational databases like Google Cloud SQL, etc. This database will contain the user table and tweet table.
User table (userID, userName): It will store the information about the user like the userID and the userName. Here the primary key can be the userId attribute.
Tweet table(tweetID, content, userID, date): It will store the tweet's id, the tweet's content, user id, and date tweeted. Here the primary key can be the tweetId attribute. When a user tweets, the tweet gets stored in the tweet Table along with the userID.
Relationships established between tables:
1. Self-referential relationship: Self-referential relationship is the relationship of one record with other records in the same table. Here the self-referential relationship is established in the user table.
2. User table and tweet table: It will be a one-to-many relationship between the user and the tweet table. The foreign key will be userID in this case.
Limitation Of Naive Approach
In the above approach, every time a user wants to get the feed, the select query must be applied to the tweet table. This is not practically possible due to the large user base. In this approach, the loading and displaying results will not be very optimal, leading to a bad experience for the user.
High-Level Design
As we had mentioned above, the operations in Twitter are read-heavy. So, the system we design should allow the user to go through the tweets efficiently. To make the system scalable, we would be using horizontal scaling as they are more resilient and scale well as the users increase. We can create three tables in the database: user table, tweet table, and followers table.
User table: The user's information is stored when a user creates a profile on Twitter.
Tweet table: The tweets will be stored here, and they will have a one-to-many relationship with the user table, as discussed above.
Followers table: When a user follows another user on Twitter, it gets stored in the followers table. Caching is done here to avoid redoing the same operations and save time. It also has a one-to-many relationship with the user table.
Architecture and Components
Now let's discuss the platform's architecture, components used for the client app, caching, etc.
Client App
The Twitter app is built as a progressive web app (PWA) to work on desktop as well as mobile devices. Features like push notification, immediate loading, offline browsing, etc., are achieved using the service workers. React, along with Redux, is used to handle Twitter's data on the frontend. A proxy server called a reverse proxy, used to retrieve resources on behalf of a client from one or more servers, is used to create a tweet on the client-side.
Backend
Backend is designed using node.js and Express on the server-side. The server interacts with Redis Clusters and the database. For the APIs (Application Programming Interface), Rest architecture is used.
Login API- Post API to authenticate the user.
Signup API- Post API to create a user.
Get all followers- Get API /api/users/${userName}/followers?page=1&size=30
Get all following- Get API api/users/${userName}/followees?page=1&size=30
Get all Tweets- Get API /api/users/${userName}/tweets?page=1&size=30
Create a tweet- Post API /api/users/${userName}/tweets
Twitter uses various databases depending on the requirements. The databases used are:-
Hadoop - Used to store massive data like trends Analytics, storing user logs, recommendations, etc.
MySQL and Manhattan as master DB - Used to store data of end-users. Manhattan is a NoSQL database used to store tweets, messages, etc. It can provide real-time multi-tenant scalable distributed DB and serve millions of queries fast.
MemCache and Redis - Used to store cache data which is used to generate a timeline.
FlockDB - Used to store social graphs, i.e., how users are connected.
Metrics DB- Used to store data metrics of Twitter.
BlobStore - Used to store binary large objects and images, videos, and other files.
Content Delivery Network (CDN)
CDN is used to serve the tweet media content over a local network in particular regions.
Now let's see how Twitter performs functions like searching, creating user timelines, etc.
Generate user timeline
How does the user timeline work on Twitter?
To generate the user timeline, we have to get the UserId from the user table and map it to the userId in the tweet table. This returns a list of the tweets, including the retweets made by the user, etc. The tweet list is then sorted by date and time and then displayed on the user timeline.
This approach won't be efficient for a large user base. So some of the user timeline queries are stored in the Redis server for caching. This avoids the need for direct access to the database and increases the application performance. This caching layer is useful when some other user wants to access our tweets. The caching layer directly gets the data from the Redis server and makes it accessible to the other user.
Generate home timeline
How does twitter display all the tweets on the user's home page?
The home timeline would contain the tweets of the user and the pages or the users that they follow. To generate the home timeline, first, collect the userIds of the account the user is following. After that, fetch the tweets made by those userIDs and merge the tweets in the order of the time generated.
As you might have guessed, the above approach is going to serve a considerable time overhead. This is because the Twitter home page loads fast, and the queries will become heavy on the database when the tweet table grows to millions. To solve this issue, the fanout approach is used.
Fanout Approach: When a user makes a tweet, it is injected into their followers' timeline in the fanout approach. In this process, queries are not required, and the time overhead issue is resolved here. This injecting of tweets is made possible by a Redis server that helps at the caching layer, saves some of the user's tweets queries as cache, and uses them as and when required.
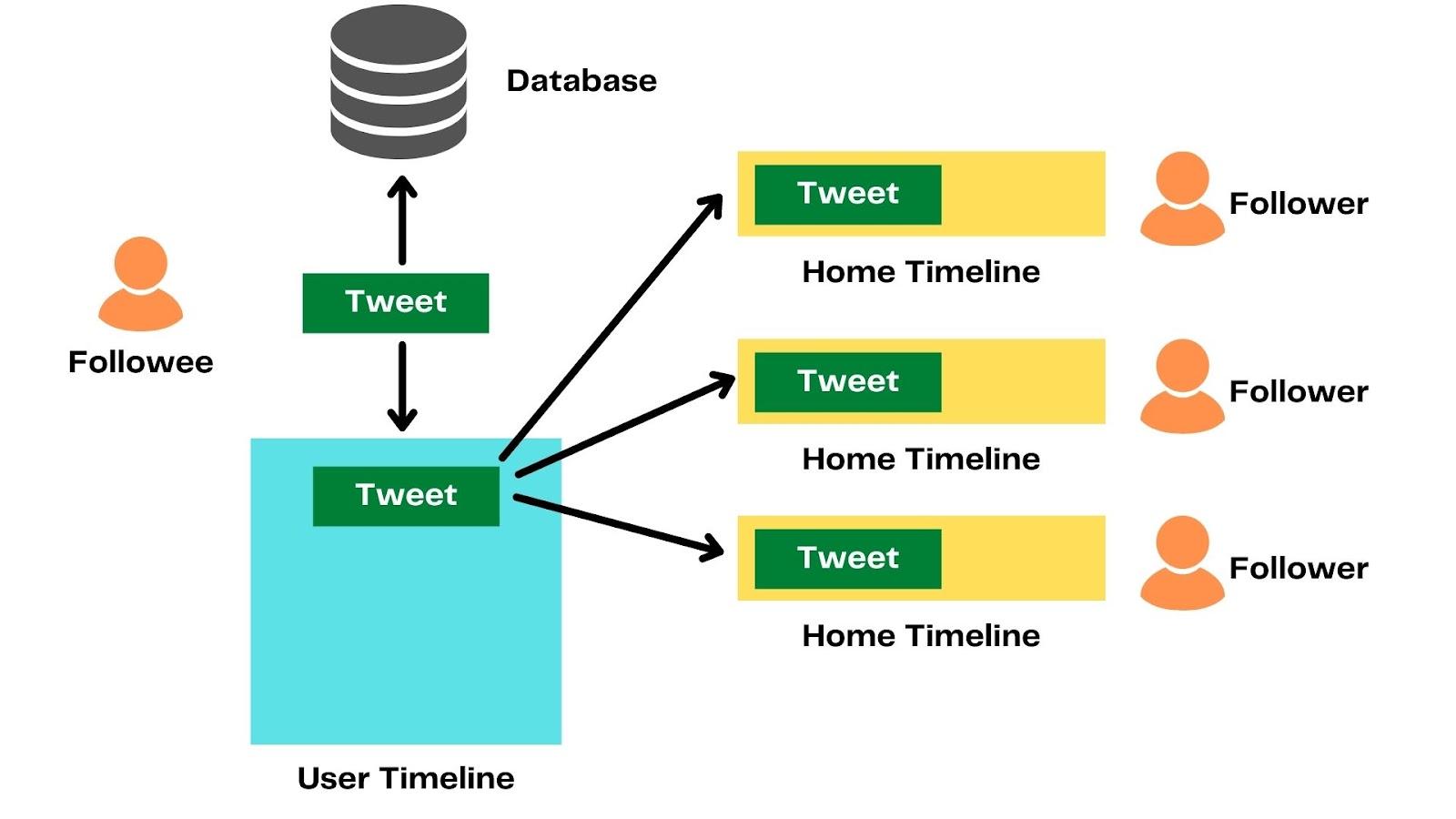
Fanout Approach
Let's understand fanout with the help of the figure. Suppose three people follow a user, and this user has data stored in the cache. When the user tweets through the load balancer, the tweet will flow into backend servers. The server node will save the tweet in the database and fetch all the user's followers from the cache.
The server node will then inject this tweet into the in-memory timelines of the followers through the fanout process. And finally, the home timeline is updated.
Is the above method efficient for a celebrity with millions of followers?
It is not possible to update millions of home timelines efficiently, so the fanout approach fails here. In this scenario, follow the following steps:-
Generate the home timeline of a follower of the celebrity with everyone except the celebrity tweets
In the cache, maintain the list of celebrities the user follows and the common people the user follows.
When a celebrity makes a tweet, get the celebrity from the celebrity list and fetch the tweet from the user timeline of the celebrity.
Merge the celebrity's tweet at runtime with the home timeline of the follower.
To optimize this further, timeline generation can be avoided for users who haven't logged in for a long time.
Generate search timeline
How does searching work on Twitter?
Earlybird is the system used to manage real-time tweet-searching or hashtags by Twitter. It does an inverted full-text indexing operation when a tweet is posted. To do this, the tweet is treated as a document, splits them into words, and then builds an index for each word. This indexing is done at a vast and distributed table where each word references all the tweets that contain that particular word. As the index is an exact string-match and unordered, it is speedy.
Twitter tweets are handled through a distributed approach rather than a single big system as it has to take a vast amount of tweets per second. So Twitter uses the scatter and gather strategy where multiple data centers that allow indexing is set up.
When Twitter receives a query, it sends the query to all the data centers. Then it queries every Early Bird shard and checks if the content matches with the query. All the matches are then returned as results. This result is displayed in the search timeline after sorting, merging, and ranking. The ranking is done based on the number of retweets, replies, and the popularity of the tweets.
Trending Hashtags
How does Twitter decide trending hashtags in real-time?
Twitter uses the frameworks: Apache Storm and Heron to decide the trending hashtags. The applications generate a real-time analysis of the tweets sent on Twitter to determine the trending hashtags.
This process used for the data analysis of Twitter is called the "Trending Hashtags" method. In this process, the number of mentions of a particular hashtag and the total time to get reactions are considered.
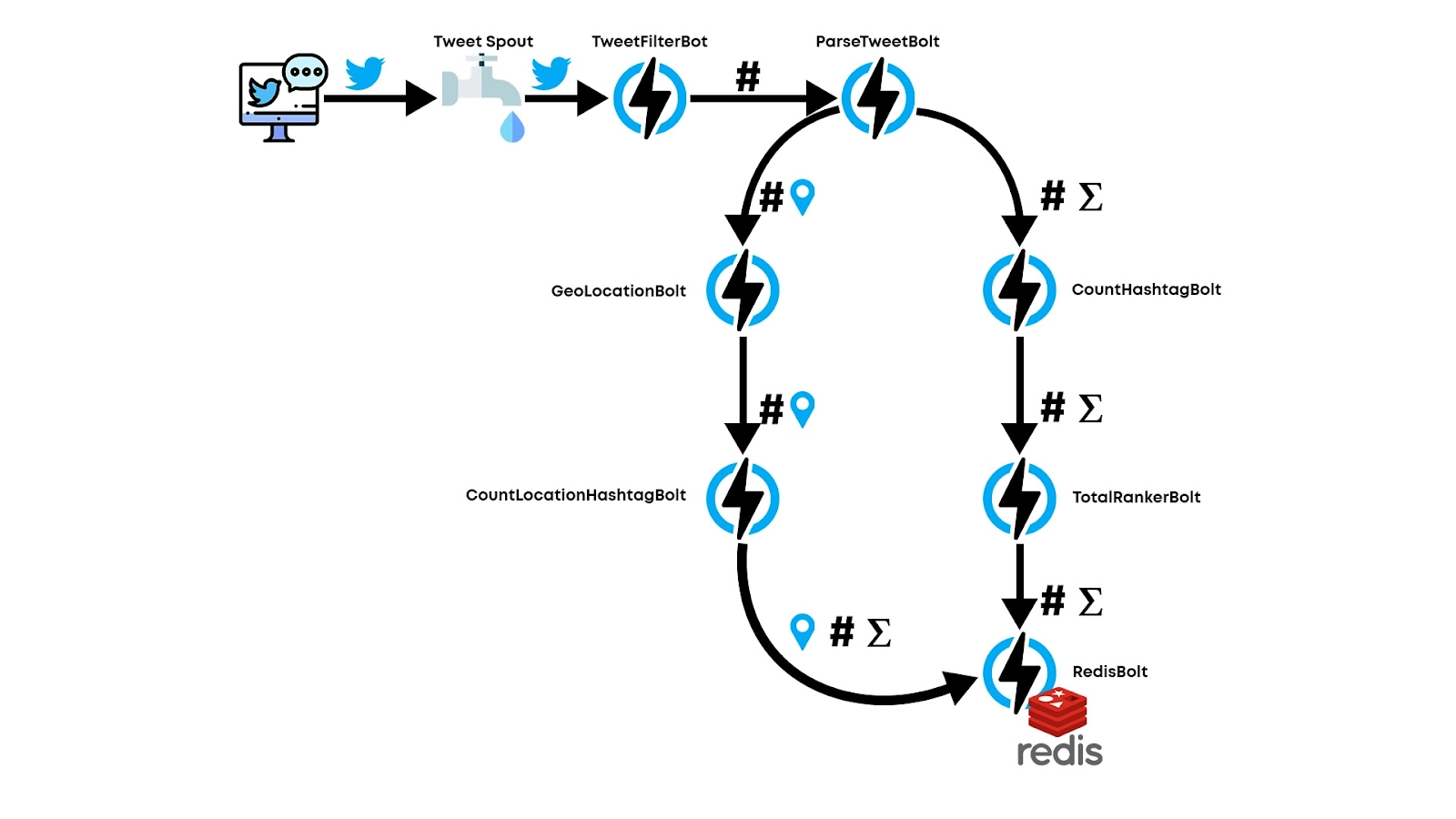
Trending Hashtags method
Let's look at the individual components of the Trending hashtags method.
TweetSpout: Component used to issue the tweets in the topology.
TweetFilterBolt: The component reads the tweets and filters the tweets issued by TweetSpout. Filtering is performed only on those tweets that contain coded messages using the standard Unicode. Violation checks are also performed at this stage.
ParseTweetBolt: The component issues the filtered tweets as tuples with at least one hashtag present.
CountHashtagBolt: Processes the parsed tweets and counts each hashtag. This is done to get the hashtag and the number of references to it.
TotalRankerBolt: Ranking of all the counted hashtags is performed.
GeoLocationBolt: It identifies the location of the parsed tweet.
CountLocationHashtagBolt: It is similar to the CountHashtagBolt component with an extra location parameter.
RedisBolt: The component inserts data into Redis.
Overview of Twitter System Design
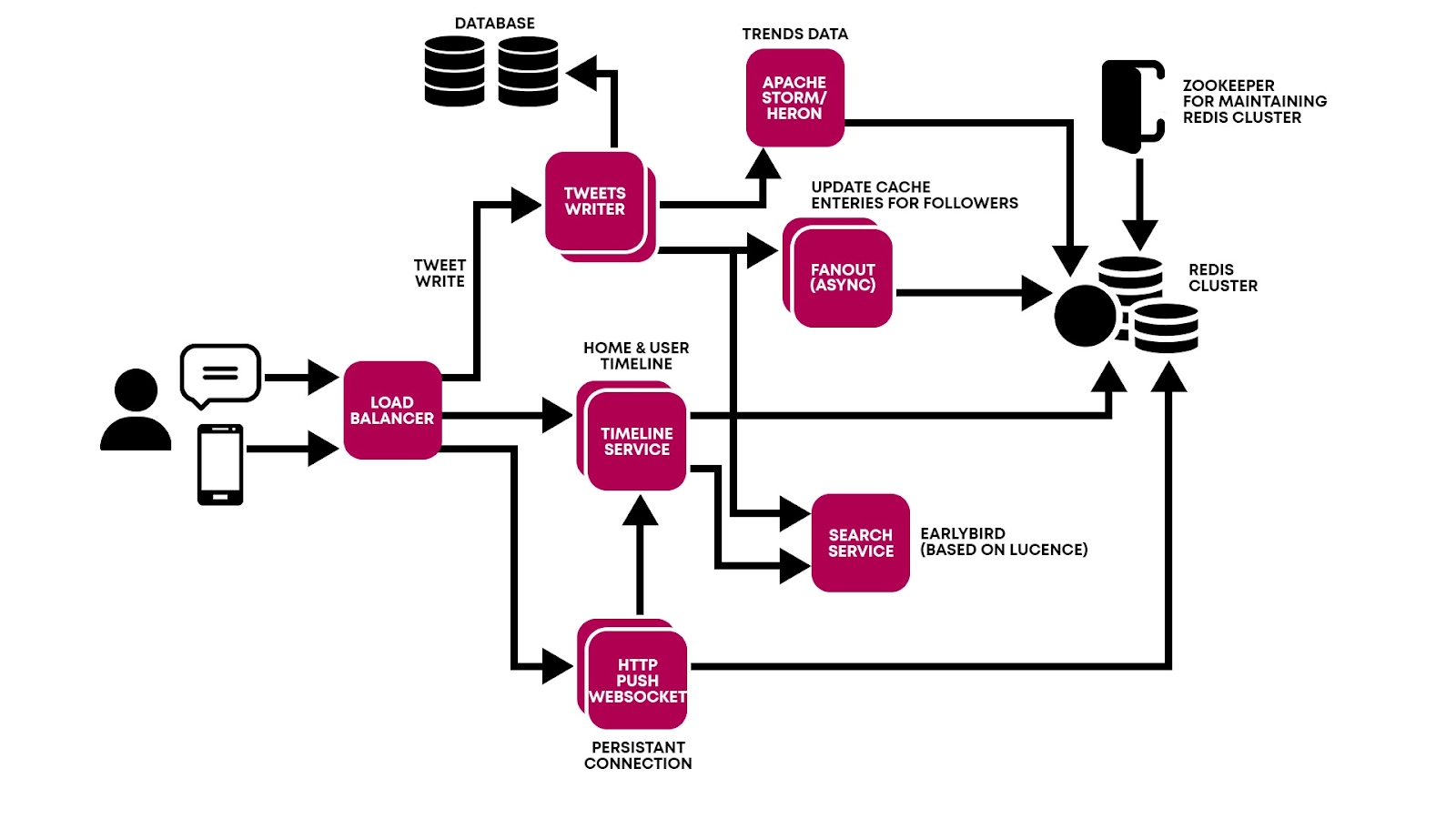
Twitter System Design
When a tweet is made, the API call hits the load balancer, and then that call hits the Twitter writer. The Twitter writer sends the copy of tweets to the database, Apache storm (for analyzing trending hashtags), the fanout service (to update the timeline), and the search service (for indexing).
If the user wants to search for something, an API call is made to the load balancer, and then the request is forwarded to the timeline service. The call is then transferred to the search service, where the searching operation is efficiently performed using the scatter and gather strategy. Similarly, when the user requests a home timeline or user timeline, the request reaches the timeline service, which directly approaches Redis. Redis figures out the appropriate timeline and returns the result in JSON (JavaScript Object Notation) format.
HTTP push WebSocket is responsible for handling the real-time connection with the application. This service should be able to handle millions of connections at any given point in time.
ZooKeeper is a highly reliable coordination service for distributed components. Twitter runs about thousands of nodes in any given cluster for Redis. Most of the data is stored in Redis in big clusters, which requires coordination between the nodes. It also keeps track of which all servers are online/ offline and coordinates between the nodes accordingly.
Frequently Asked Questions
What is meant by caching?
Caching is a process in which copies of data are a temporary storage location (or cache) to have faster access to the data.
How can sharding of data be done to manage the gigantic data?
The sharding of data can be done based on the following parameters: userID, tweetID, and tweetID & create time.
What is the difference between horizontal and vertical scaling?
In horizontal scaling, more machines are added to the pool of resources. In vertical scaling, more power is added to the existing machine.
What is meant by sharding?
Sharding is the horizontal scaling of a database system that is accomplished by breaking the database up into smaller chunks. These chunks are called "shards," separate database servers containing a subset of the overall dataset.
What is meant by the fanout approach?
Fanout approach is a way by which messages are broadcasted to multiple locations parallelly.
Conclusion
This was all about Twitter system design. This blog covered the basic features and components of Twitter. You can now try extending the discussion to various other aspects like notifications, advertising, messaging, etc.
Now that you know the Twitter system design approach, go ahead and try out some Important Interview Questions asked by various product-based companies like Oracle, Facebook, LinkedIn, Twitch, etc.






























 9+ registered
9+ registered 

