Do you think IIT Guwahati certified course can help you in your career?
Introduction
Machine learning (ML) is a subset of artificial intelligence (AI) that enables software programs to grow increasingly effective at predicting outcomes without explicitly programming them to do so. Technically, the study of computer programs that use algorithms and statistical models to learn through inference and patterns without being explicitly programmed is referred to as machine learning.
So, how does the Machine Learning algorithm work? A machine learning algorithm is taught by forming a model using a training data set. When new input data is fed into this algorithm, it tends to predict based on the model. The accuracy of this prediction is then determined. And as soon as this accuracy meets acceptable levels, the ML algorithm is ready for deployment.
What is Machine Learning?
Machine Learning (ML) is a branch of artificial intelligence (AI) that enables computers to learn from data and make predictions or decisions without being explicitly programmed. It focuses on developing algorithms that improve automatically through experience.
ML models analyze large datasets, identify patterns, and make data-driven predictions. It is widely used in applications such as spam filtering, recommendation systems, fraud detection, and self-driving cars.
Machine Learning is categorized into three main types:
Reinforcement Learning – Models learn by interacting with the environment and receiving rewards. (e.g., Game-playing AI like AlphaGo)
ML continues to evolve, driving innovations in automation, decision-making, and predictive analytics across industries.
Types of Machine Learning
In an era of excessive usage of artificial intelligence and machine learning, it is vital to distinguish between different forms of machine learning. Classical machine learning is usually categorized by how an algorithm learns to improve its prediction accuracy. It may now be classified in various ways. The three basic acknowledged categories of Machine Learning are supervised learning, unsupervised learning, and reinforcement learning. In this article, we'll explore these categories in detail, one at a time.
Supervised Machine Learning
Unsupervised Machine Learning
Semi-Supervised Machine Learning
Reinforcement Learning
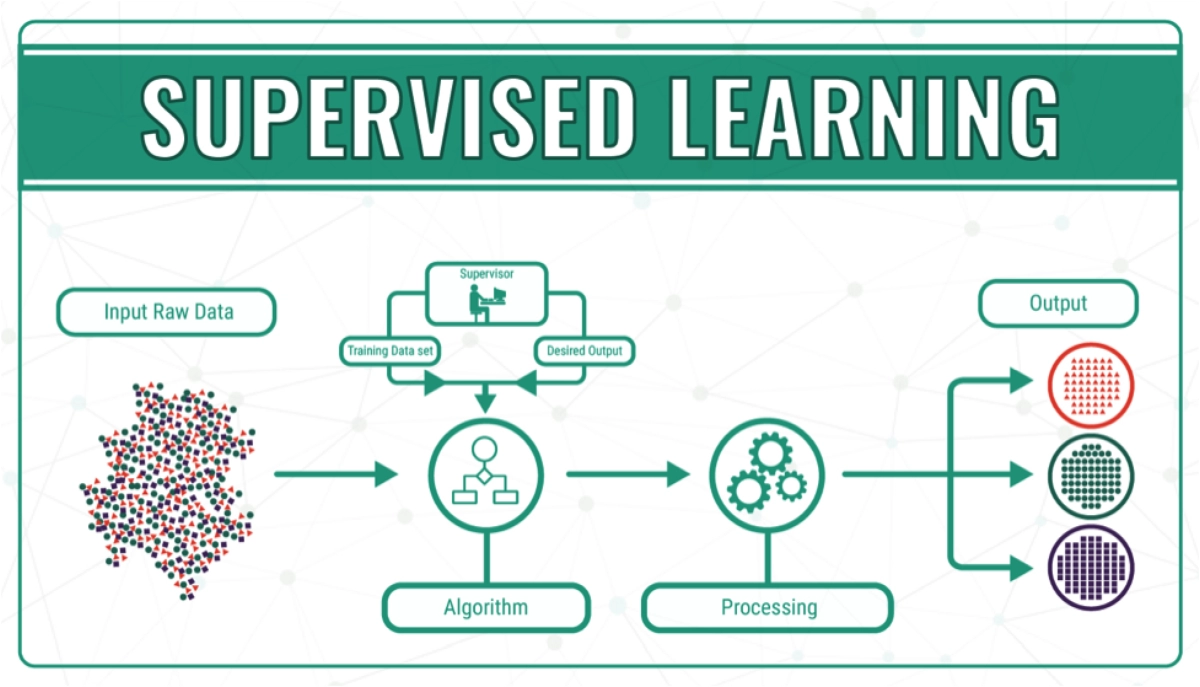
Supervised Machine Learning
Today, the most prevalent category of machine learning, arguably, is supervised learning. In most cases, novice machine learning practitioners will start with supervised learning algorithms. Supervised Machine Learning is a learning method that uses labeled training data to predict outcomes for unlabeled data.
Source:bigdata-madesimple
Supervised machine learning algorithms are characterized by using labeled datasets to train algorithms that properly segregate data or predict outcomes. As input data is fed into the model, the weights are adjusted until the model is well-fitted, which occurs as part of the cross-validation process.
Categories of Supervised Machine Learning
There are two key domains where supervised machine learning is often useful: classification and regression. Thus Supervised Learning is split into two different categories.
Classification Classification makes use of an algorithm to properly allocate test results to specific groups. It detects certain entities within the dataset and attempts to infer how those items should be labeled or described. In classification tasks, our output often comprises groups or categories. Examples of such groups produced by classification include demographic data such as marital status, gender, or age. Classification of an email as spam or not is also a common use case. Some of the common algorithms used under this category of problems include Logistic Regression, Support Vector Machines[SVM], K-Nearest Neighbours[KNN], and Naïve Bayes, etc.
Regression Regression is a technique for determining the connection between dependent and independent variables. It is a statistical method that aims to identify the critical link between dependent and independent variables. A regression algorithm aims to predict a continuous number such as sales, income, or test results. Some of the popular regression algorithms include Linear regression, Ridge regression, Decision Tree regression, etc.
Applications
Below are some of the common use cases you'll find of supervised learning in today's world.
Spam detection Companies can train databases to spot patterns or abnormalities in fresh data using supervised classification algorithms, allowing them to efficiently categorize spam and non-spam email exchanges.
Image/Object recognition Supervised learning methods may be used to find, isolate, and categorize objects in movies or pictures, making them valuable in computer vision techniques and visual analysis.
Predictive analytics The use of Predictive analytics enables organizations to forecast certain outcomes depending on a particular output variable, assisting business executives in justifying actions or pivoting for the benefit of the firm.
Unsupervised Machine Learning
Unsupervised learning is diametrically opposed to supervised learning. There are no labels on the data. Instead, our system would be fed a large amount of data and given the means to grasp the data's features. It analyzes and clusters unlabeled datasets using machine learning methods. These algorithms uncover hidden patterns or data groupings.
The fact that the vast majority of data in the world is unlabeled makes unsupervised learning such an exciting field. Intelligent algorithms that can make sense of our large datasets of unlabeled data are a big source of potential profit for many enterprises. This alone has the potential to increase production in a variety of industries.
Categories of Unsupervised Machine Learning
Unsupervised learning models are used primarily for three kinds of problems: clustering, association, and dimensionality reduction.
Clustering Clustering is a data mining technique that organizes unlabeled data into groups based on similarities and differences. Clustering techniques are used to arrange raw, unclassified data items into groups characterized by information structures or patterns.
Association This is a rule-based approach for determining associations between variables in a given dataset. These methodologies are commonly used in market basket analysis, helping businesses better understand the linkages between various items. Recommendation engines on multiple sites are the best-known example of this.
Dimensionality reduction While more data typically gives more accurate findings, it can also influence the performance of machine learning algorithms (overfitting) and make the visualization of datasets challenging. Dimensionality reduction is a strategy that is employed when the amount of characteristics, or dimensions, in a given dataset is excessive. It minimizes the amount of data inputs to a reasonable quantity while keeping the dataset's integrity as much as feasible.
Applications Unsupervised Machine Learning
The following are some of the most popular real-world uses of unsupervised learning:
Anomaly detection Unsupervised learning methods can sift through enormous volumes of data to find anomalous data points. These abnormalities might raise awareness of malfunctioning equipment, human mistakes, or security breaches.
Recommendation engines Unsupervised learning can aid in the discovery of data trends that can be utilized to generate more successful cross-selling tactics by using historical purchase behavior data.
Medical Imaging Unsupervised machine learning gives critical aspects to medical imaging technologies, such as image identification, classification, and segmentation, which are utilized in radiology and pathology to swiftly and effectively diagnose patients.
Semi-Supervised Machine Learning
Semi-supervised machine Learning is a hybrid approach that combines both supervised learning (which uses labeled data) and unsupervised learning (which uses unlabeled data). It leverages a small amount of labeled data along with a large amount of unlabeled data to improve learning accuracy. This method is useful when labeling data is expensive or time-consuming, but large amounts of unlabeled data are available.
Categories of Semi-Supervised Learning
Self-Training
The model is first trained on a small labeled dataset.
It then predicts labels for the unlabeled data and retrains itself using these new labels.
Graph-Based Methods
Uses graph structures to represent relationships between data points.
Labels from known points propagate to unknown points based on similarity.
Generative Models
Assumes data is generated by an underlying probability distribution.
Uses a small labeled dataset to guide the learning of this distribution.
Consistency Regularization
Encourages the model to make similar predictions for small variations of the same data.
Helps improve generalization even with limited labeled samples.
Applications of Semi-Supervised Learning
Medical Diagnosis
Labeled medical data is often scarce, and semi-supervised learning helps improve disease detection models.
Speech Recognition
Most speech data lacks transcriptions, making semi-supervised learning valuable for training models.
Image Classification
Used to improve recognition systems in fields like facial recognition and autonomous driving.
Natural Language Processing (NLP)
Helps train models for sentiment analysis, translation, and chatbots with minimal labeled data.
Web Content Classification
Categorizes news articles, spam detection, and recommendation systems with limited human-labeled content.
Semi-supervised learning is an effective technique for real-world scenarios where labeled data is costly, making it an essential part of modern AI solutions.
Reinforcement Learning
When compared to supervised and unsupervised learning, reinforcement learning is quite distinct. Whereas the link between supervised and unsupervised learning (the presence or absence of labels) is clear, the relationship to reinforcement learning is a little hazier. RL algorithms are about learning the best response in a given situation in order to maximize reward. This ideal behavior is discovered via interactions with the environment and observation of how it reacts.
To put it simply, It is an algorithm that executes a job by attempting to maximize the rewards it receives for its efforts.
Applications Reinforcement Learning
A possible application of RL is any real-world situation in which an agent must interact with an unpredictable environment in order to achieve a certain objective.
Autonomous driving In an unpredictable environment, an autonomous driving system must execute many perceptual and planning tasks. Vehicle route planning and motion prediction are two particular applications where RL might be helpful.
Video games Learning to play video games is one of the most popular applications of reinforcement learning. Consider Google's reinforcement learning applications, AlphaZero and AlphaGo, which learned to play Go.
Managing resources Reinforcement learning is effective in navigating complicated surroundings. It may deal with the necessity to balance various requirements. Take Google's data centers, for example. They employed reinforcement learning to balance the need to meet our power demand while being as efficient as possible, resulting in significant cost savings.
Summary
Here’s a table that sums up the types of machine learning we’ve covered in this post.
Criteria
Supervised ML
Unsupervised ML
Reinforcement ML
Semi-Supervised Machine Learning
Working
Learns by using labeled data
Trained using unlabeled data without any guidance.
Works on interacting with the environment
Combines a small amount of labeled data with a large amount of unlabeled data to improve learning efficiency.
Type of Data
Labeled data
Unlabeled data
No predefined data
Small labeled dataset and a large unlabeled dataset.
Type of Problems
Regression and classification
Association and clustering
Exploitation or exploration
Can be used for regression, classification, clustering, etc., depending on the dataset.
Aim
Calculate outcomes
Discover underlying patterns
Learn a series of actions based on rewards and punishments
Improve model accuracy by leveraging both labeled and unlabeled data.
Application
Risk evaluation, forecast sales
Recommendation system, anomaly detection
Autonomous cars, gaming, healthcare
Medical diagnosis, speech recognition, image classification, NLP, web content classification.
Applications of Machine Learning
Machine learning (ML) is widely applied across various industries and fields, transforming processes, improving decision-making, and creating innovative solutions. Below are some key applications of machine learning:
Healthcare Machine learning is used for diagnosing diseases, predicting patient outcomes, personalized medicine, and drug discovery. It can analyze medical images, genetic data, and patient records to provide insights and automate diagnostic tasks.
Finance and Banking In finance, ML is used for fraud detection, algorithmic trading, credit scoring, and risk assessment. By analyzing transaction patterns and financial data, ML models can identify suspicious activities and predict market trends.
E-commerce and Retail Online platforms use ML for recommendation systems, personalized advertisements, customer behavior analysis, and inventory management. These algorithms analyze user preferences, search history, and purchasing patterns to improve the shopping experience.
Autonomous Vehicles Self-driving cars leverage ML to navigate and make real-time decisions. ML algorithms process data from sensors (e.g., cameras, LIDAR) to identify objects, detect road conditions, and plan driving strategies.
Natural Language Processing (NLP) ML enables language translation, speech recognition, and sentiment analysis. Applications like voice assistants (e.g., Siri, Alexa) and chatbots rely on NLP algorithms to understand and respond to human language.
Cybersecurity ML is used to detect and prevent cyberattacks by identifying unusual network traffic, suspicious user activities, and potential vulnerabilities. It continuously learns from new attack patterns to enhance system security.
Manufacturing and Production ML models help optimize production processes, predict equipment maintenance needs, and improve quality control. Predictive maintenance algorithms reduce downtime by analyzing sensor data and detecting early signs of equipment failure.
Entertainment and Media Streaming services like Netflix and Spotify use ML for content recommendations based on users' viewing and listening history. Algorithms analyze preferences and suggest new shows, movies, or songs.
Machine learning has vast applications, and its potential continues to grow, driving innovation across sectors and improving efficiencies in daily tasks and decision-making processes.
Frequently Asked Questions
What are the 4 types of machine learning?
The four types of machine learning are supervised, unsupervised, Semi-Supervised learning, unsupervised learning, and reinforcement learning.
What is classification in ML?
Classification in ML is the process of predicting categorical labels by assigning input data into predefined classes or categories.
What is the data type in ML?
In ML, a data type refers to the kind of data (e.g., integer, float, string) that can be processed by an algorithm, crucial for feature representation.
Conclusion
Now that we've covered the different types of machine learning, it's crucial to notice that the distinctions between these types of learning frequently overlap. Furthermore, there are several activities that may be simply framed as one type of learning and then turned into a different concept.

































 18+ registered
18+ registered 

