Do you think IIT Guwahati certified course can help you in your career?
Introduction
Deep learning has demonstrated great success in various computer vision applications. Convolutional neural networks are the state of the art deep learning models used for image recognition and classification. It has made many computer vision tasks such as driverless cars a possibility. Different methods are continuously developed to improve the accuracy of deep learning models. VGG16 is a CNN that shows great accuracy and won the ILSVR 2014.
VGG16 is a CNN (Convolutional Neural Network) architecture that is widely considered to be one of the best computer vision models available today. The designers of this model examined the networks and improved the depth using a compact (3 × 3) convolution filter architecture that substantially exceeded previous-art settings. The 16 in VGG16 refers to that it has 16 layers that have weight. It is a very large network with 138 million parameters.
VGG-16 Architecture
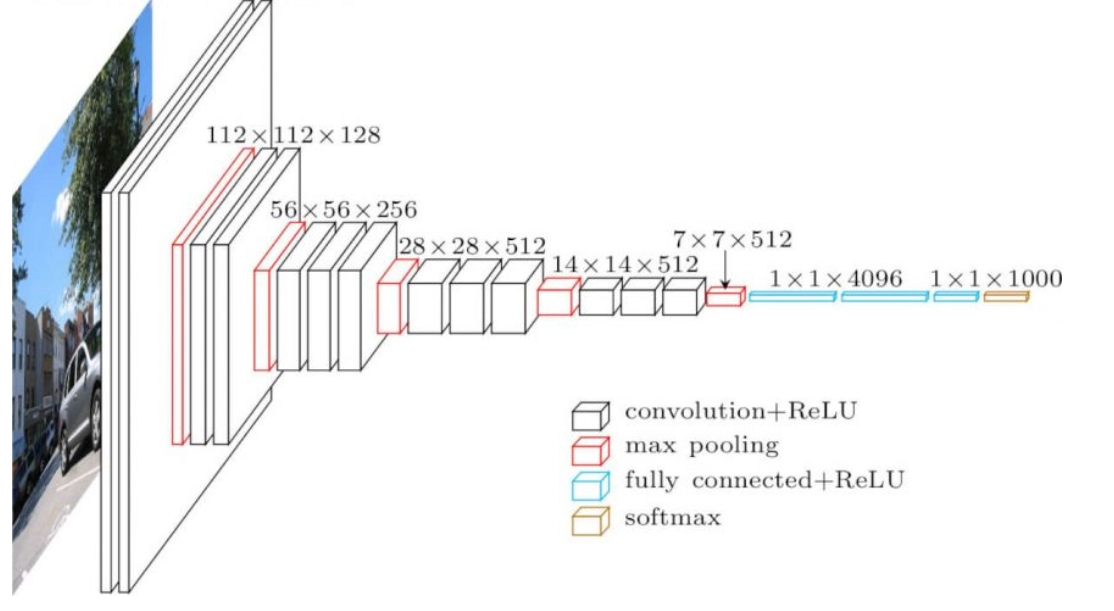
VGG-16 is a type of VGG Net. The input to VGG-16 is a fixed size 244X244 RGB image. Each pixel in a picture is deducted from its mean RGB value in a pre-processing phase.
The pictures are then fed through a stack of convolutional layers with tiny receptive-field filters of size (33) once the pre-processing is completed. The filter size is set to (1 1) in a few setups, indicating that the input channels have been transformed linearly (followed by non-linearity).
The convolution operation's stride is set at 1 by default. Five max-pooling layers, which come after numerous convolutional layers, are used to do spatial pooling.
The max-pooling is done with a (2 2) pixel window and a stride size of 2.The setup for fully-connected layers is always the same: the first two layers each have 4096 channels, the third layer conducts 1000-way ILSVRC classification (and so has 1000 channels, one for each class), and the softmax layer is the last layer. The ReLu activation function is used to activate all of the VGG network's hidden layers.
from keras.applications.vgg16 import decode_predictions
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
import matplotlib.pyplot as plt
from PIL import Image
import seaborn as sns
import pandas as pd
import numpy as np
import os
You can also try this code with Online Python Compiler
def _get_predictions(_model):
f, ax = plt.subplots(1, 4)
f.set_size_inches(80, 40)
for i in range(4):
ax[i].imshow(Image.open(imgs[i]).resize((200, 200), Image.ANTIALIAS))
plt.show()
f, axes = plt.subplots(1, 4)
f.set_size_inches(80, 20)
for i,img_path in enumerate(imgs):
img = _load_image(img_path)
preds = decode_predictions(_model.predict(img), top=3)[0]
b = sns.barplot(y=[c[1] for c in preds], x=[c[2] for c in preds], color="gray", ax=axes[i])
b.tick_params(labelsize=55)
f.tight_layout()
You can also try this code with Online Python Compiler
If you extract the features from the two last layers or from the last layer, the computations of the features map will be different, and this will have an impact if you apply it in another model.
Why does vgg16 require fewer epochs than ResNet?
VGG is said to be more suited for cifar10 for some reason (due to kernel sizes etc.).
What is transfer learning?
Transfer learning is a machine learning research subject that focuses on storing and transferring information learned while addressing one problem to a different but related problem.
Conclusion
VGG is a cutting-edge object-recognition model with up to 19 layers. VGG, which was built as a deep CNN, outperforms baselines on a variety of tasks and datasets outside of ImageNet. VGG is one of the most widely used image-recognition models today.If you don't have a lot of data, you can use Transfer Learning instead of starting from scratch.

































 9+ registered
9+ registered 

