Vectorizing Logistic Regression’s Gradient Computation
Till now, we have seen the forward propagation of the logistic regression. Calculating activation of every training example and storing it in (1,m) numpy matrix simultaneously.
In this section, we will see the vectorized implementation of logistic regression, i.e., gradient computation for logistic regression.
So, dz(1) for the first training example will be a(i) - y(i), for the second training example, dz(2) will be a(2) - y(2), similarly for mth training example, dz(m) will be a(m) - y(m).
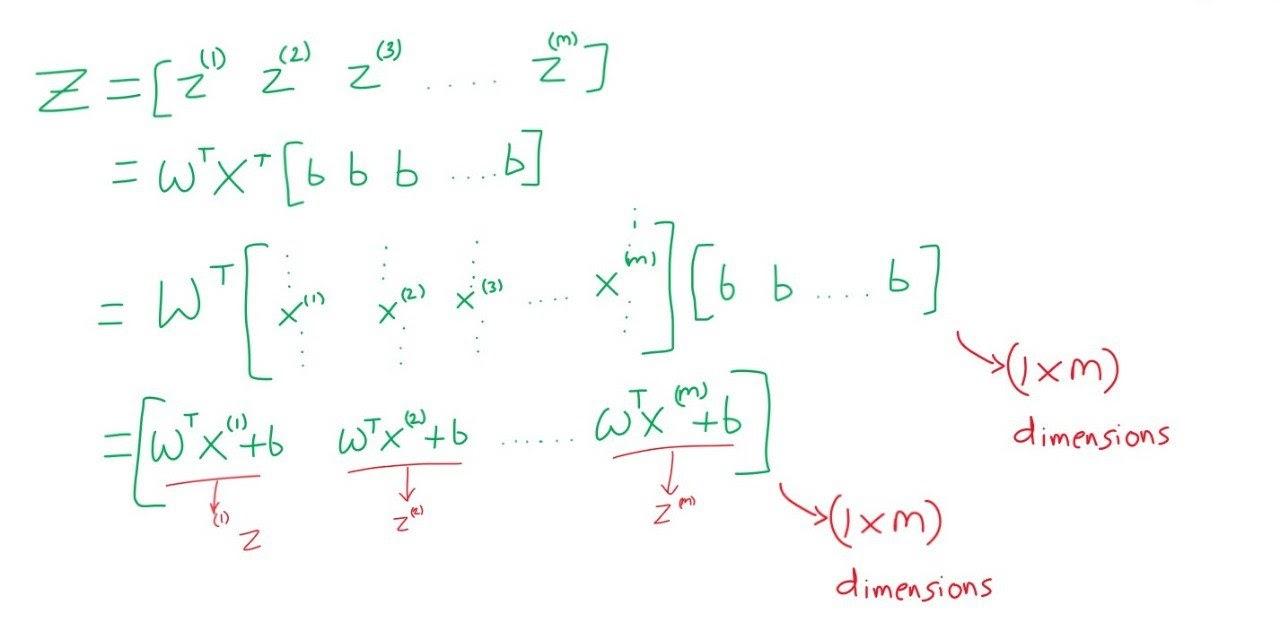
Let us consider a row matrix dZ of (1 by m) that will stores dz of all the training examples. dZ can be simplified as shown below.
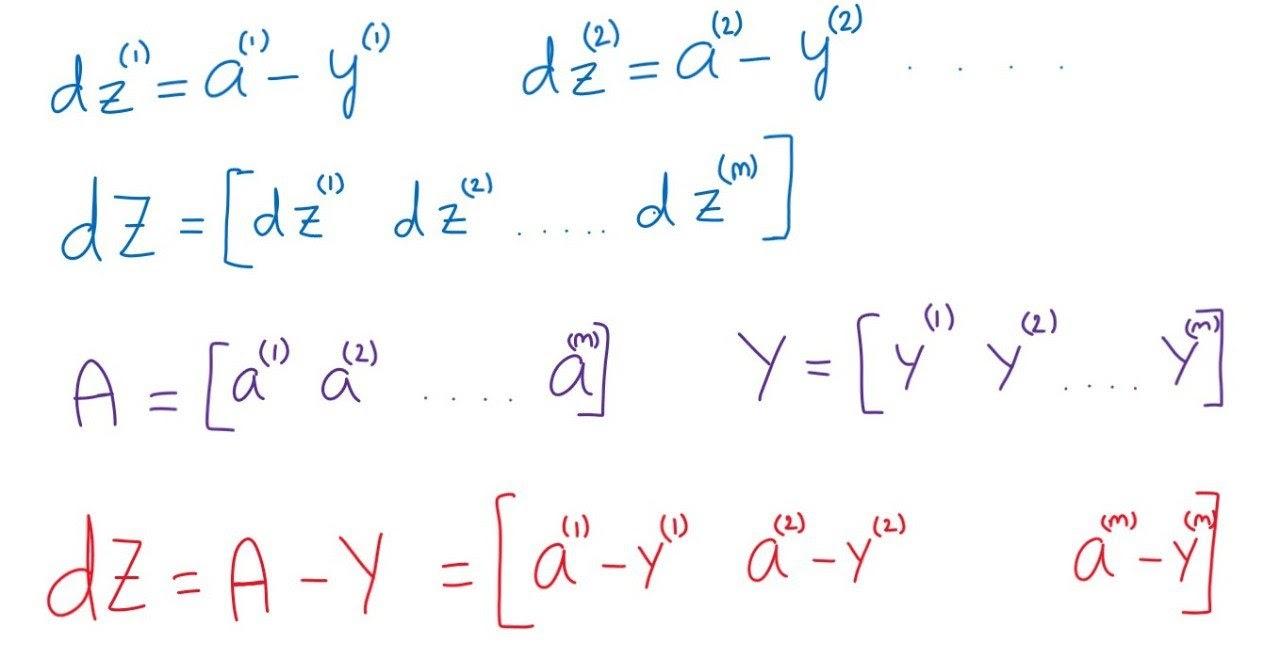
After calculating dZ we need to calculate dw and db. The normal way to calculate is shown below.
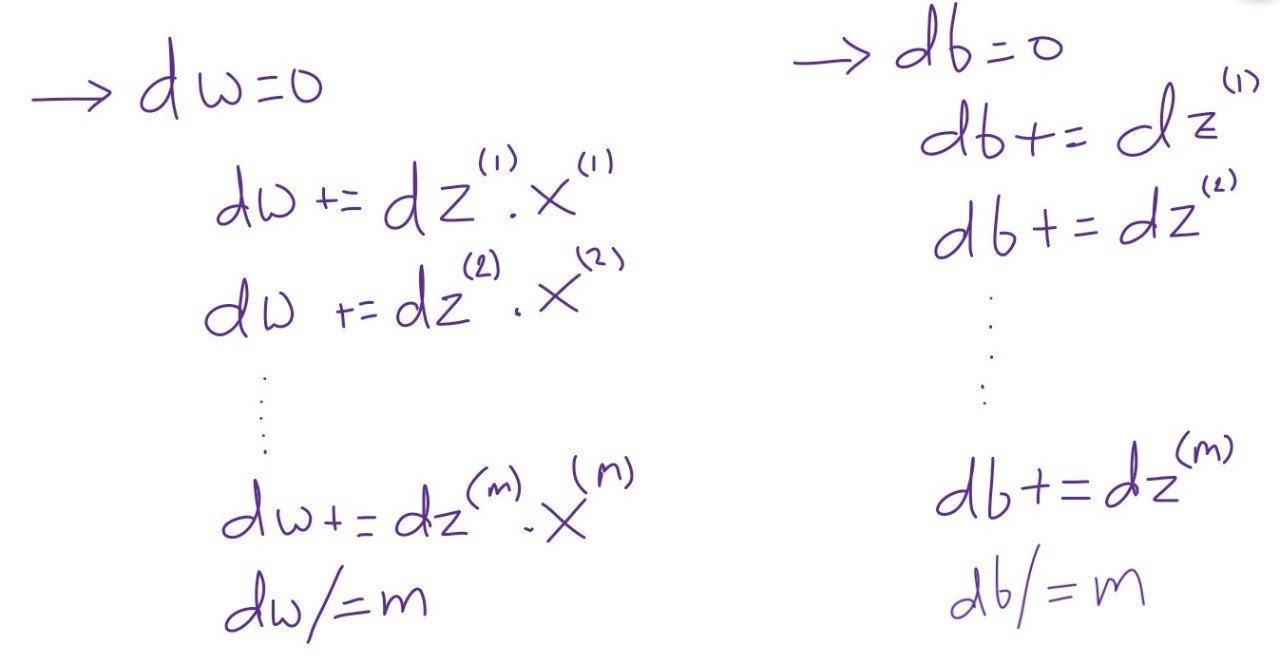
In the above process of calculating “dw” and “db”, we need to iterate over m training examples.
As shown below, we can use the vectorization method to avoid this iteration.
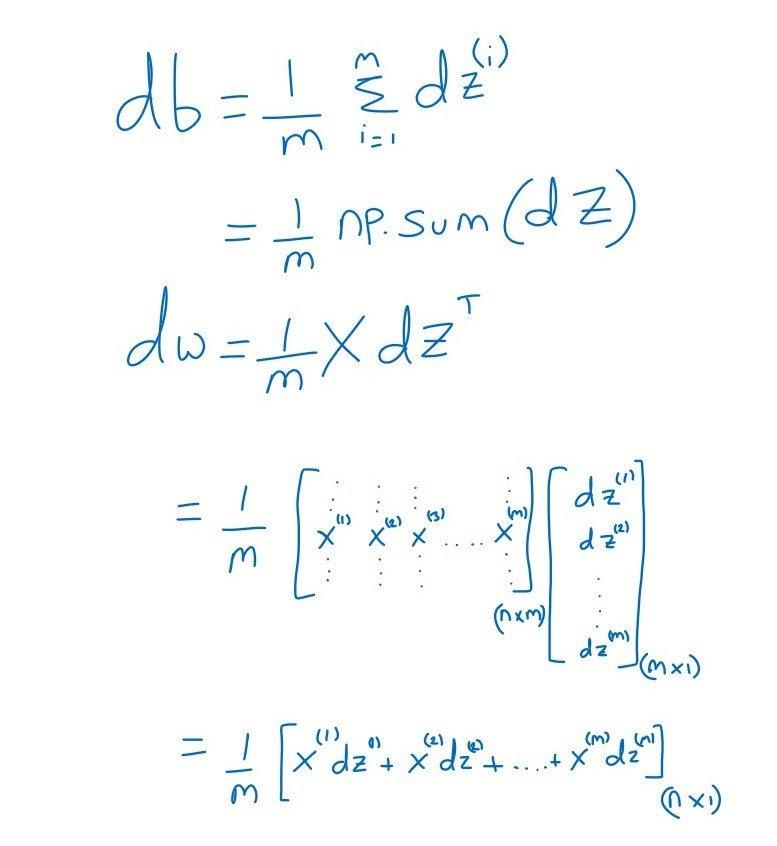
Now we will update w and b as shown below.
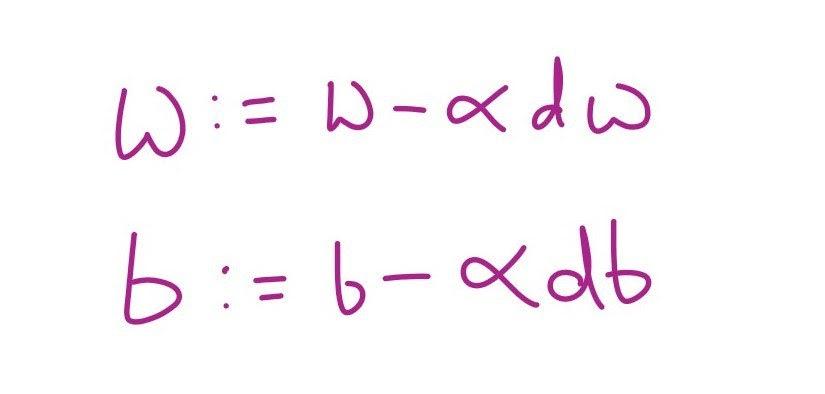
Here 𝛂 is the learning rate in the gradient descent algorithm. If you want thousands of iterations, simply run a loop a thousand times for the above process to minimize the error and adjust the weights.
Above are the steps for vectorizing logistic regression.
Implementation
Simple logistic regression
Let us see the Standard and optimized technique of logistic regression.
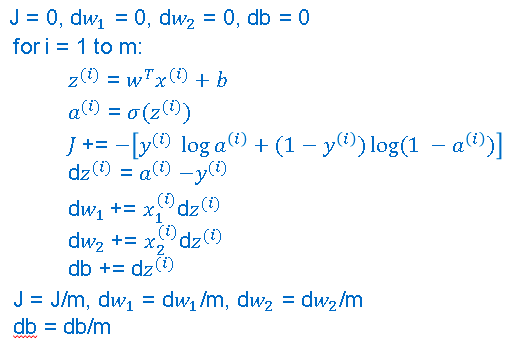
source
The above code shows the standard way of implementing logistic regression.
Vectorized code for logistic regression
#logistic regression
class LogitRegression() :
def __init__( self, learning_rate, iterations ) :
self.learning_rate = learning_rate
self.iterations = iterations
# model training function
def fit( self, X, Y ) :
# m = number of training examples
# n = number of features
self.m, self.n = X.shape
# weights of the model
self.W = np.zeros( self.n )
self.b = 0
self.X = X
self.Y = Y
# gradient descent
for i in range( self.iterations ) :
self.update_weights()
return self
# updating weights
def update_weights( self ) :
A = 1 / ( 1 + np.exp( - ( self.X.dot( self.W ) + self.b ) ) )
# calculating gradients
tmp = ( A - self.Y.T )
tmp = np.reshape( tmp, self.m )
dW = np.dot( self.X.T, tmp ) / self.m
db = np.sum( tmp ) / self.m
# updating weights
self.W = self.W - self.learning_rate * dW
self.b = self.b - self.learning_rate * db
return self
# hypothesis function h(x)
def predict( self, X ) :
Z = 1 / ( 1 + np.exp( - ( X.dot( self.W ) + self.b ) ) )
Y = np.where( Z > 0.5, 1, 0 )
return Y

You can also try this code with Online Python Compiler
Also see, Artificial Intelligence in Education
Frequently Asked Questions
-
Why vectorize the logistic regression?
Logistic regression in vectorized form takes less time. It does not have any loop for iterating over the dataset. It is easy to implement.
-
Is logistic regression a generative or a descriptive classifier? Why?
Logistic regression is a descriptive model. Logistic regression learns to classify by knowing what features differentiate two or more classes of objects.
-
According to you, is the method to fit the data in logistic regression best?
Maximum Likelihood Estimation to obtain the model coefficients related to the predictors and target.
Key Takeaways
- In this article, we have learned vectorized form of logistic regression.
- Implementation of logistic regression in vectorized form.
Hello readers, here's a perfect course that will guide you to dive deep into Machine learning.
Happy Coding!



























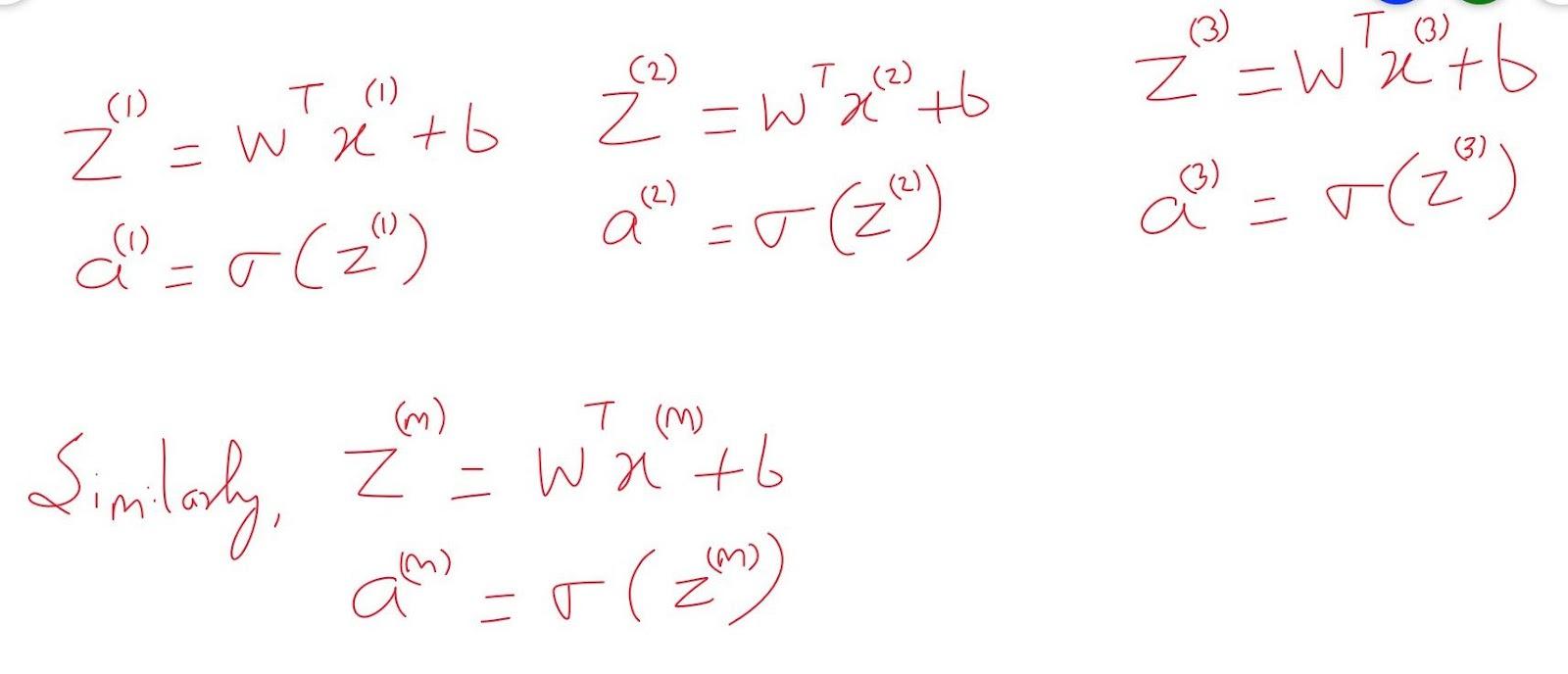
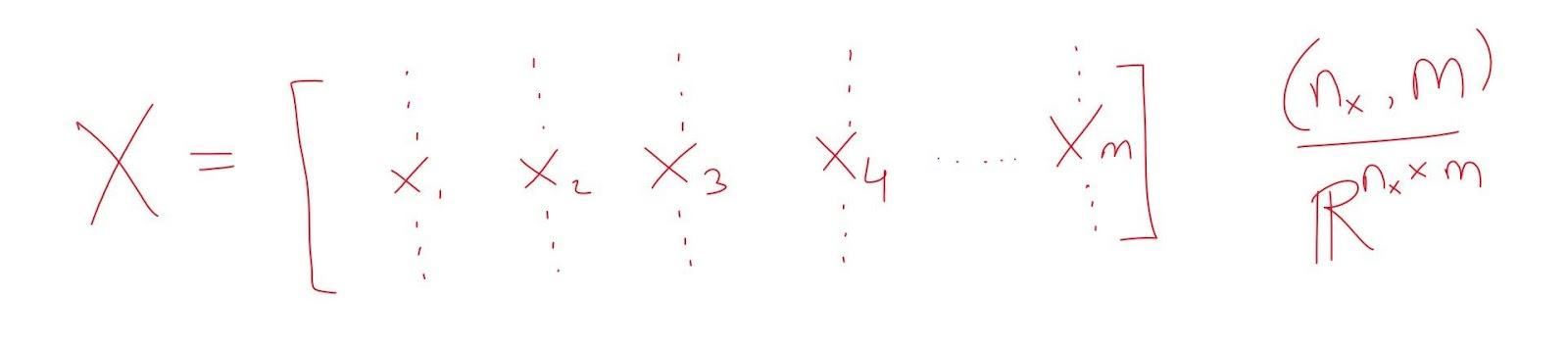
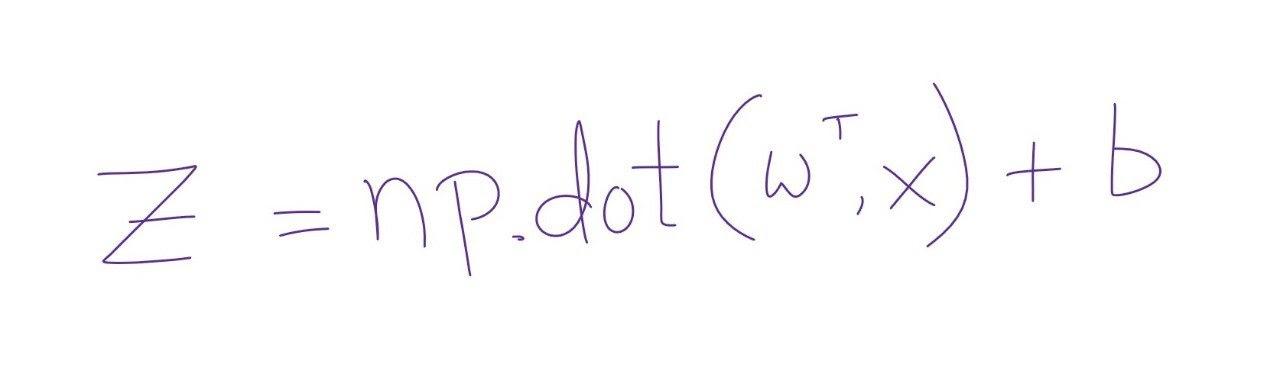
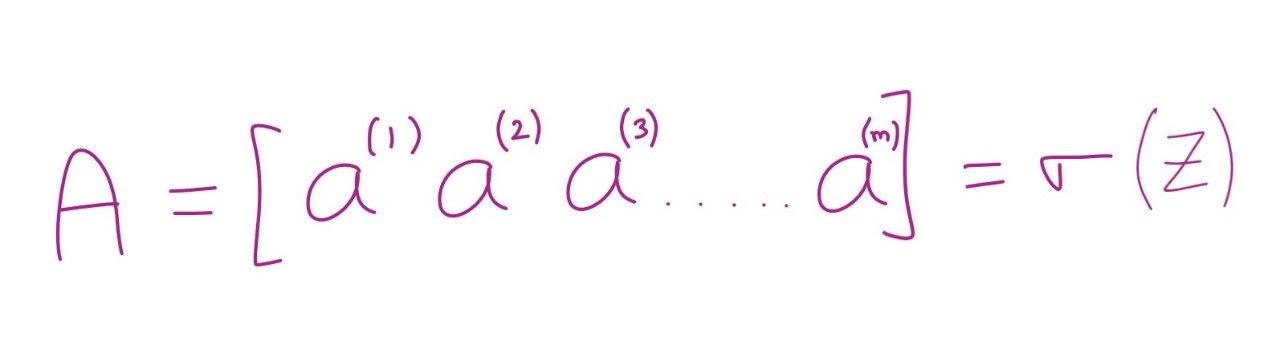


 9+ registered
9+ registered 

