Do you think IIT Guwahati certified course can help you in your career?
Introduction
Matching Engine provides tooling to build use cases that match semantically similar items. More specifically, given a query item, the matching engine searches a huge corpus of candidate items for the items that are most semantically similar to the query item. Many real-world use cases exist for this capacity to search for items that are semantically related or similar, and it is an essential component of apps like:
Recommendation engines
Search engines
Ad targeting systems
Image classification or image search
Text classification
Question answering
Chat bots
The following illustration shows how this technique can be applied to the problem of finding books, from a database, that is the best semantic match to an input query.
Using Machine Engine
Set up a VPC Network Peering connection
To reduce network latency for vector matching online queries, call the Vertex AI service endpoints from your Virtual Private Cloud (VPC) by using Private Service Access. For each Google Cloud project, only one VPC network can peer with Matching Engine. If you already have a VPC with private services access configured, you can use that VPC to peer with Vertex AI Matching Engine.
Access control with IAM
Vertex AI utilizes Identity and Access Management (IAM) to manage resource access. Assigning one or more roles to a user, group, or service account to grant access to a resource.
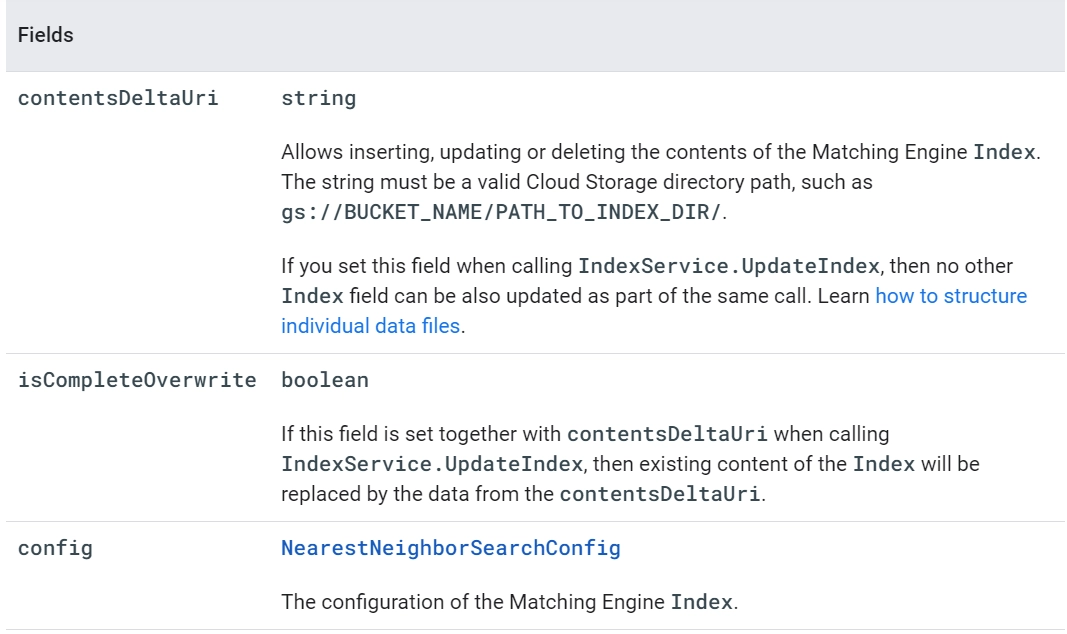
Input data format and structure
To build a new index or update an existing index, provide vectors to Matching Engine in the format and structure like:
Structure your input data directory as follows:
Batch root directory: Create a root directory for each batch of input data files. Use a single Cloud Storage directory as the root directory. In the following example, the root directory is named batch_root.
File naming: Place individual data files directly under batch_root and name them by using the suffix .csv, .json, or .avro, depending on which file format you use.
Delete directory: You can create a delete subdirectory under batch_root. This directory is optional.
Manage indexes
We can create, delete, or update indexes using an index metadata file.
Deploy and manage indexes
Deploying an index includes the following three tasks:
Create an IndexEndpoint if needed, or reuse an existing IndexEndpoint.
Get the IndexEndpoint ID.
Deploy the Index to the IndexEndpoint.
Query indexes to get the nearest neighbors
Each DeployedIndex has a DEPLOYED_INDEX_SERVER_IP, which you can retrieve by listing IndexEndpoints. To query a DeployedIndex, connect to its DEPLOYED_INDEX_SERVER_IP at port 10000 and call the Match or BatchMatch method.
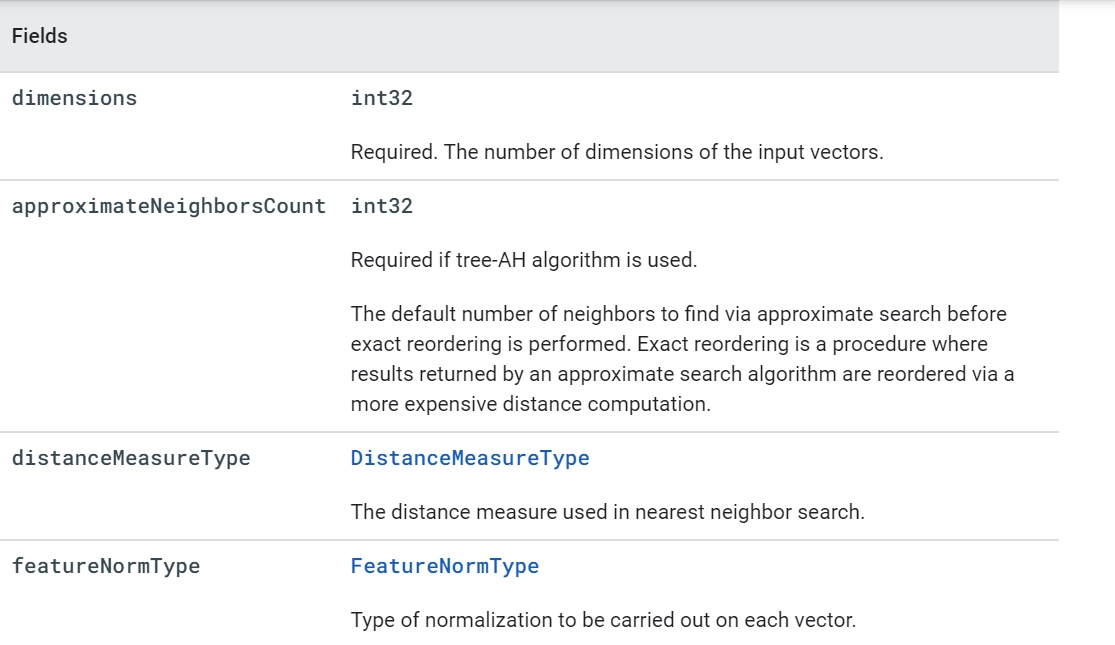
Tuning the index
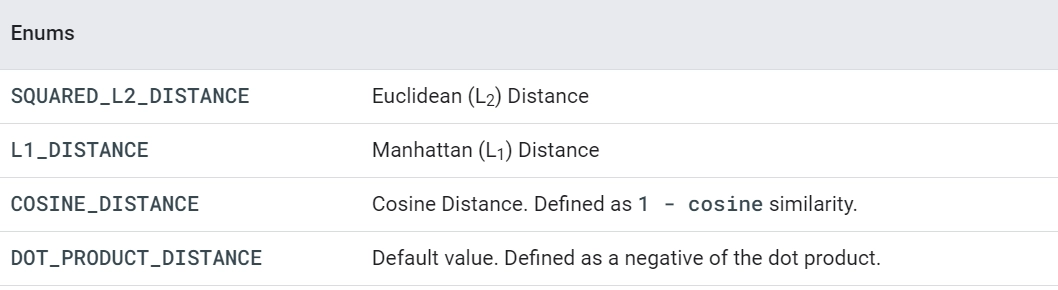
Tuning the index requires setting the configuration parameters that impact the performance of deployed indexes, especially recall and latency. These parameters are set when the index is created. You can use brute force indexes to measure recall.
Monitor the IndexEndpoint
Google provides two metrics for monitoring the IndexEndpoint:
Using Boolean criteria, the Vertex AI Matching Engine allows you to limit vector matching searches to a portion of the index. Matching Engine is told which vectors in the index to disregard by boolean predicates.
Vector attributes
Each vector in a database of vectors is described by zero or more characteristics (or tokens) from each of multiple attribute categories in a vector similarity search (or namespaces).
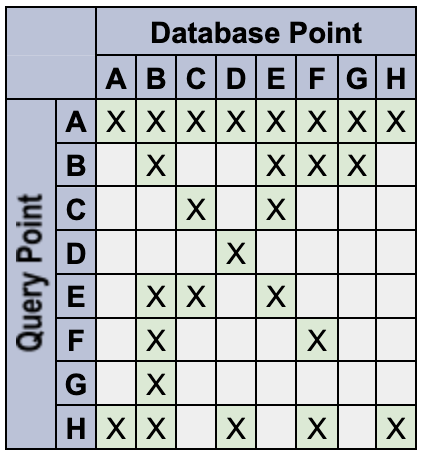
A colour and a shape are assigned to vectors in the sample application below:
shape and color are namespaces.
blue and red are tokens from the color namespace.
circles and squares are tokens from the shape namespace.
Specify vector attributes
The following code examples identify vector attributes in the example application:
To specify a "green circle": {color: green}, {shape: circle}.
To specify a "red and purple square": {color: red, purple}, {shape: square}.
To specify an object with no color, omit the "color" namespace in the restricts field.
Queries
Queries express an AND logical operator across namespaces and an OR logical operator within each namespace. A query that specifies {color: red, purple}, {shape: square, circle}, matches all database points that satisfy (red || purple) && (square || circle).
A query that specifies {color: green}, matches all green objects of any kind, with no restriction on shape.
Denylist
Google supports denylist tokens, a type of negation that enables more complex scenarios. Any datapoint that contains the token is not included in matches when a query denylists a token. In the same way that an empty namespace matches with all points, if a query namespace only contains denylisted tokens, all points that are not explicitly denylisted match.
Datapoints can also denylist a token, preventing any queries with that token from matching.
For example, define the following data points with the specified tokens:
{} // empty set matches everything
{red} // only a 'red' token
{blue} // only a 'blue' token
{orange} // only an 'orange' token
{red, blue} // multiple tokens
{red, !blue} // deny the 'blue' token
{red, blue, !blue} // a weird edge-case
{!blue} // deny-only (similar to empty-set)
The system behaves as follows:
Empty query namespaces are match-all wildcards. For example, Q:{} matches DB:{color:red}.
Empty datapoint namespaces are not match-all wildcards. For example, Q:{color:red} doesn't match DB:{}.
Train embeddings by using the Two-Tower built-in algorithm
Using labelled data, the Two-Tower model trains embeddings. The Two-Tower model places linked objects in the same vector space by pairing comparable categories of objects, such as user profiles, search queries, web publications, response passages, or photos. The inquiry tower and the candidate tower are the two encoder towers that make up the two-tower model. These towers incorporate separate things into a common embedding space, enabling Matching Engine to retrieve items that are similarly matched.
Input Data
The Two-Tower built-in algorithm expects two inputs:
Training data: Pairs of documents used to train the model. The following are supported file formats: JSON Lines and TFRecord
Input schema: A JSON file with the schema of the input data, plus feature configurations.
Training data
Pairs of query and candidate documents make up the training data. Only positive pairs, when the query and candidate documents are deemed to match, need to be provided. It is not recommended to train with negative pairs or partial matches.
There are several user-defined features in query and candidate documents. the algorithm currently supports the following feature categories:
Input schema
The training input's structure and feature configurations are described in the input schema, which is a JSON file. The input schema also has two keys: candidate and query, which denote the input schemas of the candidate and query documents, respectively.
An Id feature requires:
num_buckets: The number of hash buckets of the ID feature. If the number of IDs is small, we recommend that the number of buckets equal the number of IDs.
A Categorical feature requires:
vocab: A list of all possible values (strings) for this feature. Any unknown (out-of-vocabulary) categorical value that is encountered is encoded as a separate out-of-vocabulary value.
A Text feature can have:
embedding_module: Optional: A string that specifies the underlying text embedding module.
A Vector feature requires:
length: A positive integer that represents the length (dimension) of the vector input.
Training
To perform single-node training with the Two-Tower built-in algorithm, use the following command. This command creates a CustomJob resources that uses a single CPU virtual machine (VM) instance. For information about the flags you can use during training, see Flags. With single-node training, the parameters training_steps_per_epoch and eval_steps_per_epoch are optional.
# Set a unique name for the job to run.
JOB_NAME = f'two_tower_cpu_{dataset_name}_{timestamp}'
# URI of the Two-Tower Docker image.
LEARNER_IMAGE_URI = 'us-docker.pkg.dev/vertex-ai-restricted/builtin-algorithm/two-tower'
# The region to run the job in.
REGION = 'us-central1'
# Set the training data and input schema paths.
TRAINING_DATA_PATH = f'gs://cloud-samples-data/vertex-ai/matching-engine/two-tower/{dataset_name}/training_data/*'
INPUT_SCHEMA_PATH = f'gs://cloud-samples-data/vertex-ai/matching-engine/two-tower/{dataset_name}/input_schema.json'
# Set a location for the output.
OUTPUT_DIR = f'gs://{your_bucket_name}/experiment/output'
# Batch size and number of epochs to train.
TRAIN_BATCH_SIZE = 100
NUM_EPOCHS = 10
!gcloud beta ai custom-jobs create \
--display-name={JOB_NAME} \
--worker-pool-spec=machine-type=n1-standard-8,replica-count=1,container-image-uri={LEARNER_IMAGE_URI} \
--region={REGION} \
--args=--training_data_path={TRAINING_DATA_PATH} \
--args=--input_schema_path={INPUT_SCHEMA_PATH} \
--args=--job-dir={OUTPUT_DIR} \
--args=--train_batch_size={TRAIN_BATCH_SIZE} \
--args=--num_epochs={NUM_EPOCHS}
Create embeddings Swivel pipeline
The Submatrix-wise Vector Embedding Learner (Swivel) algorithm can be used with Vertex AI Pipelines to train embedding models.
Swivel is used to create item embeddings from an item co-occurrence matrix. The co-occurrence matrix of items can be calculated for structured data, such as purchase orders, by counting the number of orders that include products A and B for each product you wish to build embeddings for.
The Swivel pipeline template can be used to create embeddings from your own text or structured data by following the steps listed below. The actions are taken to consist of:
Setup: Enable APIs, grant permissions, and prepare input data.
Configure parameters: Set the appropriate parameter values for the Swivel job.
Train on Vertex AI Pipelines: Create a Swivel job on Vertex AI Pipelines using the Swivel pipeline template.
Frequently Asked Questions
Name some of the built-in algorithms available for training on AI Platform Training.
Built-in algorithms help train models for various use cases that can be solved using classification and regression. Linear learner, Wide and deep, TabNet, XGBoost, Image classification, and Object detection are some of the built-in algorithms on AI Platform Training.
What are the different roles in a distributed Training structure?
The master role manages the other roles and reports the status of the job as a whole. Workers are one or more replicas that do their portion of the work as specified in the job configuration. Parameter servers coordinate the shared model state between the workers.
How does ML training work in a container?
A container runs its training on samples and outputs its results back to storage. The container saves the checkpoints of its ML model to an outside data source and not on the container so that new instances of the container can pick up from where they left off.
Conclusion
I hope this article gave you insights into the vertex AI matching engine supported by Google.
We hope this blog has helped you increase your knowledge regarding AWS Step functions, and if you liked this blog, check other links. Do upvote our blog to help other ninjas grow. Happy Coding!
































 9+ registered
9+ registered 

