Do you think IIT Guwahati certified course can help you in your career?
Introduction
Machine learning is a subset of Artificial Intelligence that enables computers to learn from the data independently. Previous algorithms needed human intervention to change the code to improve the functioning. Machine learning models require training from data. One of the most common learning methods is gradient-based learning. However, machine learning practitioners encounter some problems when our model has a large number of layers and also when using backpropagation. These problems are called Vanishing and exploding gradients. Let us look at these problems and how we can mitigate them.
Gradient-based Learning
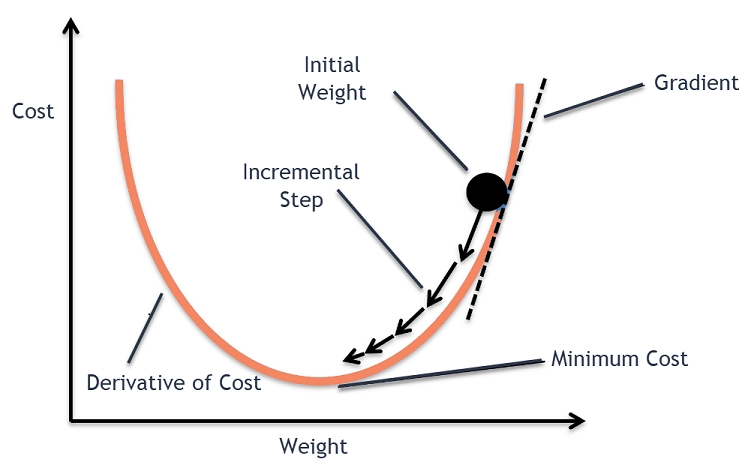
Let us take a quick look at gradient-based learning. The main aim of gradient-based learning is to minimize the loss function. A gradient is simply the slope of a function. Gradient learning aims to travel down the slope of the loss function until we reach local minima.
We travel down the slope by changing the parameters after each step.
Backpropagation
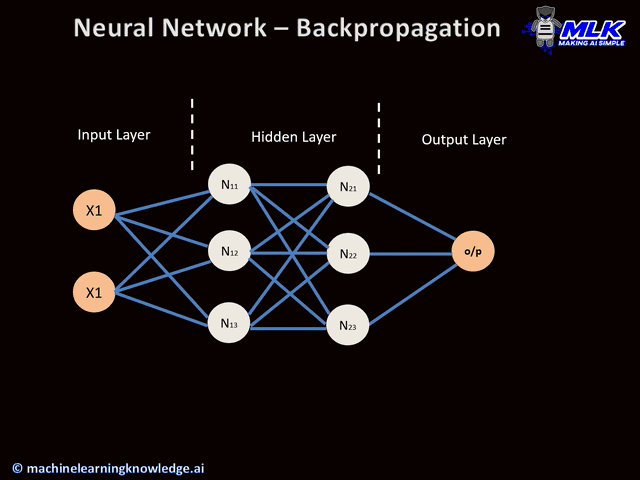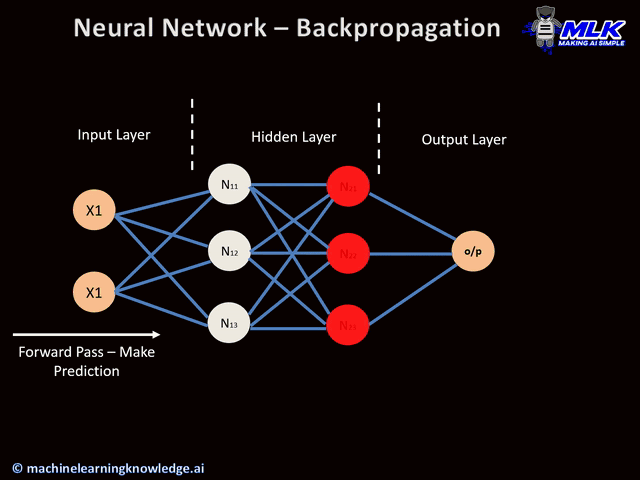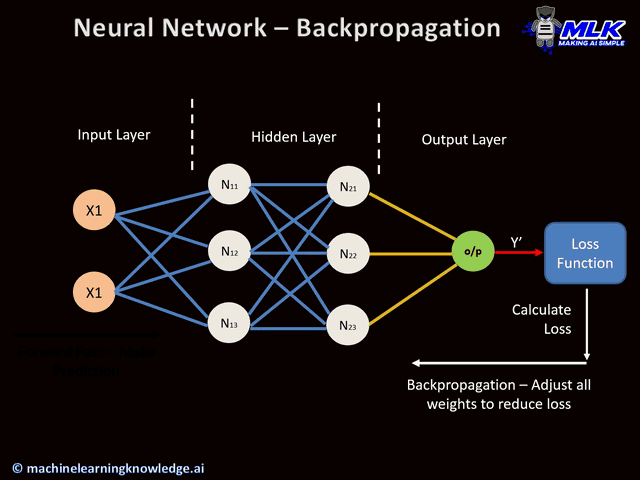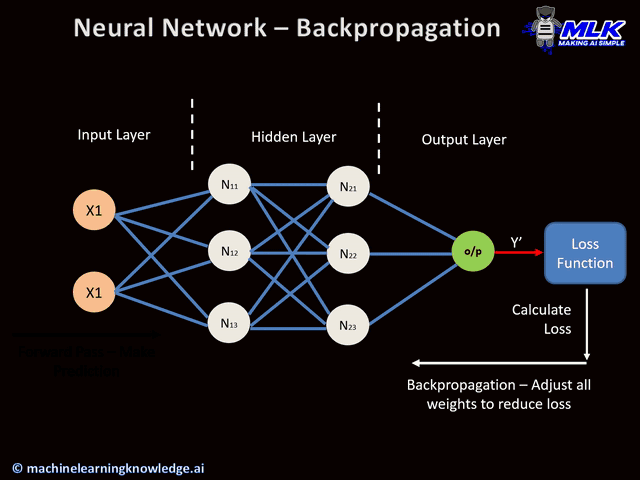
Backpropagation is a common method to calculate the derivatives of a neural network. It calculates the gradient of the loss function with respect to the neural network’s weights. Backpropagation calculates the gradients and then feeds them back to the first layer of the network. This allows us to calculate the gradients of each layer more precisely.
We use the chain rule of calculus to calculate the gradient at a particular layer. All the gradients of the following layers are combined to calculate the gradient of a layer.
The backpropagation algorithm has enabled the supervised learning of neural networks.
Backpropagation allows us to effectively train a neural network. However, it is seen that if we use a large number of layers in our network. The performance of our network decreases absurdly, and sometimes, it becomes impossible to train. This is due to vanishing or exploding gradients. It occurs due to the repeated calculation of gradients using the chain rule.
Vanishing gradients
Vanishing gradient arises when we repeatedly multiply the gradient with a number smaller than one. Due to this, the gradient becomes smaller and smaller in each step and becomes infinitesimally small. Due to the small gradient, the step size approaches zero, and as a result, we can never reach the optimum position of our loss function.
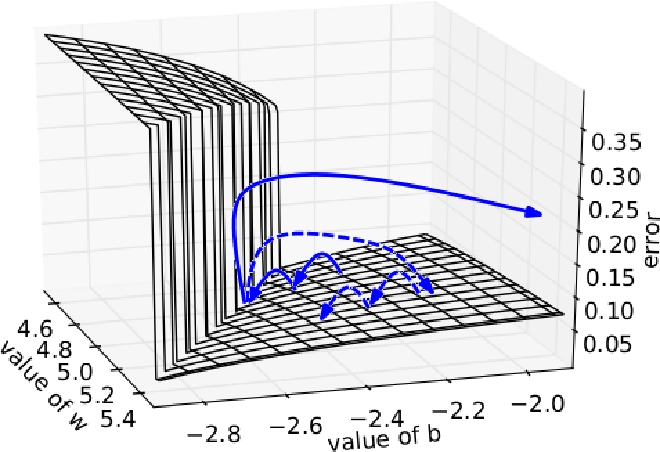
On the other hand, if we keep on multiplying the gradient with a number larger than one. The gradient keeps increasing and can become so large that it makes our network unstable. Sometimes, the parameters can become so large that they result in NaN values. NaN stands for not a number. It represents undefined values.
We can see below the size of the step keeps on increasing with each iteration due to an increase in the gradient. After some iterations, the parameters overflow, and it results in an error.
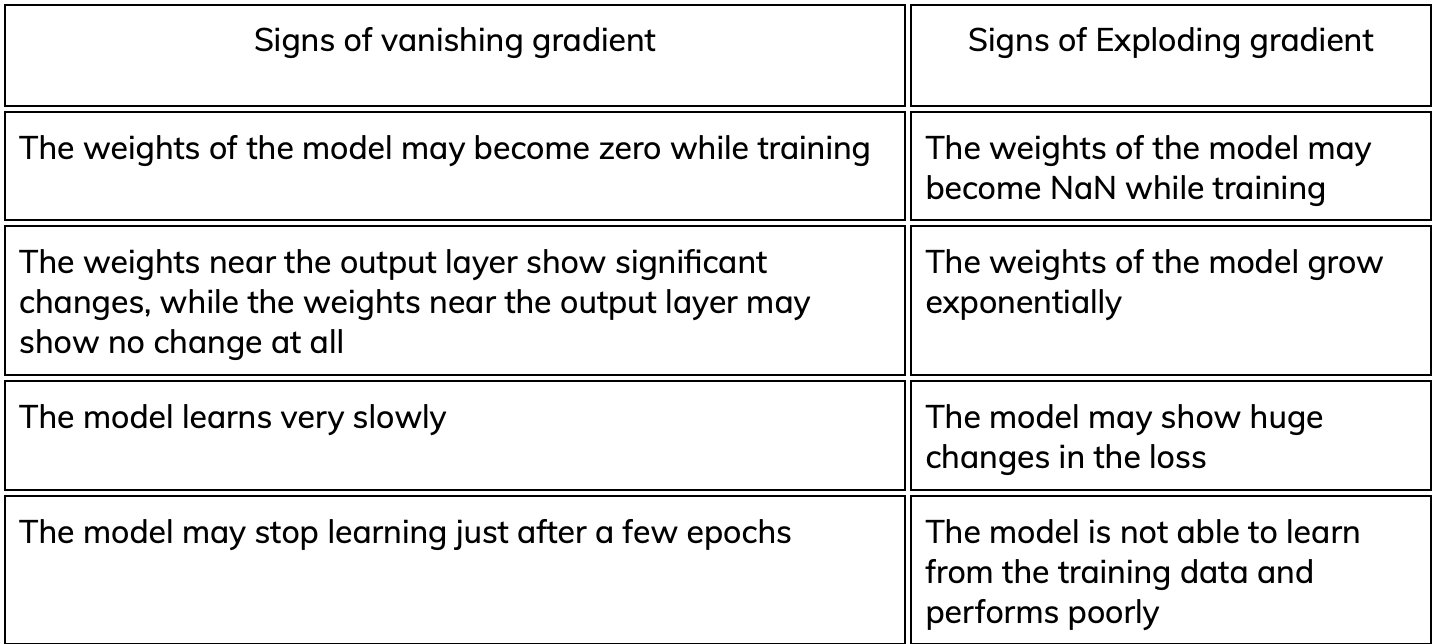
How to identify vanishing/Exploding gradient problem?
It is essential to identify if our model has these problems to train our model correctly.
How to solve the problem of Vanishing/Exploding gradients
Using less number of layers
A straightforward approach to solving vanishing and exploding gradient problems is to use less number of layers in our network. Using fewer layers will ensure that the gradient is not multiplied too many times. This may stop the gradient from vanishing or exploding, but it does cost us the ability of our network to understand complex features.
Careful weight initialization
We can solve both of these problems partially by carefully choosing our model parameters initially.
Using the correct activation functions
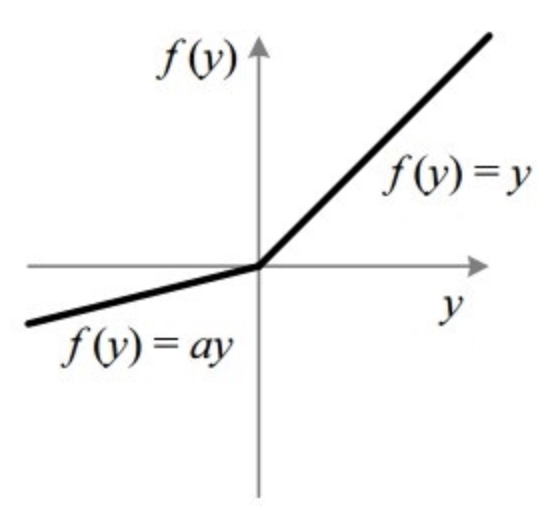
Saturating functions such as sigmoid saturate the larger inputs and causes vanishing gradient problem. We can use non-saturating activation functions such as ReLU and its alternatives.
An example of such a non-saturating activation function is leaky ReLU.
Using batch normalization ensures that vanishing/exploding gradients do not appear in between the layers.
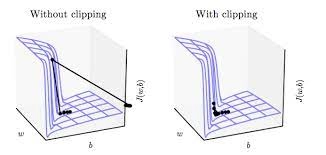
Gradient clipping
It is a popular method used to solve the exploding gradient problem. It limits the size of the gradients so that they never exceed some specified value.
We should use the layers such that our model can understand the features that we want from our data and, at the same time, do not cause problems.
What are some of the other non-saturating activation functions?
ReLU activation functions and their derivatives are all non-saturating. ELU activation function is also a non-saturating activation function.
Can we train our model without backpropagation?
Yes, we can train our model without backpropagation, but our model will perform poorly without it.
Conclusion
In this article, we talked about vanishing and exploding gradients. We look into the concept of gradient-based learning and backpropagation and how it may cause these problems. We also learned to identify them and looked into some of the methods to solve the problem of vanishing and exploding gradients.































 9+ registered
9+ registered 

