Do you think IIT Guwahati certified course can help you in your career?
Introduction
Uniform Resource Locator is used to identify unique documents over on the Web. These are extensively used for people to surf over the Internet as instead of remembering a set of random numbers, URLs make our task more accessible as we surf using texts. In other words, a URL is composed of either word (https://www.codingninjas.com/) or IP addresses(13.35.131.44).
The hypertext of the URL provides the link to different websites through which we can navigate to multiple web pages. In this article, we will discuss the parts of a URL and integrate them into our web pages using HTML.
World Wide Web is a collection of web pages as we know, and the Uniform Resource Locators are used to surf over millions of these web pages using unique names and IP addresses. The Web Servers handle the resources shared by the URL and the URL itself.
Anatomy of a URL
Similar to everything in programming languages, even a URL has some syntax that is to be followed. Let’s dive and know more about it:
Syntax:
scheme://prefix.domain:port/path/filename
The highlighted part represents the syntax of a URL defined using keywords.
We could define these keywords as:
→ scheme: The initial segment of the URL is the scheme, which demonstrates the convention that the program should use to demand the asset (a pattern is a set strategy for trading or moving information around a PC organization). Usually, for sites, the pattern is HTTPS or HTTP (its unsecured form). Tending to site pages requires one of these two. However, programs also realize how to deal with different schemes, such as mailto: (to open a mail customer), so don't be astounded if you see other conventions.
→ prefix: This is used to define a domain prefix. For example, www is a prefix for www.codingninjas.com codingninjas.com
→ domain: The domain specifies the unique name given to a web page, for example, in www.codingninjas.com - codingninjas is the specific unique name that represents the domain of our website. The domain could also be specified using a unique set of numbers: the unique IP address of a website.
→ port: The port is used as a technical gate to access the resources on the web server. This number is used to connect the client-server to the web server so that it can access the resources. By default, the port number of the scheme is set to be 80.
→ path: This is used to define the path or the subdirectory of the resources on the web server. For example, if you try to run an HTML file on your device, you might see the physical path of your folder.
→ filename: This is used to specify the path of either a document, folder, image, or program which is to be displayed on the webpage.
How to use a URL?
A URL can be typed on the address bar to help us locate a particular web page. But that is not all, in HTML we use URLs extensively to map and link different pages together using the hyperlink tags. Few ways we can embed URLs in our web pages are as follows:
We can use the anchor tag <a> to specify the URL using the href attribute, and we can use this to generate links to documents and other web pages.
We can use the <script> and the <link> tag to specify the link between various resources on a document.
We can use the <img>, <audio>, and the <iframe> tags and use the href attribute to use a URL to specify these tags and embed the URLs in our webpage.
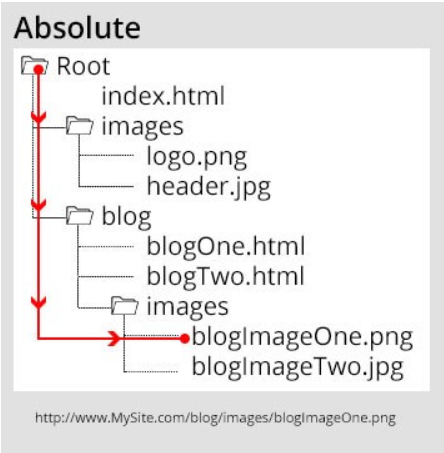
Absolute URLs
The Absolute URL is a complete URL that contains the entire address of the webpage. These URLs are mainly used to link different pages to each other. Absolute URLs are longer and always point to the desired URL without any mistakes. These URLs contain the entire address from the protocol, including the domain name and the resource’s location on the website.
They follow the given syntax:
scheme://server/path/resource
The absolute URLs are embedded in the HTML web pages using the below anchor tag:
The above-given URL is an absolute URL that points to the blog folder, where we need the image folder, and inside the image folder, we need to display the blogImageOne on the screen.
Relative URLs
The relative URL is a short version of the absolute URLs. In these URLs, we assume that the main directory remains the same as a website you want to explore, so just specify the new folder or location as a path.
They follow the given syntax:
/path/resource
These URLs are used for faster and effective coding. When we refer to a file in the same directory as the referring page, the URL can be as simple as the file’s name.
We want to point to the images folder instead of referring to the entire root address in this example.
We could give the relative address of the given folder as :
<a href =”../images/blogImageOne.png”></a>
We can surf the web and include any image we want on our website using the <img> and the href property. You would be wondering how right? Let’s understand it using an example.
The characters in a URL are limited to a defined set of reserved and unreserved ASCII characters, which are given in this RFV3986 document. Any other character which is not present in the given list is not allowed on the URL. URL encoding is a process to convert URL information into information that can be safely transmitted over the internet.
Two steps are used to map the entire process to find the characters eligible to be in the URL, which are:
The characters that do not respond to unreserved characters are customized and are presented using the % encoding method, also known as the data conversion to its hexadecimal value.
Reserved Characters
Certain characters are reserved for use in a URL because they may (or may not) be defined as delimiters by the generic syntax in a particular URL scheme. For example, forward slash/characters are used to separate different parts of a URL. These characters have a special meaning in the server and are used to represent particular properties.
Suppose data for a URL component contains characters that would conflict with a reserved set of characters, defined as a delimiter in the URL scheme. In that case, the conflicting character must be percent-encoded before the URL is formed. Reserved characters in a URL are:
!
#
$
&
'
(
)
*
+
,
/
:
;
=
?
@
[
]
%21
%23
%24
%26
%27
%28
%29
%2A
%2B
%2C
%2F
%3A
%3B
%3D
%3F
%40
%5B
%5D
Unreserved Characters
The characters which are not explicitly reserved for the URL encoding and do not have any reserved purposes are known as Unreserved Characters. These characters consist of the Uppercase, lowercase, hyphen, period, underscore, tilde, and decimal digits which we use in the general surfing of the URLs.
These characters are:
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
0
1
2
3
4
5
6
7
8
9
-
_
.
~
Frequently Asked Question
What is the use of a URL?
Ans: Uniform Resource Locator is used to identify unique documents over on the Web. These are extensively used for people to surf over the internet as instead of remembering a set of random numbers, URLs make our task more accessible as we surf using texts.
How to encode a URL?
Ans: URLs can only be sent over the Internet using the ASCII character set. Since URLs often contain characters outside the ASCII set, the URL has to be converted into a valid ASCII format using the utf-8 encoding. URL encoding replaces unsafe ASCII characters with a "%" followed by two hexadecimal digits.
What are the types of a URL?
Ans: There are two types of URLs which are: → Absolute URLs: The Absolute URL is a complete URL that contains the full address of the webpage. These URLs are mainly used to link different pages to each other. → Relative URLs: The relative URL is a short version of the absolute URLs. In these URLs, we assume that the leading directory remains the same as a website you want to explore, so just specify the new folder or location as a path.
Key Takeaways
This article has covered all the essential information about Uniform Resource Locators (URLs) in HTML. The Uniform Resource Locator(URLs) are used to address knowledge and surf it over the Internet. They are a key used to search content on this vast area of the World Wide Web. We have covered the anatomy of a URL which defines the contents a URL is made up of, scheme, domain name, authority, path, resource, and files. We have also discussed how we can perform URL encoding and the two types of characters involved while performing URL encoding, the reserved and unreserved characters. We have provided a fantastic Web Development course for you, and we feel it could be the perfect aid to make you better than the rest of the developers.
































 9+ registered
9+ registered 

