


























Introduction
Source: section.io
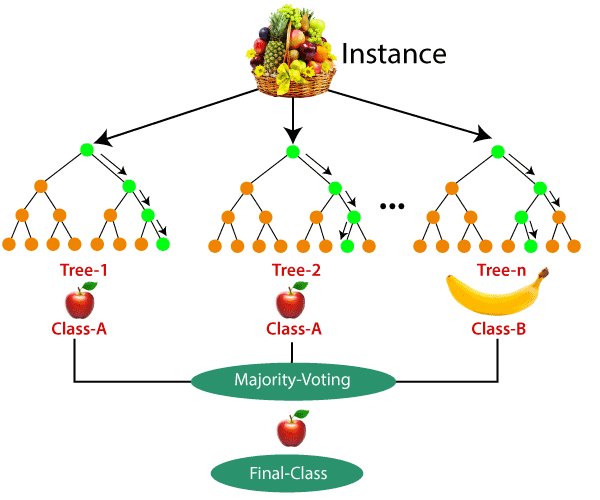
Random Forest is a supervised Machine Learning Algorithm which is the extended version of the Decision Tree. The problem that arises in the Decision Tree is Overfitting. The algorithm tries to accurately fit the sample data according to the sample output and performs well on the sample data. But may perform very poorly in the case of the testing data. Random Forest says that let's not rely on only one Decision Tree. Instead, we will use multiple Decision Trees and select the majority result out of them. We will use the same training examples to build numerous Decision Trees, but they all will be different from each other. So, how is this possible? We will not use the same features to build the Decision Tree but will use some randomness to get to the point where one outlier might affect a few of the Decision Trees, but not all of the Decision Trees. Let's now talk about the formation of the Random Forest.
Bagging
We are given some training data with columns as the features and rows as the data points or observations. We want to build a classifier that will provide us with the prediction. In Random Forest, we use multiple classifiers. The data fed in each of the classifiers should be different from each other. We use a method called Bagging.

Source:medium.datadriveninvestor.com
Bagging is the shortcut of the Bootstrap Aggregation Algorithm. Bagging says that if we have 'm' data points, let's select 'm' out of it, but with replacement, i.e., one data point can come multiple times. In this way, if any data point is present more than once, some of them must be missing.
Along with the Bagging, we make Feature Selection as well. In Feature selection, we are not going to train a Decision Tree based on all the features. If there are 'n' features, let's select 'k's out of it randomly. But with no replacement. The very standard number to choose the feature is n out of n features. In this way, each of the Decision Trees is trained on different features and different training datasets. The good part about the feature selection is that if there is one feature that is creating a problem for us, we will have some trees that will not have that particular feature and hopefully will be able to reduce the overfitting problem.
Decision Trees and Random Forest can be used to solve regression problems (when we have to prodigy the value out of continuous range). For example, if we have to predict the stock price, the age of a person, etc., which is not a classification problem. We don't have a set of classes out of which we have to predict the value. We have a continuous range to predict any value in between.
Let's say we have a diabetes dataset and the prediction we are doing is the HbA1c (a test that measures the amount of blood sugar attached to the hemoglobin). Decision Trees that we have discussed are completely based on the classification. For regression prediction, we have to make some changes; the basic algorithm still stays the same. At any node, we will predict the mean as an output rather than the majority. We will divide a node by selecting a feature so that the mean squared error is minimum.
For more information, you may visit:

 9+ registered
9+ registered 

