Hierarchical Clustering
It says, let's put all the data into one cluster called root, and continuously divide the data into smaller groups till the point where we have reached the termination condition that we have decided. For example, we chose not to divide the cluster further if the total data points are less than 50. So Hierarchical Clustering says that one data point does not belong to only one cluster; rather, it belongs to many clusters.
Source: statisticshowto.com
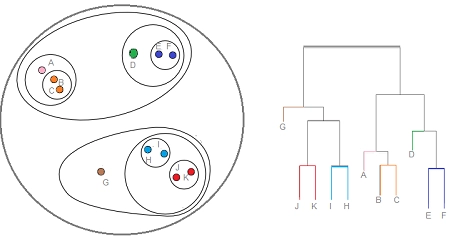
The root cluster is the entire data point (A,B,C,D,E,F,G,H,I,J,K). Data point J belongs to many clusters (J,K), (I,J,K,H), (I,J,K,H,G), and similarly for others as well.
Flat Clustering
One data point is either entirely inside or entirely outside a cluster in Flat Clustering. Here we have to decide the number of groups to form.
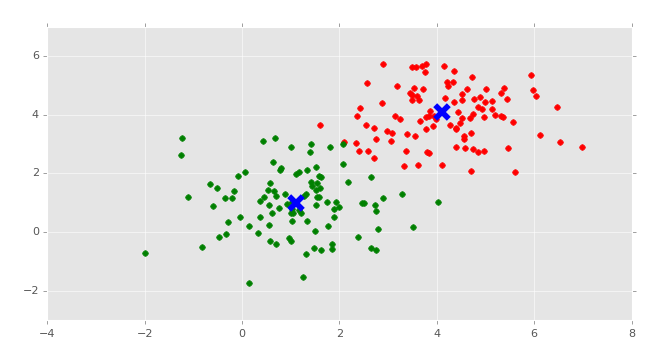
Source: pythonprogramming.net
There are two clusters, and each data point is properly inside either of the clusters.
Association
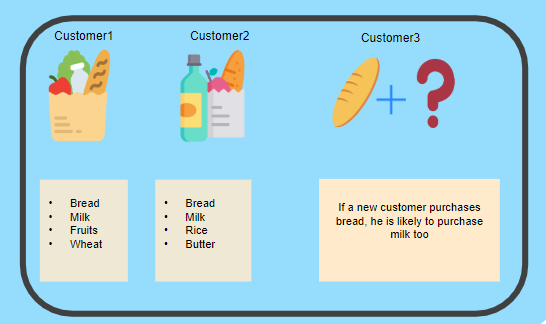
Association tries to find the relationship between the data points. It determines the set of data that is likely to occur together in the dataset. For example, In a shopping mall, the items that a person buys are associated so that if they purchase the butter, most of them also buy milk. The Unsupervised Learning model learns the pattern from this data, and now if another person comes to buy butter, the model tells them that they are more likely to buy the milk.
Source: simplilearn.com
Applications of Unsupervised Learning
- Market Segmentation: In Market Segmentation problems, we group the customers based on their age, gender, etc., to know the interest of each group to provide the best they prefer.
- Customer Segmentation: We divide customers of a company into groups having similarities in each group.
- Product Segmentation: Product Segmentation is when a company modifies its product into different products to gain the customer's attention.
- Recommendation systems: Recommendation systems recommend things to the user based on their searches and interests.
FAQs
Q1) What are popular Unsupervised Learning algorithms?
The popular Unsupervised Learning algorithms are:
- K-means clustering.
- KNN (k-nearest neighbors)
- Hierarchical clustering.
- Anomaly detection.
- Neural Networks.
Q2) In Hierarchical clustering, a data point belongs to how many clusters?
Data point belongs to the number of levels of Hierarchy.
Q3) What do K denote in K Means clustering?
K denotes the number of clusters
Q4) What is Anomaly detection?
Anomaly detection is the process to identify the dissimilar items between the datasets that differ from the norm
Q5) What are the cons of Unsupervised Learning?
Following are the cons of Unsupervised Learning
a) The result predicted is less accurate than the actual because input data is not labeled in advance
b) It is costlier as it might require human intervention to understand the patterns and correlate them with the domain knowledge.
Key Takeaways
So this comes to the end of the discussion about the basics of Unsupervised Learning. I hope I was able to impart the adhered knowledge with ease. For more information you may visit
https://www.codingninjas.com/courses/machine-learning
Thank you a lot, Keep Learning, Keep growing 😇😇




























 6+ registered
6+ registered 

