Do you think IIT Guwahati certified course can help you in your career?
Recursion allows codes to get more compact and efficient by calling a similar function inside a function. This is kind of similar to looping functions, however, there are a huge number of differences. Recursion makes coding programs or solutions much faster and simpler.
In data structures, recursion occurs when a function calls itself directly or indirectly. Recursion is typically used when a larger problem can be broken down into smaller, more manageable subproblems.
Recursionalso offers code redundancy, making it much more efficient to read and maintain codes. Understanding recursion well can lead to true mastery over functional programming languages and empower programmers to code certain programs rapidly. Some problems are inherently recursive in nature, thus it is very valuable to know recursive functions to solve them faster.
Besides, recursion is valuable and compulsory in many problems related to advanced algorithms such as tree and graph traversal. Learning the applications of recursion in data structure and how to effectively use recursion to manipulate functions in various programs is the key to a great coding experience. In this article, we will cover the topic Recursion in Data structure: How Does it work & its Types.
What is Recursion in Data Structure?
A recursive data structure can be defined as a data structure that can be broken down into simple or miniature instances of itself. For example, trees are composed of small trees and leaf nodes while lists can contain smaller lists as their elements.
However, recursion in the data structure can be defined as a method through which problems are broken down into smaller sub-problems to find a solution. This is done by replicating the function on a smaller scale, making it call itself and then combining them together to solve problems.
Recursion provides a natural approach in declaring many algorithms and is very valuable in functional programming. Developers can effectively use recursion instead of loop functions such as “for loop” or “while loop”.
C++, PHP, Scala and functional Javascript allow recursive functions or developers to write recursion operations. Every iterative problem can be solved through recursion and every recursive problem can be solved by an iterative approach. This is why the importance of recursion in the data structure is more stressed.
To understand the applications of recursion in data structure or programming, one must first understand a loop. For example, using C++, if we had to create a loop to display all the possible numbers between 14 and 20, then we would have to use the following codes:
This is possible as the loops repeat the function as long as the value of “i” is lesser than 20 due to the use of “for loop”. The starting value is “15” as it is the first number that comes after 14 and the “i++” declaration ensures that every time the loop is repeated, 1 is added to the value of “i”.
When using recursion or recursive functions, we do not need to use “for loop” as the function will call itself. Now, let us recreate this same program using recursion in C++.
With recursion, we won’t need to use ‘for loop’ because we will set it up so that our function calls itself. Let’s recreate this same program, only this time we will do it without ‘for loop’. We will use a recursion loop instead like this:
void numberFunction(int i) {
cout << "Possible Number: " << i << endl;
i++;
if(i<20) {
numberFunction(i);
}
}
int main() {
int i = 15;
numberFunction(i);
}
The above codes show how a recursive function has been made by creating a single call to the “numberFunction” and then it calls itself repeatedly till “i” reaches the last number before 20.
There are 5 important and effective recursion techniques used by programmers. They are as follows:
Tail Recursion
While linear recursion is commonly used, tail recursion offers distinct advantages. In tail recursion, the recursive functions are called at the very end of the process.
Binary Recursion
Binary recursion involves calling functions two times, instead of one after the other. This type of recursion is particularly useful for operations like merging and tree traversal.
Linear Recursion
Linear recursion is the most widely adopted method. In this approach, functions call themselves in a straightforward manner and terminate when a specific condition is met. Essentially, it involves functions making one-time calls to themselves during execution.
Mutual Recursion
Mutual recursion is where one function uses others recursively, leading to functions calling each other. This technique is handy when working with programming languages that don't readily support recursive function calls. In mutual recursion, initial conditions are used for one, several, or even all of the functions.
Nested Recursion
Nested recursion is an exception that can't be easily converted into an iterative format. In this approach, recursive functions pass parameters as recursive calls, resulting in recursions within recursions.
Types of Recursion in Data Structure
The main types of recursion are as follows:
Direct Recursion
Functions in direct recursion call themselves. This procedure comprises a single-step recursive call from within the function. Let us take an example below in C++:
C++
C++
#include <iostream> using namespace std; int solve(int x){ if(x==0) return 1; return x*solve(x-1); } int main() { int y=solve(5); cout<<y; return 0; }
You can also try this code with Online C++ Compiler
We can see that the function solve calls itself till it hits the base condition. It is direct recursion.
Indirect Recursion
Indirect recursion occurs when a function calls other functions, which eventually leads back to the original function. It's similar to a series of functions calling each other to generate a recursive process. Let us look at an example below in C++:
We can see that solve1 calls for solve2, which further calls for solve1 until the base cases get hit. This is indirect recursion.
Tailed Recursion
Tail recursion is a unique form of recursion in which the recursive call is the last operation performed in a function. After the recursive call, there won't be any remaining operations that need to be executed.
We can see that the recursive call is at the end of the function.
Non-Tailed Recursion
Non-tail recursion refers to any form of recursion where the recursive call is not the last operation performed in a function. In this case, after the recursive call, some pending operations still need to be completed.
We can see that after the recursive call has been made, there are still some steps to be done.
Need of Recursion
In computer science, recursion is a common phenomenon used to tackle complex problems by breaking them down into simpler ones. It allows functions to call themselves, breaking down complex tasks into more straightforward, manageable sub-problems.
Recursion is particularly useful when working with data structures like trees, graphs, and linked lists, where recursive algorithms can traverse and manipulate the elements effectively. It is also essential for searching, sorting, and producing permutations or combinations. Recursion makes code easier to comprehend and maintain, allowing for modular and reusable programming.
Properties of Recursion
All recursive algorithms follow these steps:
Step 1- The algorithms must have a base case. Step 2- Recursion must have a base case to determine when a recursive call should stop. It serves as the recursion's ending condition and ensures the function does not call itself indefinitely.
Step 3- The algorithms should call themselves recursively. Recursion involves a recursive phase that splits the original problem into smaller sub-problems of the same kind.
Step 4- The algorithm must change its state and move toward the base case. By changing the state with each recursive call, the method maintains progress towards the termination condition, breaking down the problem into smaller, more manageable sub-problems until no further recursion is required.
A recursive algorithm is a problem-solving approach that involves breaking down a problem into smaller and smaller subproblems until the subproblems become simple enough to be solved directly. The solution to the original problem is then obtained by combining the solutions to the smaller subproblems.
A key feature of a recursive algorithm is that it calls itself with a smaller version of the problem as its input. The algorithm uses a base case to terminate the recursion when the problem is small enough that it can be solved directly without further recursion.
Steps for implementing recursion in a function are as follows:
Step 1- Start with defining a recursive function along with all necessary parameters.
Step 2- Determine a base condition. In that base condition, either it will return a specific value or end the recursive function.
Step 3- If the base case condition is not met, it will break down the large complex problem into subproblems to reduce its size.
Step 4- The same function recursively calls itself. If there are multiple recursive calls made, then they are combined to solve the original problem.
Step 5- Defining the termination condition is essential so that it does not create an infinite recursion.
How are recursive functions stored in memory?
A data structure known as the call stack stores recursive functions in memory. The call stack is a stack-like part of memory that tracks function calls and their associated data. When you call a recursive function, the program creates a new stack frame and pushes it onto the call stack.
The stack frame contains local variables, parameters, and the return address. Once a base case is reached, the frame of the recursive call pops out from the stack. As the recursion unwinds, the function retrieves the results from each recursive call and merges them to obtain the final result.
It is vital to remember that a stack overflow error can occur if the recursion depth becomes too wide or if the memory allotted for the call stack exceeds. This situation occurs when the number of nested function calls exceeds a specific limit and insufficient memory is available to store the associated stack frames.
What is the base condition in recursion?
The base condition, also referred to as the base case, is the state that determines when the recursion should terminate, and the function should return a result directly without further recursive calls.
In a recursive function, the base condition acts as a stopping bar to prevent indefinite recursion and confirm that the recursion ends. When you reach a base condition, the recursive function gets terminated, and we ensure that it returns a specific value or performs a particular action.
When the base condition estimates to true, the function performs the logic associated with the base case and returns a result. This result is then used in subsequent recursive calls, helping to solve the overall problem step by step.
How can a particular problem be solved using recursion?
Recursion is a problem-solving method in which we create a function that breaks down a complex problem into a smaller-sub problems.
Step 1: A recursive function calls itself until the problem size is small. Identifying the base condition to solve the problem without further recursion is essential.
Step 2: We have to express our problem into subproblems to reduce the problem's size. We must call the recursive function on those subproblems until the base condition is achieved.
Step 3: Then, combine all the results from the recursive function to solve the more significant problem. It is necessary to mention the base condition so that it does not content itself in loops indistinctly.
For example, consider the factorial function. The factorial of a non-negative integer n (denoted as n!) is the product of all positive integers from 1 to n. This function is solved as follows:
factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
In this example, the base condition is when the n equals 0 and will return 1. The function will call itself with an n-1 argument and continue until the base condition is reached. The sub-problems will be multiplied by n with the factorial of n-1, giving a factorial of n as a result.
Why does Stack Overflow error occur in recursion?
A stack Overflow situation occurs when the recursion is too deep and exceeds the available stack space. Whenever someone calls a recursive function, it creates a new stack frame, which may exhaust the stack's capacity and cause an error. This situation may occur when a base case is not reached, or recursion is not controlled.
Each recursive call consumes memory, including space for local variables and return addresses. If this usage exceeds the stack's capacity, a stack overflow error is triggered, resulting in program termination. Proper termination conditions and efficient use of recursion can help prevent stack overflow errors.
Let us learn how to effectively use recursion using various programming languages to build several simple programs or find solutions to different problems. Being one of the most compact and optimised methods of making functions call or deploy functions when programming, recursion can be applied to efficiently use many algorithms and functions.
Using Recursion in C++
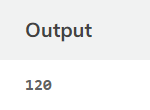
Recursion is very commonly used in programming languages such as C++. Let us check how to use the recursive function in C++ to implement recursion when building a program to find the factorial of 6.
C++
C++
#include<bits/stdc++.h> using namespace std;
// Factorial function int f(int n) { // Stop condition if (n == 0 || n == 1) return 1;
Let us use recursion in JavaScript to find the factorial of 5.
JavaScript
JavaScript
function factorial(x) {
// if number is 0 if (x === 0) { return 1; }
// if number is positive else { return x * factorial(x - 1); } }
const num = 5;
// calling factorial() if num is non-negative if (num > 0) { let result = factorial(num); console.log(`The required factorial gathered from ${num} = ${result}`); }
You can also try this code with Online Javascript Compiler
Recursion in data structure and programming is extensively supported by Scala for building effective data-related and solution-centric programs. Let us use recursion to find the factorial of 4 using Scala.
Let us see recursion in data structure in action now with an example.
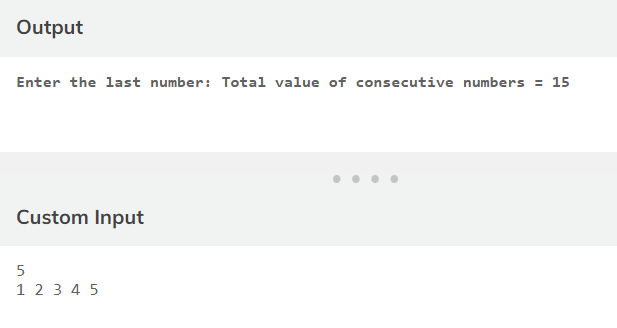
Swapping Nodes of a Linked List in Pairs
In this scenarios, we have to swap the nodes in pairs. It means that we have to swap every two adjacent nodes in the original linked list without changing their values.
If the input list is as below:
1→3→2→4→NULL
The output should be as follows:
3→1→4→2→NULL
Let us see its recursion code snippet as below in C++:
We can see that we reverse the linked list for every two nodes using three temporary nodes as curr, prev and, forward. Then, if we are satisfied that there are more elements in the list, we recursively call for the function again else we return our ans.
Difference between Recursion and Iteration
Basis
Recursion
Iteration
Basis of repetition
Recursion is based on the idea of a function calling itself. The base case is the simplest version of the problem that can be solved without recursion.
Iteration, on the other hand, uses looping constructs such as "for" and "while" to repeat a process a certain number of times or until a specific condition is met.
Control flow
Recursion relies on the call stack to keep track of function calls and their parameters. Each recursive call pushes a new function call onto the call stack, and each return pops the function call off the stack.
Iteration, on the other hand, does not rely on the call stack and uses variables and control structures to control the flow of execution.
Readability and Simplicity
Recursion can often make code more readable and simpler to understand, as the function is broken down into smaller, self-contained pieces that each solve a specific subproblem.
Iteration can sometimes be more complex and harder to read than recursion, especially for complex algorithms or data structures.
Performance
Recursion can be more elegant and easier to understand for certain types of problems
In general, iteration is often more efficient than recursion, especially for large datasets or complex algorithms.
There are many advantages to using recursion in data structures, including:
Recursive solutions often deliver a more intuitive and straightforward representation of the complex problem.
Recursion can more naturally handle dynamic data structures like trees or graphs than iterative approaches.
Recursion can sometimes lead to more efficient solutions than iterative approaches, especially with dynamic programming or divide-and-conquer strategies.
Recursion provides a more clear vision of the algorithm with recursive patterns
Disadvantages of Recursive Programming
There are some potential drawbacks to using recursion in data structures, including:
Memory usage: Recursive algorithms can use a lot of memory, particularly if the recursion goes too deep or if the data structure is large. Each recursive call creates a new stack frame on the call stack, which can quickly add up to a significant amount of memory usage.
Stack overflow: If the recursion goes too deep, it can cause a stack overflow error, which can crash the program.
Performance: Recursive algorithms can be less efficient than iterative algorithms in some cases, particularly if the data structure is large or if the recursion goes too deep.
Debugging: Recursive algorithms can be more difficult to debug than iterative algorithms, particularly if the recursion goes too deep or if the program is using multiple recursive calls.
Code complexity: Recursive algorithms can be more complex than iterative algorithms. Also read - Data Structure MCQ
Frequently Asked Questions
What problems does recursion solve?
There are many use cases of recursion, such as tree and graph traversals, backtracking problems like N-Queen or maze problems, divide and conquer problems like merge sort, dynamic programming problems like knapsack problems, or used in identifying patterns.
Does recursion affect time complexity?
Yes, recursion affects the time complexity. It depends on how the recursion has been implemented and the number of recursive calls made. This whole affects the time complexity of the program. In some cases, recursion may have a high time complexity to the iterative approach.
What is the difference between direct and indirect recursion?
Functions in direct recursion call themselves. This procedure comprises a single-step recursive call from within the function. But, indirect recursion occurs when a function calls other functions, which eventually leads back to the original function. It's similar to a series of functions calling each other.
What is the difference between tailored and non-tailed recursion?
Tail recursion is a form in which the recursive call is the last operation performed in a function. After this call, there won't be any remaining operations. Non-tail recursion is a form where the recursive call is not the last operation performed in a function. Here, after the recursive call, there are some operations.
Conclusion
In this article, we explore the occurrence of recursion within data structures and the storage of recursive functions in memory. The significance of base conditions and the potential ramifications of a stack overflow condition is discussed. Additionally, we examine the distinctions between direct and indirect recursion and the differences between tailored and non-tailored recursion. The article delves into implementing recursion in different programming languages and offers a comparison with iteration. Furthermore, the advantages and disadvantages of recursive programming compared to iterative programming are thoroughly presented throughout the article.


































 9+ registered
9+ registered 
