Do you think IIT Guwahati certified course can help you in your career?
Introduction
Uninformed search, also called blind search, is an algorithm that explores a problem space without prior knowledge, focusing solely on the initial state and possible actions.
One of the important categories of Algorithms is Uninformed Search Algorithms in Artificial Intelligence.
This article will discuss the important Uninformed Search Algorithms like BFS, DFS, DLS, IDDFS, etc. So without further ado, let’s start by first exploring Uninformed Search Algorithms in Artificial Intelligence!
What is an uninformed search algorithm in AI?
Uninformed Search Algorithms or Blind Search Algorithms are the search algorithms that are used to find the solutions to the problem which does not have any domain knowledge associated with it. It is used in Artificial Intelligence to find relevant solutions by exploring all the possibility sets of the problem space.
Typesof Uninformed Search Algorithms
These are the various types of Uninformed Search Algorithms in Artificial Intelligence:
Breadth First Search ( BFS )
Depth First Search ( DFS )
Uniform Cost Search ( UCS )
Depth Limited Search ( DLS )
Iterative Deepening Depth First Search ( IDDFS )
Let’s discuss them one by one in detail.
1. Breadth First Search
Breadth First Search ( BFS ) is used to explore all the neighbouring states or nodes of the initial node, thus guaranteeing the shortest path between nodes in a tree-like data structure. It is used to reach the goal state using the shortest path between the initial and goal state.
The Queue data structure is used in BFS. The initial node is first pushed into the Queue, and then after visiting the front node, all the neighbouring nodes are pushed into the Queue. Thus it ensures that the goal state is reached using the shortest path by exploring all the neighbours at once.
Refer to this article to learn in detail about the BFS.
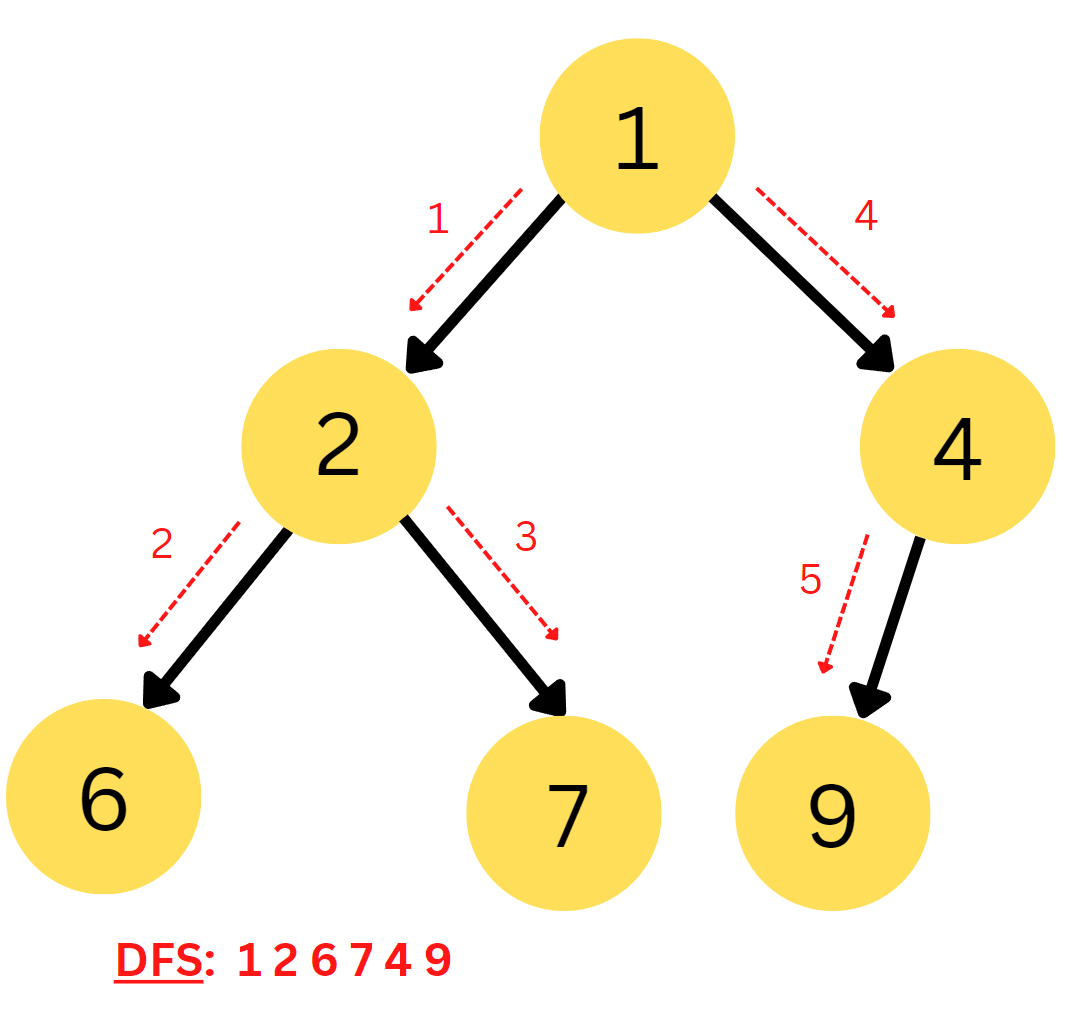
2. Depth First Search
Depth First Search ( DFS ) is used to find the solutions by exploring all the nodes till the end of a branch is reached and then backtracking and exploring other branches in the same way. It is a recursive algorithm. DFS searches along each branch by going into the deep.
The Stack data structure is used in DFS in a similar way queue was used in BFS. First, the initial state is pushed into the stack, and then the top element is popped out, and its neighbours are pushed into the stack. In this way, it makes sure to traverse along each branch separately.
Uniform Cost Search ( UCS ) is used to find the solution to a problem along with minimizing the cost of the path from the initial state to the goal state. UCS works by selecting the path with the minimum cost at each step after exploring all the possible paths.
The cost function f(n) is defined in UCS, which gives the cost of the path from the initial step to each node n. It traverses the path with the lowest value of f(n), thus ensuring the lowest cost path.
Let’s see the algorithm to find UCS using the Priority queue.
Algorithm Uniform Cost Search
Initialize a priority queue to explore the nodes according to their costs.
Set the cost of the initial state as 0 and push it into the priority queue.
Repeat the following steps until the priority queue is not empty:
Remove the topmost node, which is the node with the lowest cost.
If this node is equal to the goal node, end the search.
Else, calculate the path costs of the neighbours of the current node.
Update the cost of the neighbour node if it already exists in the priority queue; else, push this node.
If the search doesn’t end in the above loop, no solution exists.
Example
Let’s see the steps of UCS in the following example.
1. Start from the initial node A and set the cost to reach A as 0. Insert A into the priority queue.
Priority Queue: ( A, 0 )
2. Extract the node with the minimum cost from the priority queue. Node A is selected since it has the lowest cost. Insert its neighbours B and D into the queue.
Current Node: A, Cost: 0
Priority Queue: (B, 2), (D, 4)
3. Extract the node with the minimum cost from the priority queue. The node B is selected. Insert its neighbours C and G into the queue.
Current Node: B, Cost: 2
Priority Queue: (G, 1), (D, 4), (C, 5 )
4. Again, extract the node with the minimum cost from the priority queue. The node G is selected. Stop since G is equal to the goal node.
Current Node: G, Cost: 3
The shortest path from A to G found by UCS is A -> B -> G, with a total cost of 3.
Let’s see the complexities of the above algorithm.
Time Complexity: The worst-case time complexity of UCS is O(b^d), where b is the branching factor of the search tree, and d is the depth of the goal node.
Space Complexity: The space complexity of UCS is also O(b^d) but can be further reduced to O(bd) if we use a binary heap as the priority queue.
4. Depth Limited Search
Depth Limited Search ( DLS ) is a modified DFS algorithm that is designed in such a way as to overcome the problem of infinite loops that may occur in the DFS algorithm due to the presence of cycles.
Instead of performing the DFS up to the entire length of a branch, DLS limits the depth of exploration by performing DFS only till a predefined level.
Let’s see the algorithm to find DLS.
Algorithm of Depth Limited Search
Start with the initial state of the problem.
Explore the current state and generate its successors.
If the depth of the current state is equal to the predefined limit, stop the search.
Else, recursively apply the DLS to explore the branch till the level with limit is reached.
Repeat the above steps until a goal state is reached or all the states till that level is traversed.
Example
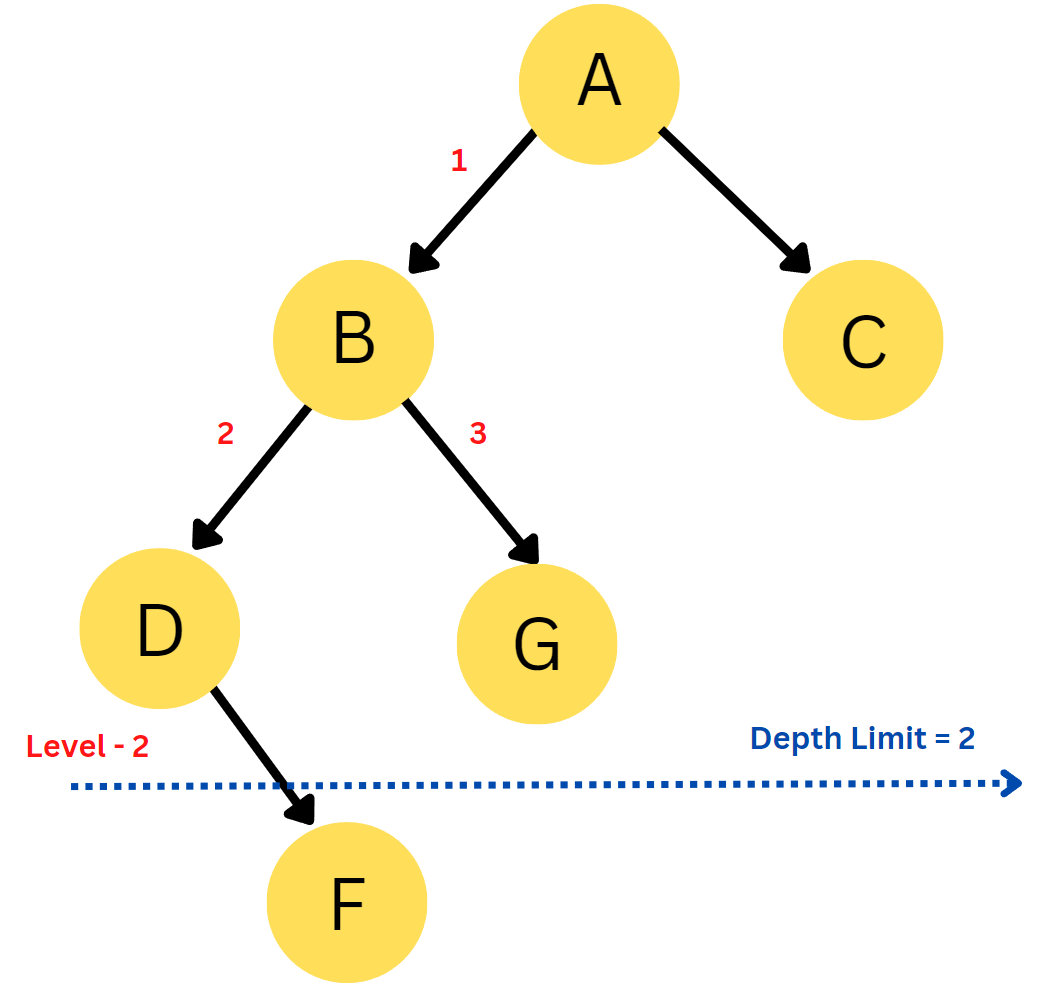
Let’s see the steps of DLS in the following example.
Start from the Initial State, i.e. A and expand its neighbours B and C.
Perform DFS and visit neighbour B. This is Level Number 1, and since our Depth Limit is 2, we can continue to visit the neighbour of B, i.e. D and G.
Expand the neighbour D, and Since the Depth limit is reached, backtrack to node B.
Expand the other neighbour, G. Since G is equal to the goal state, stop the search and return the path.
Hence, the resultant path is A -> B -> D -> G.
Let’s see the complexities of the above algorithm.
Time Complexity: The worst-case time complexity of DLS is O(bd), where b is the branching factor of the search tree, and d is the depth limit.
Space Complexity: The space complexity of DLS is also O(bd) since only the nodes within the depth limit are visited.
5. Iterative Deepening Depth First Search
Iterative Deepening Depth First Search ( IDDFS ) is a combination of two algorithms: DFS and DLS. It is performed in a similar way as DLS but after increasing the depth limits after every iteration.
This starts with setting the depth limit as 0 and performing the DLS to explore all the nodes at each level. If the goal state is not reached, we increase the depth limit and perform the search again up to the new depth limit.
Let’s see the algorithm to perform IDDFS.
Algorithm of Iterative Deepening Depth First Search
Set the depth limit as 0, which means the search will be performed only up to the 0th level.
Start from the initial state and perform the DLS with a current depth limit of 0.
If the goal state is found, return it.
Else, increase the depth limit by 1 and repeat the above steps.
Repeat until the goal state is reached or all the nodes are explored.
Example
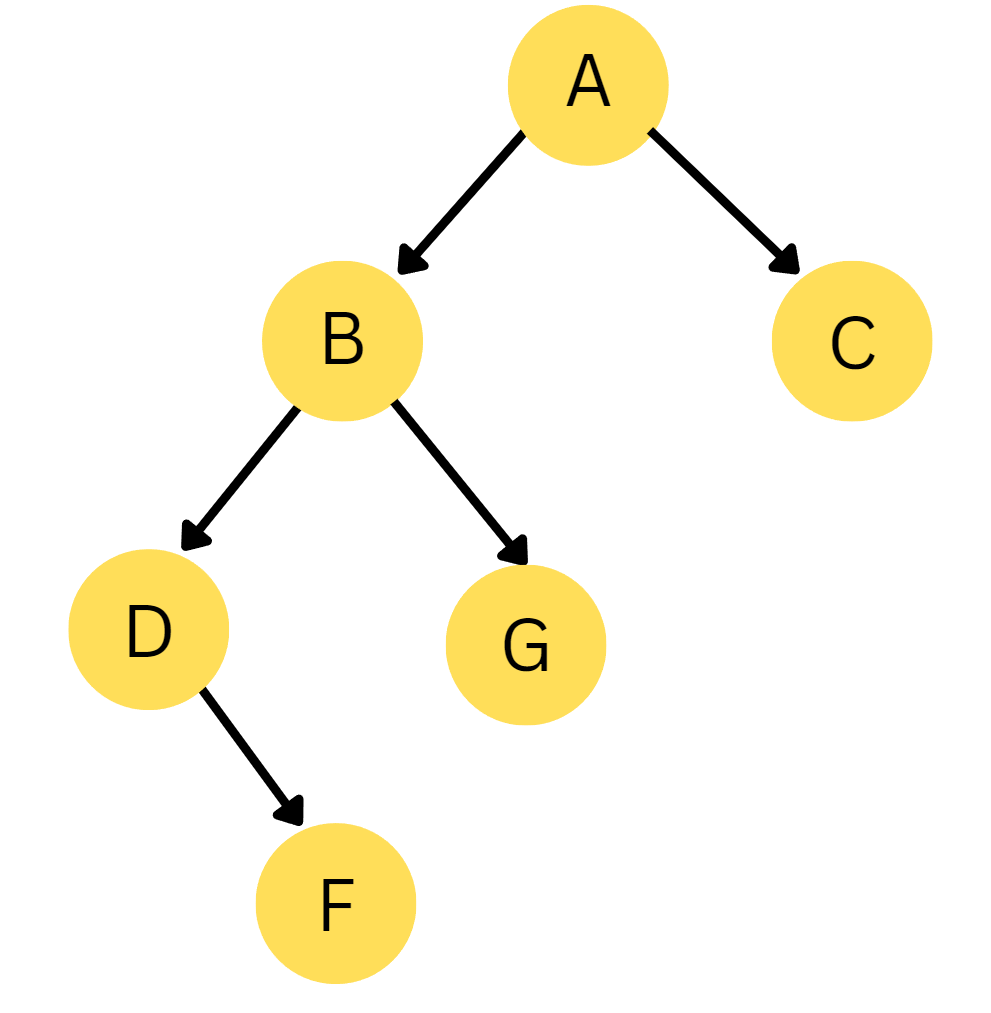
Let’s see the steps of IDDFS in the following example.
Set the depth limit as 0 and start the search from the initial state, i.e. A.
Since A is not equal to Goal Node, and there are no unexplored nodes left till level 0, Increment the limit by 1.
Again start from the initial state, A and perform DLS till level 1. Following is the explored path: A -> B -> C.
Again, the Goal Node is not found; increment the limit by 1. Now depth limit is equal to 2.
Now, the explored path is A -> B -> D -> G. Since the Goal state is found, we will stop the search.
Let’s see the complexities of the above algorithm.
Time Complexity: The worst-case time complexity of IDDFS is O(b^d), where b is the branching factor of the search tree, and d is the depth of the goal node.
Space Complexity: The space complexity of IDDFS is O(bd) since only the nodes till the current depth limit are stored.
Features of Uninformed Search Algorithms
Following are some of the features of Uninformed Search Algorithms:
These algorithms do not possess any prior information about the states or actions associated with the problem domain.
These algorithms explore the problem space systematically until they find a solution or exhaust all possibilities.
Uninformed search algorithms rely solely on the problem's definition and some predefined rules.
These algorithms guarantee a solution if a possible solution exists for that problem.
These algorithms are easy to implement as they do not require any additional domain knowledge.
Frequently Asked Questions
What is uninformed search algorithm in AI?
An uninformed search algorithm in AI refers to a search method that operates without any prior knowledge about the problem domain. It explores the search space blindly, without utilizing any heuristic information or domain-specific insights.
What are search algorithms in AI?
Search algorithms in AI are techniques used to find solutions within a problem space. These algorithms systematically explore different states or configurations of a problem to reach a desired goal state. They can range from uninformed methods like breadth-first search to informed methods like A* search.
What is breadth-first search algorithm in artificial intelligence?
Breadth-first search algorithm in artificial intelligence is a systematic search strategy that explores all neighbor nodes at the present depth level before moving on to deeper levels. It starts from the root node and explores all the nodes at the present depth level before moving to the next level.
How many types of uninformed search are there?
Uninformed search algorithms in AI typically include two main types: breadth-first search and depth-first search. Breadth-first search explores all neighbor nodes at the present depth level before moving to the next level, while depth-first search explores as far as possible along each branch before backtracking. These methods don't use domain-specific knowledge to guide the search process.
Conclusion
In this article, we discussed the Uninformed Search Algorithms in Artificial Intelligence, its features and its various types. Don’t forget to try out some examples of all the Algorithms and try to code them on your own.
You can read these articles to learn more about Search Algorithms and Artificial Intelligence.
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. For placement preparations, you must look at the problems, interview experiences, and interview bundles.
Live masterclass
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles
by Prerita Agarwal
27 Jul, 2026
12:30 PM
Multi-Agent AI Support Bot using OpenAI & Gemini
by Saurav Prateek
28 Jul, 2026
12:30 PM
Zomato Data Analysis Case Study: Ace 25L+ Roles in FoodTech(no use)
by Abhishek Soni
29 Jul, 2026
11:30 AM
Zomato Sales Analytics: SQL + PowerBI for 25LPA Jobs
by Abhishek Soni
29 Jul, 2026
11:30 AM
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles




































 9+ registered
9+ registered 

