Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In this modernistic world, information is a crucial element that eases the lives of the masses, and storing this information is one of the biggest challenges we face. As a developer, we don’t deal with single data but clusters of a wide variety of data. We will understand the MapReduce framework, which processes large amounts of unstructured data across a distributed group of processors into a structured unit.
We will start our discussion from when we used to do things manually; here, we will discuss the manual approach and the shortcoming we faced while using the manual method.
Afterwards, we will discuss our approach to doing such a task after developing an algorithm.
Traditional Approach
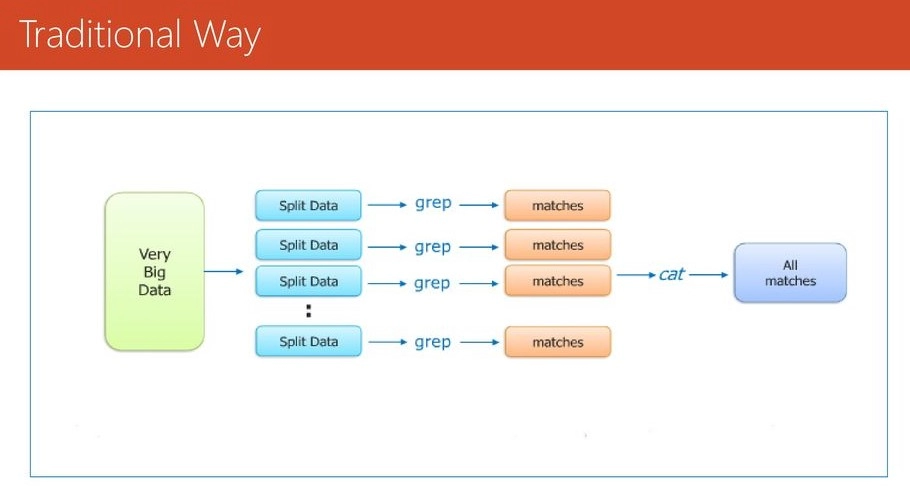
Let's look at how parallel and distributed processing used to work before the MapReduce framework. So, let’s say I have a weather log containing the daily average temperature for 2012 to 2022. I'm trying to figure out which day of the year has the highest temperature.
As a result, we'll divide the data into smaller portions or blocks and store them in multiple machines, much as in the old days. Then, we’ll find the highest temperature for each part stored in the associated device. Finally, I will aggregate the results from each machine to produce the final product. Let's have a look at the drawbacks of the standard approach:
The length of time it takes to complete the project without postponing the following milestone or the actual completion date is known as the critical path problem. As a result, if one of the machines causes a delay, the entire process will be delayed.
The problem of reliability: What if one of the machines handling a portion of the data fails? It becomes challenging to manage this failover.
How will I divide the data into smaller chunks so that each computer has an equal amount of data to work with? In other words, how to distribute the data evenly so that no single system is overburdened or underutilized.
A single split could go wrong: I won't be able to calculate the outcome if any of the machines fails to produce output. As a result, there should be a method to assure the system's fault tolerance capability.
Compilation of the data: To have a final output, a method should be in place to aggregate the units’ results.
These are the challenges that we'll have to deal with on our own while undertaking parallel processing on large datasets using standard methods.
We have the MapReduce framework to address these concerns, which enables us to do parallel computations without worrying about issues like reliability and fault tolerance. As a result, MapReduce allows us to build code logic without worrying about the system's architecture difficulties.
Now to build the MapReduce framework, we will understand what “map” and “reduce” functions are and how their coexistence gives the MapReduce framework.
Map Function
For years, the map function has been a feature of many functional programming languages, with LISP, an artificial intelligence language, being the first to popularise it. The “map” has been revived as a primary technology for processing lists of data pieces by good software developers who recognize the importance of reuse (keys and values).
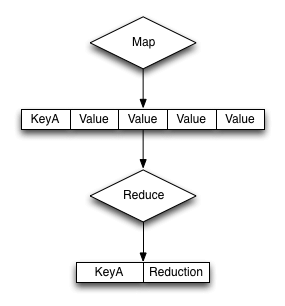
In the Map function, unction, the user defines a function to apply to each key-value pair, resulting in other key-value pairs known as intermediate key-value pairs.
Like the map function, Reduce has long been a part of functional programming languages. It's called fold in different languages, but the behavior is the same. The reduce function takes the result of a map function and "reduces" it in any way the programmer wants. The reduce function requires the first step of entering a value into an accumulator, which stores an initial value. The reduction function processes each element of the list and performs the operation you need across the list after saving a beginning value in the accumulator. The reduction function returns a value at the end of the list based on the operation you wish to execute on the output list.
The intermediate key-value pairs are grouped by key in this phase, and the user applies a “reduce” function to each group, resulting in other key-value pairs, which comprise the round's output.
MapReduce is a programming framework that allows us to do distributed and parallel processing on massive data sets in a distributed environment.
MapReduce is made up of two tasks: Map and Reduce.
As the name implies, the reducer phase occurs after the completion of the mapper phase.
The first is a “map” job, which reads and processes data blocks to produce key-value pairs as intermediate outputs.
The reducer receives the output of a Mapper or a “map” job (key-value pairs).
The reducer receives the key-value pair from numerous map tasks.
The reducer then condenses those intermediate data tuples (intermediate key-value pair) into a smaller collection of tuples or key-value pairs, which serves as the final output.
Now we will understand the algorithm's core, and the implementation of a particular round.
When we divide the file into chunks, each becomes a map task's input. Each map task is allocated to a worker node, which uses the map function to apply to each key-value pair in the relevant input chunk.
The intermediate key-value pairs are saved on the workers' local drives. Each intermediate key-value pair is placed in the local disc into buckets through a hash function h to speed up the procedure and balance the load of workers. (key,value)->Bucket I = h(k) mod (N° Buckets) Each bucket is assigned to a distinct worker who uses the user-specified reduce function.
During these three phases, two key functions are performed.
The shuffle function is used to transmit information from mappers to reducers. This function can start even before the map phase has ended to speed up the algorithm. Shuffle is frequently the most expensive round procedure.
The sorting function is used to sort a list of values with the same key. If you don't supply any reducers, the result will be zero. The MapReduce job then comes to a halt at the map phase.
Let’s understand MapReduce with a word count example
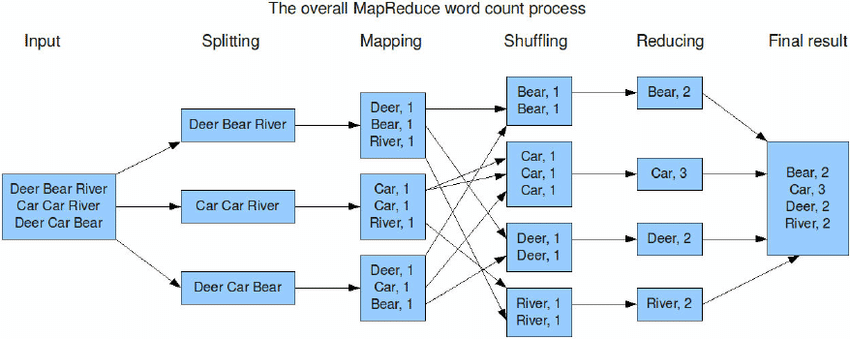
Let's look at how a MapReduce works using an example: I have a text file called example.txt with the following contents:
Dear, Bear, River, Car, Car, River, Deer, Car, and Bear
Assume we need to use MapReduce to do a word count on example.txt. As a result, we'll be looking for unique terms and the number of times they appear.
First, we partition the input into three sections, as shown in the diagram. This will evenly spread the workload across all map nodes.
Then we tokenize the words in each mapper and assign a hardcoded value (1) to each token or word. Setting the hardcoded value to 1 is that each word will only appear once.
A list of key-value pairs will now be produced, with the key being the individual words and the value being one. So we have three key-value combinations for the first line (Dear Bear River) — Dear, 1; Bear, 1; River, 1. On all nodes, the mapping procedure is the same.
Following the mapper phase, a partition process occurs, sorting and shuffling tuples with the same key and sending them to the matching reducer.
As a result, each reducer will have a unique key and a list of values corresponding to that key after the sorting and shuffling step. For instance, Bear [1,1], Car [1,1,1], and so on.
Each reducer now counts the number of values in that list of values. Reducer receives a list of values for the key Bear, as illustrated in the diagram. After that, it counts the number of ones throughout the entire list and outputs Bear, 2.
After that, the output key/value pairs are collected and written to the output file.
FAQs
What is the Map function?
In the map function, the user defines a function to apply to each key-value pair, resulting in other key-value pairs known as intermediate key-value pairs.
What is Reduce function?
The intermediate key-value pairs that we find in the map function are grouped by key in this phase, and the user applies a “reduce” function to each group, resulting in other key-value pairs, which comprise the round's output.
What are the steps involved in MapReduce dataflow?
The steps involved in MapReduce are input, split, map, combine, shuffle and sort, reduce then output.
Conclusion
In this article, we have extensively discussed what “map” and “reduced” functions are and why we need MapReduce. We hope that this blog has helped you enhance your knowledge and aspects that you should keep in mind while dealing with the MapReduce framework and if you would like to learn more, check out our articles here. You can also check the introduction to Hadoop and its ecosystem here, and the difference between Sparks and Hadoop here. If you want to explore and learn big data, make sure to check out this. Do upvote our blog to help other ninjas grow.
Learning never stops, and to feed your quest to learn and become more skilled, head over to our practice platform Coding Ninjas Studio to practice top problems, you can check SQL problems here, attempt mock tests, read interview experiences, and you can also check our guided path for the coding interview and much more!






























 9+ registered
9+ registered 

