Do you think IIT Guwahati certified course can help you in your career?
Introduction
You must have heard the story of “Goldilocks And The Three Bears” in which Goldilocks eats the porridge that is not too cold and not too hot. She sleeps in a bed that is not too soft and not too hard. Just like she tries to find the middle ground in everything, we try to make our machine learning models neither underfitting nor overfitting.
While training our machine learning models, the most common problems we face are overfitting and underfitting. They are the leading cause behind the poor performance of machine learning algorithms. We need to learn how to reduce it to make our models generalize the data and predict values accurately, even for new data. In this article, we will learn about underfitting and overfitting and how to overcome them.
What should we know before understanding underfitting and overfitting?
Before we understand what underfitting and overfitting are, we must familiarise ourselves with some concepts.
Signal
We can represent data in the form of graphs and plots. The pattern and shape that the data displays is called the signal. For instance, if data points spread across a graph look like an arch, the signal may be some polynomial equation. Therefore, the polynomial equation will be the basis of the machine learning model to learn the data.
Bias
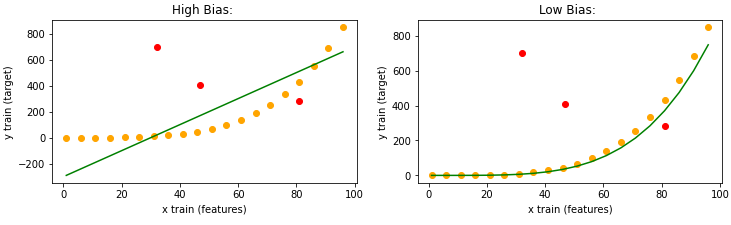
When the machine learning algorithm does not fit the training data well, the difference between the actual and predicted values of the training data is large; it is called high bias.
When the machine learning model fits the training data completely, it is called low bias. In this case, the difference between actual and predicted values is tiny.
#imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#TRAINING DATA
x_train=np.arange(1,100,5) #training data features
y_train=(x_train**4)/100000 #training data target
x_outliers=np.array([32,47,81]) # wrong outliers/noise
y_outliers=np.array([700,407,281])
#TARGET FUNCTION IN CASE OF HIGH BIAS
y_linear=10*x_train-300
#TARGET FUNCTION IN CASE OF LOW BIAS
y_order4=(x_train-3)**4/100000
#VISUALIZATION
fig, (ax1, ax2) = plt.subplots(1, 2,figsize=(12,3))
ax1.scatter(x_outliers,y_outliers,color="red")
ax1.scatter(x_train,y_train,color="orange")
ax1.plot(x_train,y_linear,color="green")
ax2.scatter(x_outliers,y_outliers,color="red")
ax2.scatter(x_train,y_train,color="orange")
ax2.plot(x_train,y_order4,color="green")
plt.show()
Figure A
Variance
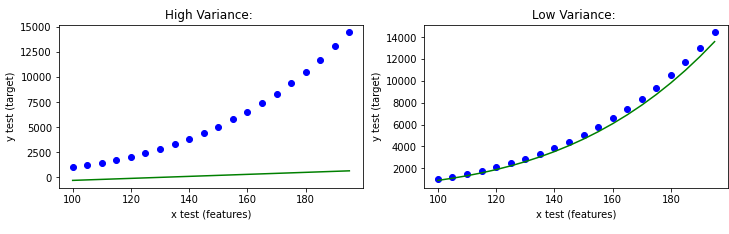
When the model sits nicely on the testing data, it is called low variance. The error in predicted values for testing data is very less. On the other hand, if the model cannot explain the testing dataset, it is called high variance.
#TESTING DATA
x_test=np.arange(100,200,5) #testing data features
y_test=(x_test**4)/100000 #testing data target
#TARGET FUNCTION IN CASE OF LOW VARIANCE
y_order4=(x_test-3)**4/100000
#VISUALIZATION
fig, (ax1, ax2) = plt.subplots(1, 2,figsize=(12,3))
ax1.set(xlabel="x test (features)",ylabel="y test (target)")
ax1.scatter(x_test,y_test,color="blue")
ax1.plot(x_test,y_linear,color="green")
ax2.set(xlabel="x test (features)",ylabel="y test (target)")
ax2.scatter(x_test,y_test,color="blue")
ax2.plot(x_test,y_order4,color="green")
plt.show()
Figure B
Noise
These are the outliers that do not contribute to making our machine learning model learn better. These may be factually incorrect data. For instance, the age column has age 0 or 1000 years in a dataset. This is wrong data or a wrong outlier. Noise in the training data will lead to significant errors in making predictions for testing data. In “figure A” above, the noise is marked with red dots.
Increase Model Complexity: Use a more complex model, such as adding layers in a neural network or increasing the depth of decision trees.
Feature Engineering: Create better features or use relevant ones to help the model learn patterns effectively.
Increase Training Time: Train the model for more epochs or iterations to capture more patterns from the data.
Reduce Regularization: Lower regularization parameters (e.g., L1/L2 penalties) to allow the model to fit the data better.
Add More Features: Include additional informative features that can improve the model's understanding of the problem.
Techniques to Reduce Overfitting
Cross-Validation: Use techniques like k-fold cross-validation to evaluate model performance and prevent overfitting.
Simplify the Model: Use fewer layers, nodes, or simpler algorithms to avoid excessive fitting to the training data.
Regularization: Apply L1 or L2 regularization to constrain model complexity and penalize large coefficients.
Increase Training Data: Gather more data to provide the model with diverse examples, reducing reliance on specific patterns.
Dropout (for Neural Networks): Randomly drop neurons during training to prevent over-reliance on specific pathways.
Early Stopping: Halt training when the model's performance on validation data stops improving.
Prune Decision Trees: Remove branches of a decision tree that contribute minimally to the model's predictive power.
Use Data Augmentation: Introduce variations in the training data, such as image rotations or flips, to increase diversity.
Defining Underfitting
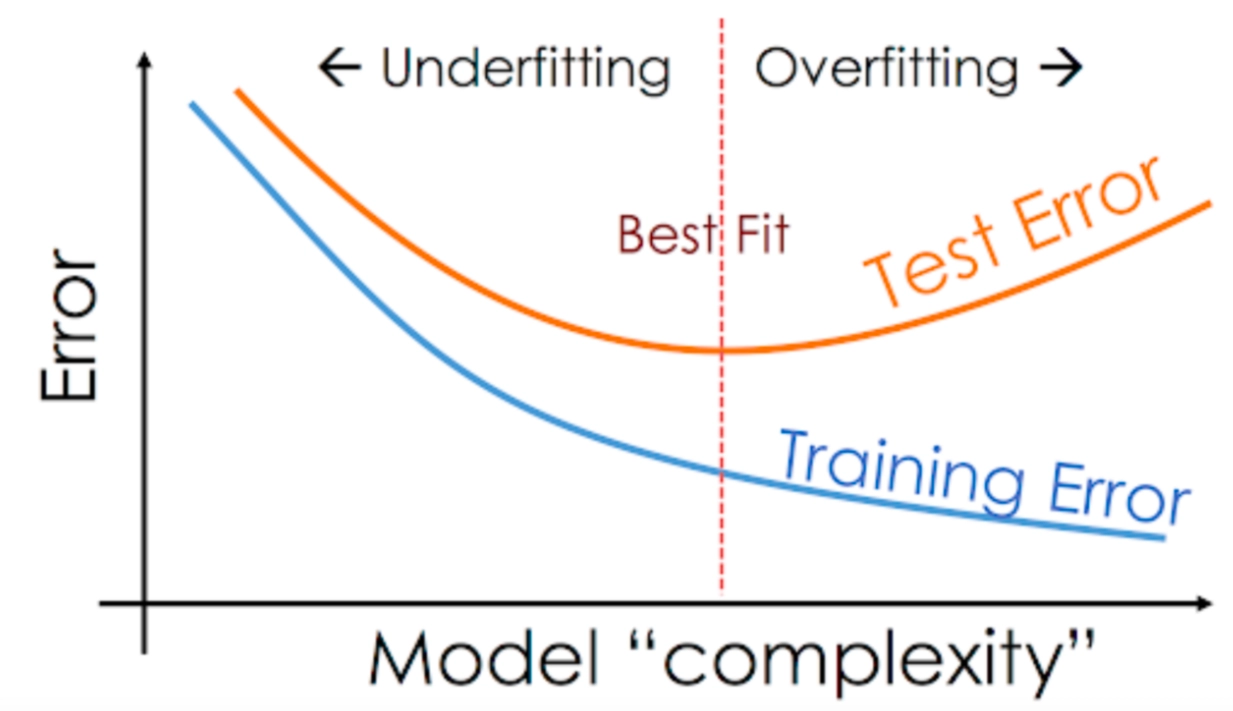
The scenario is known as underfitting when a machine learning model is so simple that it cannot explain both training and testing data. In the case of underfitting, the sum of squares for training and testing data is very high.
Defining Overfitting
Overfitting happens when the machine learning model is so complex that it fits perfectly onto the training data. In this case, the sum of squares for the training data is significantly less. However, when new data or testing data goes through the same model, the predictions are nowhere close to the actual values, making the sum of squares for testing data very high.
Neither underfitting nor overfitting is desirable. A good fit occurs when a model balances complexity and generalization, capturing the underlying patterns in the data without being too simplistic (underfitting) or overly specific to the training set (overfitting).
Underfitting happens when the model is too simple, failing to capture the patterns in the data. This leads to poor performance on both the training and test datasets.
Overfitting occurs when the model is too complex, capturing noise or random fluctuations in the training data, which hurts its ability to generalize to unseen data.
A good fit is achieved when the model performs well on both training and validation/testing datasets, indicating that it generalizes well to new data while effectively learning from the training set.
Underfitting and overfitting in linear algorithms
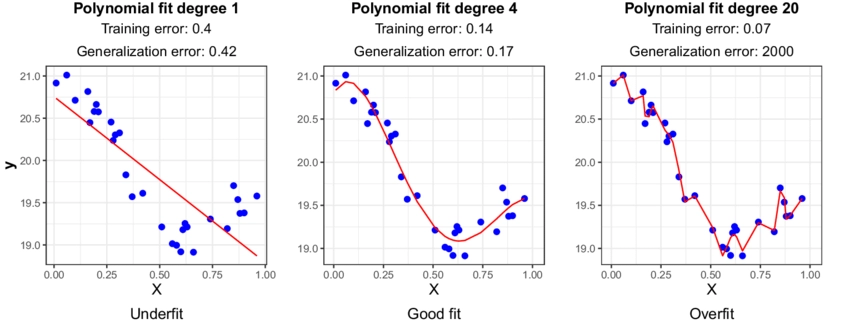
We are going to look at underfitting and overfitting in polynomial regression.
1. The first graph shows that the degree of the polynomial equation is 1. The model will act as a simple linear regression model and find the best fit line for the training data. However, we know that linear regression only works on linear spread points instead of non-linearly spread points. As a result, we get high bias and high variance because neither this model can explain the training data nor the testing/ new data.
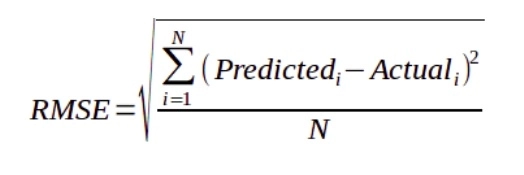
Root mean squared error (RMSE) will be very high because there is a vast difference between the actual and predicted values.
2. The second graph shows that the polynomial line of degree 4 fits the training data perfectly. It has low bias and low variance. It satisfies most of the training points. Even for the points a bit away from the line, the error is significantly less. This model will also work well on the testing data because it generalized all the points adequately. The RMSE here will be low.
3. The polynomial line of degree 20 fits almost all the training points perfectly that it will not work on the testing data at all (Talk about being imperfectly perfect)! This model has low bias and very high variance. This model gives an extremely low error with the training data and provides a high error with testing data. The RMSE here will be high for testing data.
Underfitting and overfitting in nonlinear or classification algorithms
If we consider categorizing or classifying data using decision trees, the following may happen:
Decision trees take all the features and start splitting them to their complete depth. This scenario leads to overfitting the training data. In this case, the error rate for training data will be less. However, for the testing data, it won’t be accurate.
In Decision Trees, there is low bias and high variance because we choose the best feature at each step of making the branches to maximum depth according to the training dataset. Doing this won’t give good results when it comes to testing data.
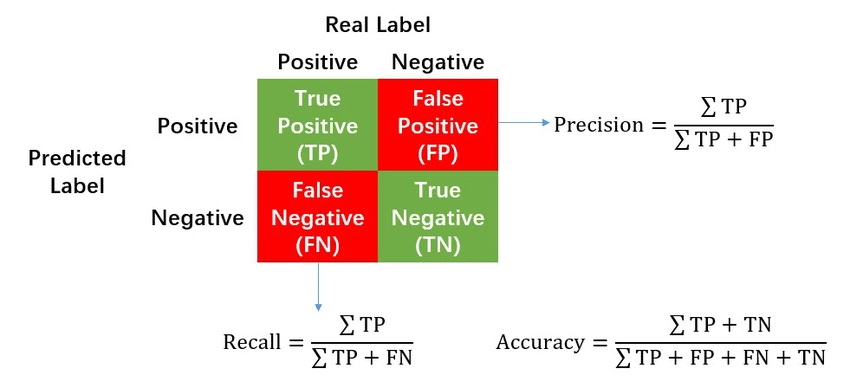
The accuracy of a classification algorithm is one way to measure how often the algorithm classifies a data point correctly.
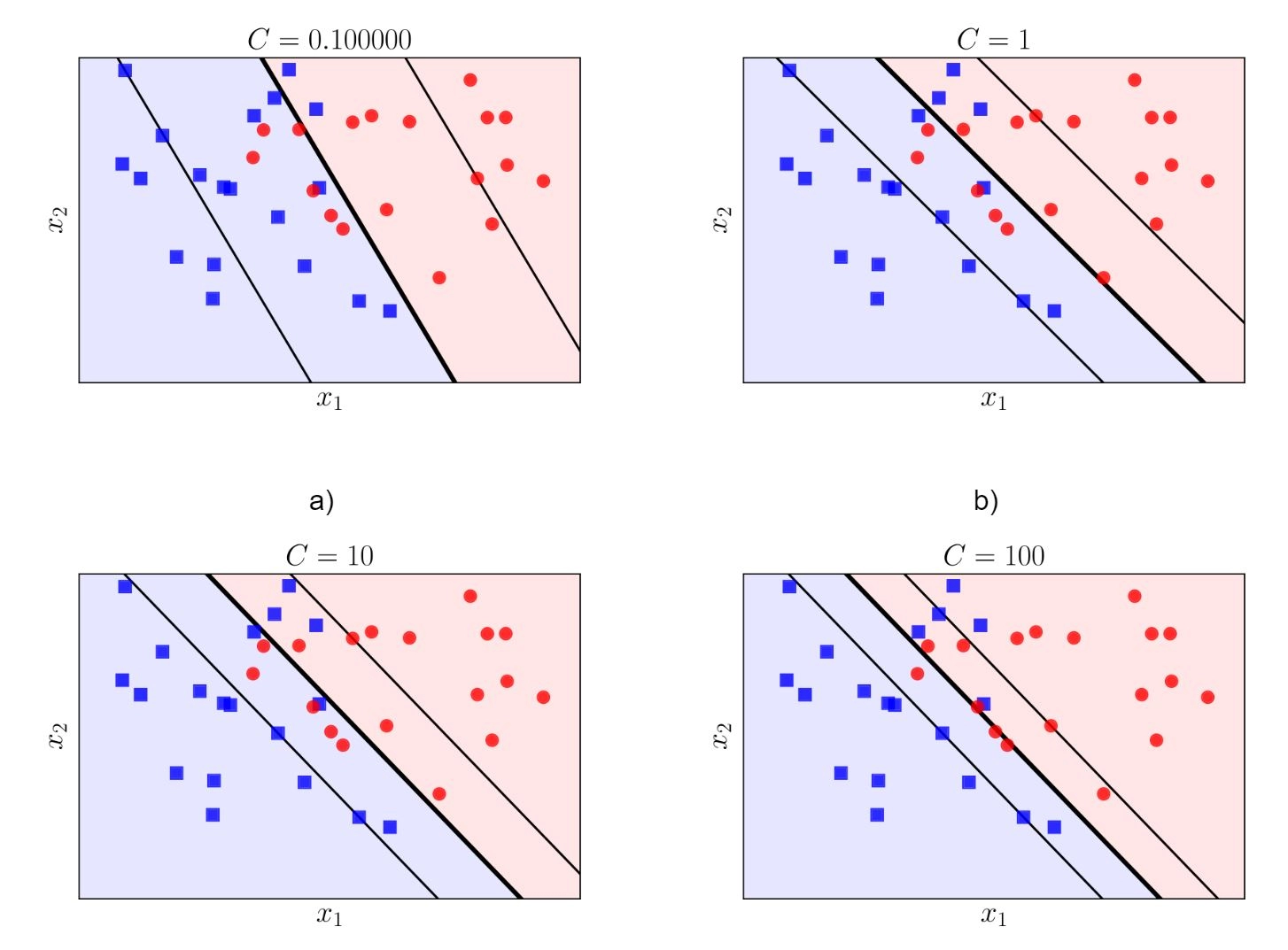
In the image above, we assume it is of the KNN classifier. We find out that:
In the first image, the decision boundary is too simple to explain the variance and thus has low accuracy.
The second image shows a decision boundary that helps make more accurate predictions for both training and testing data.
The third image demonstrates how the decision boundary overfits the training data resulting in low accuracy for testing data.
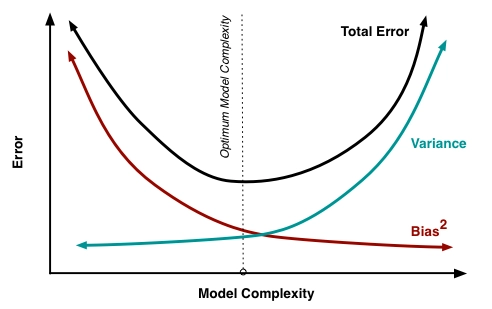
Bias-Variance Trade-Off to overcome underfitting and overfitting
Low bias and low variance are the goals of any supervised machine learning algorithm. As a result, the algorithm should be able to make accurate predictions. We need to find a machine learning model that is simple enough to have low bias and complex enough to have low variance.
Here are two examples of bias-variance trade-off configuration for specific algorithms:
The k-nearest neighbors technique has a low bias but a high variance. The trade-off may be altered by raising the value of k, which increases the number of neighbors who contribute to the prediction and raises the model's bias.
The support vector machine technique has a low bias and a significant variance. Still, the trade-off can be modified by changing the kernels, C, or gamma hyperparameters, which affects the number of misclassified data permitted in the training data, increasing the bias while decreasing the variance.
Model performance might be hindered by both overfitting and underfitting.
Underfitting can be remedied by moving on and experimenting with different machine learning techniques. Nonetheless, it serves as an excellent counterpoint to the issue of overfitting.
There are several strategies to avoid overfitting, and a few of them are included here:
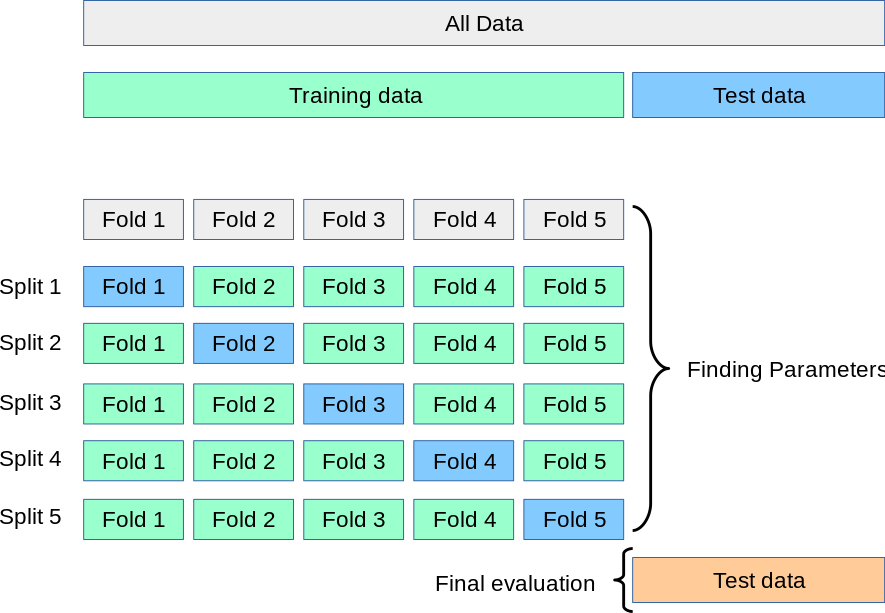
Cross-validation
Create several tiny train-test splits with your training data. The divisions can be used to fine-tune your model. We partition the data into k subsets/folds. The method is then iteratively trained on k-1 folds.
It won't always work, but more data can help algorithms detect the signal more accurately. If more training data is fed into the model, it will not overfit all of the samples and be forced to generalize to produce results. However, this method may be very cumbersome.
Data augmentation
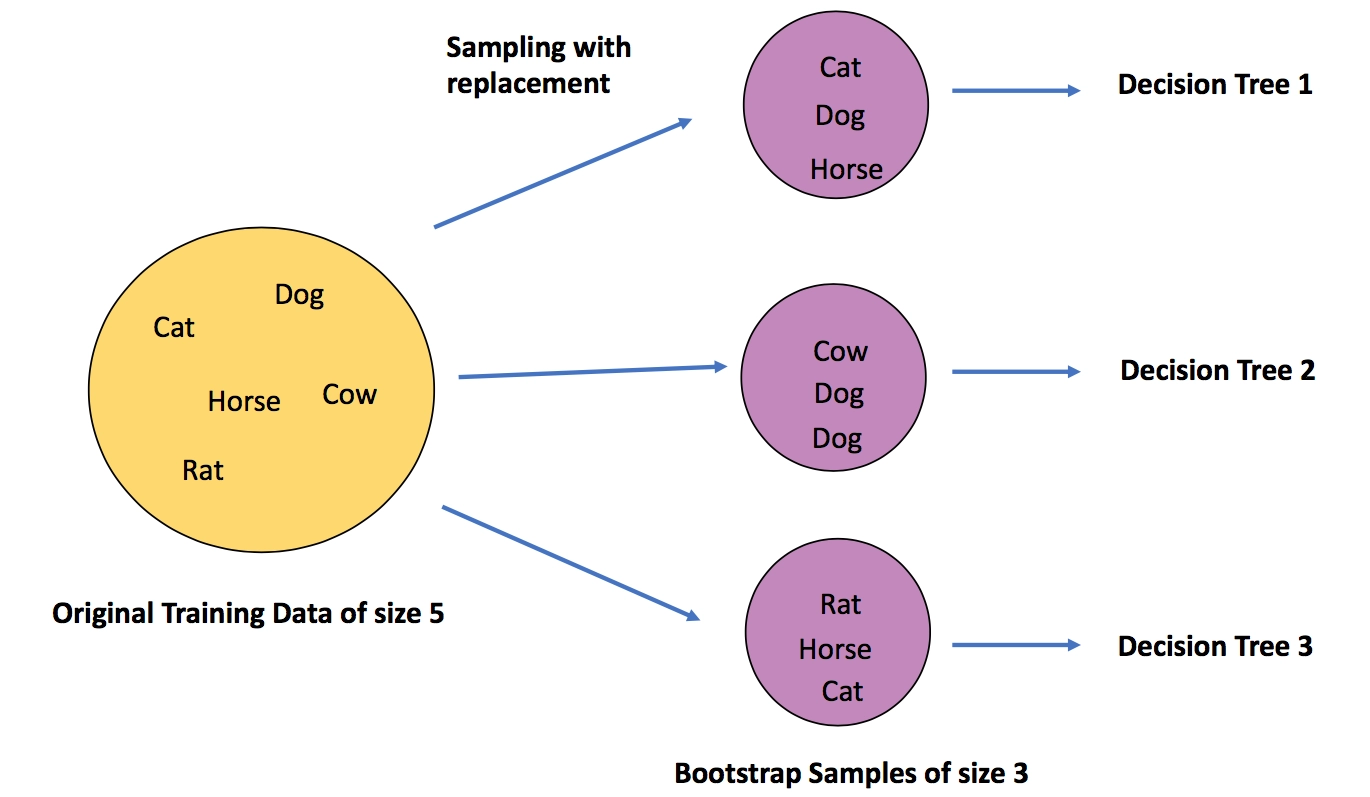
You can make the given data sets appear diverse if you cannot collect more data regularly. You can do this by splitting the dataset, shuffling the order of data, repeating a few rows, using only a few features or a few rows at a time as training data. For instance, in random forests, we use the feature and row sampling to make different decisions trees.
Overfitting can happen due to a model's complexity, such that even with vast amounts of data, the model manages to overfit the training data. The data simplification method reduces overfitting by reducing the model's complexity to the point where it does not overfit.
Pruning a decision tree, lowering the number of parameters in a Neural Network, and utilizing dropout on a Neural Network are some operations we can do.
Regularisation
Regularization helps to simplify the machine learning model to avoid overfitting. It is a hyperparameter and may be fine-tuned using cross-validation. In Support Vector Machine, regularization is the amount of data misclassification allowed. This is controlled by changing the width of the soft margin.
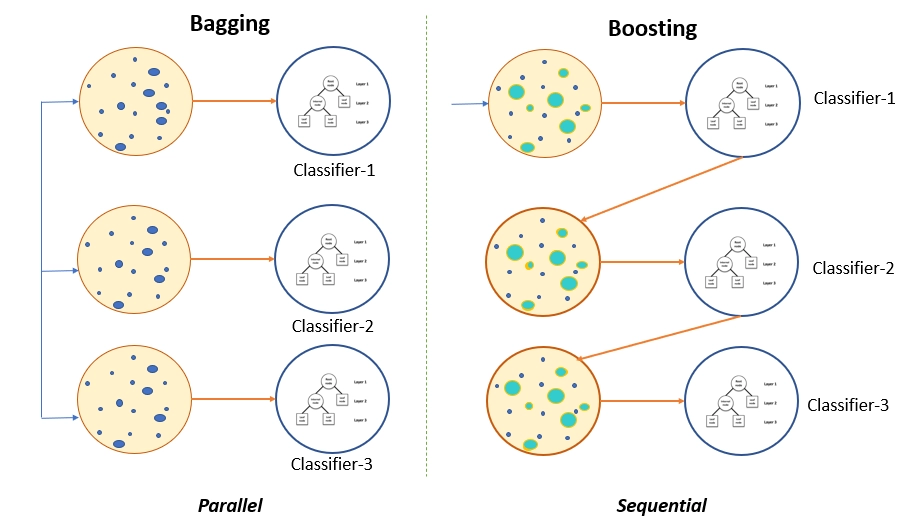
Ensembling
Ensembling is a method that merges predictions from numerous different models into a single output. Ensembling can be done in various ways, but the most prevalent ones are bootstrapping, bagging, and boosting. Bootstrapping is creating different subsets from the training data. These subsets are then fed to the same or different classifiers. Aggregating the results from all these classifiers and finding its mean to come up with the final output is called Bagging. Boosting is using the output of one classifier as input of another.
Random Forests use bagging to deal with overfitting in decision trees.
Early Stopping
New iterations refine the model until a specified number of iterations are completed. However, if the model begins to overfit the training data, the model's ability to generalize can deteriorate. Putting a stop to the training process before the learner reaches that point is early stopping.
Frequently Asked Questions
What is overfitting and underfitting in machine learning?
Overfitting occurs when a model learns noise in training data; underfitting happens when a model fails to capture data patterns effectively.
What is the difference between overfitting and underfitting accuracy?
Overfitting shows high training accuracy but poor testing accuracy; underfitting results in low accuracy on both training and testing datasets due to inadequate learning.
How do I know if my model is overfitting or underfitting?
Compare training and testing accuracy: a large gap indicates overfitting, while low accuracy for both datasets indicates underfitting.
Conclusion
This article taught us how bias and variance make a model underfitting or overfitting. We learned in detail what is underfitting, good fit, and overfitting in linear and non-linear classification algorithms. We talked about bias-variance trade-offs to reduce underfit or overfit. We saw how to overcome underfitting and overfitting in detail. Do you want to know more? Check out our industry-oriented machine learning course curated by our faculty from Stanford University and Industry experts.































 8+ registered
8+ registered 

