



























Introduction
Have you ever wondered how Netflix comes to know which show will keep you hooked to your laptop screens? Or you hit the gym and put on your favourite Spotify track, and then Spotify automatically keeps playing tracks on its own and you still love each and every one of them? Well, it’s not a fluke. The recommendation engines of these apps are sophisticatedly designed to provide you with products of your choice. They constantly try to learn more and more about you by keeping track of your interactions within the app and devising some underlying recurring patterns. Suppose you recently acquired a taste for the rock and roll genre. Your last four Spotify tracks have been about rock and roll. The app is likely to recommend similar tracks for at least a brief period of time until it learns a shift in your user activity. The technique used to design these intelligent recommendation engines is known as Unsupervised Machine learning.
Unsupervised Learning is one of the three broadly classified Machine Learning techniques. The objective of unsupervised learning is to infer patterns without a target variable. Unlike supervised learning, where the objectives are well defined, i.e, we are supposed to find out the dependent or the target variable, in unsupervised learning we don’t have any defined objectives. We are supposed to extract all the relevant observations and results by critically studying the data points.
Commonly known supervised learning algorithms cannot be directly applied in unsupervised learning techniques.
Some Popular Unsupervised Learning Techniques
Unsupervised learning models are employed for three major tasks:-
- Clustering
- Association
- Dimensionality Reduction
Clustering
Grouping of similar data points within an unlabelled dataset is called clustering. This is one of the most popular techniques in Data Science. The data points are closely related to the other data points within their cluster. However, this might not mean there are no similarities between data points of different clusters. This is an ideal case scenario that is unlikely to occur in real-world applications. But the aim should be to minimise these similarities between data points of different clusters as much as possible. Clustering are of various types:- Exclusive, Overlapping, Hierarchical, and probabilistic.
Exclusive Clustering
Exclusive clustering prescribes that a data point can’t be shared among different clusters, i.e, any data point cannot be part of more than one cluster. This clustering technique is also referred to as “Hard clustering”. K-means algorithm works on the principle of Exclusive clustering.
In K means clustering, data points are assigned into K groups (where K refers to the number of groups or clusters) depending on their distance from the centroid. More groups (higher value of K) would imply more specificity of the clusters and vice versa. It’s important to remember that we need to take an optimised K value to avoid overfitting or underfitting.
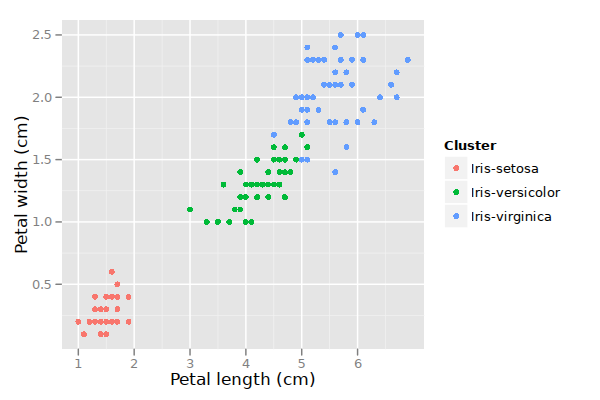
Source: Link
Above is an implementation of K-means clustering where we have clustered flowers based on their petal length and width. The dataset used is iris dataset which is available on the internet. We would recommend having a look at the dataset for a better understanding.
Overlapping Clustering
Sometimes It might not be possible to put a data point into one cluster. This is where Soft clustering comes in. Overlapping clustering allows sharing of data points with a degree of memberships in different clusters. A well-known example of overlapping clustering is soft k means clustering.
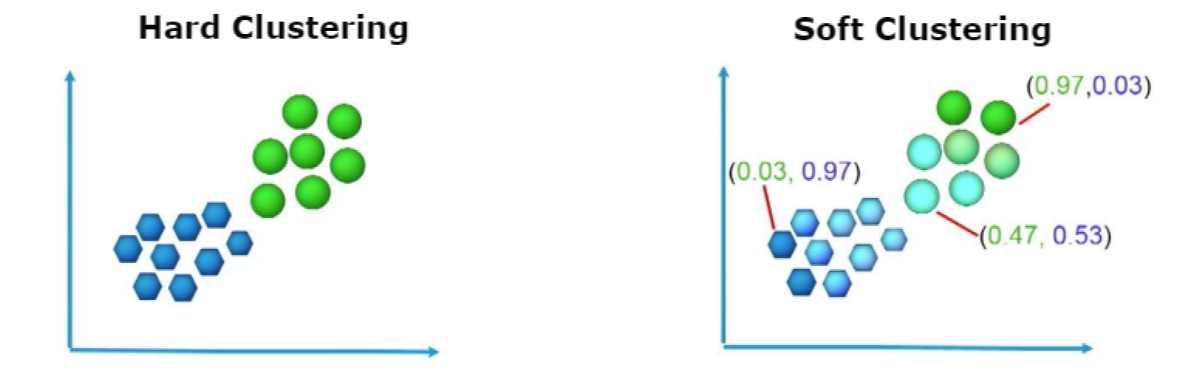
Source - www.TowardsDataScience.com)
The above graphs show how Soft k-means differs from conventional or Hard k-means in clustering methods.
Hierarchical Clustering
Hierarchical Clustering can be classified into two ways:-
- Agglomerative Clustering:- It’s a bottom-up approach of clustering the data points. Have a look at the figure below for a better understanding.
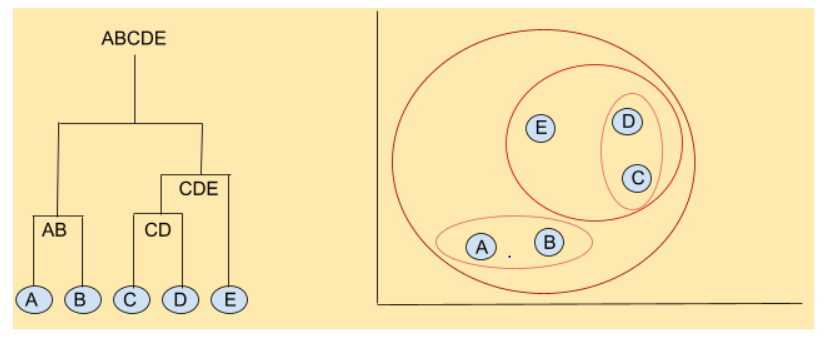
In Agglomerative Clustering, we start from individual data points, steadily building clusters (iterative clustering) in a hierarchical manner until all the data points in the data set are a part of one single cluster.
The tree-like structure depicting the hierarchy is known as a dendrogram.
These clusterings are done on the basis of similarity between the data points. Various methods are employed to gauge these similarities, like ward’s linkage, average linkage, complete linkage, and single linkage.
- Divisive Clustering: Divisive Clustering is a top-down approach, polar opposite of Agglomerative Clustering. In this case, we start from a single cluster consisting of all the data points, dividing them into smaller clusters for granularity of data patterns. Divisive Clustering isn’t commonly preferred over agglomerative clustering.
Probabilistic Clustering
Probabilistic Clustering assigns data points with a probability of belonging to certain distribution. It differs from hard clustering in a way that it doesn’t assign every data point to a certain cluster with absolute certainty. This way it’s more flexible with its clustering methods. Gaussian Method Model is the most popular technique to implement probabilistic clustering. GMMs determine in which distribution a data point belongs.

 9+ registered
9+ registered 

