



























Introduction
A Big Data management approach involves measuring, analyzing, managing, and governing such large quantities of data. Managing structured and unstructured data is part of the process. In addition to ensuring data quality, a primary objective is to make the data available for Business Intelligence and big data analytics applications. Many government agencies, corporations, and other enterprises are implementing Big Data management solutions to cope with the rapidly growing data pools. This data includes several terabytes or even petabytes of information, which is saved in a variety of file formats. An organization can effectively manage Big Data by finding valuable information, regardless of how large or unstructured it is.
Since the dawn of the digital age, both data volumes and processing speeds have grown exponentially, but the former has grown at a much faster rate than the latter. To bridge the gap, new techniques are necessary.
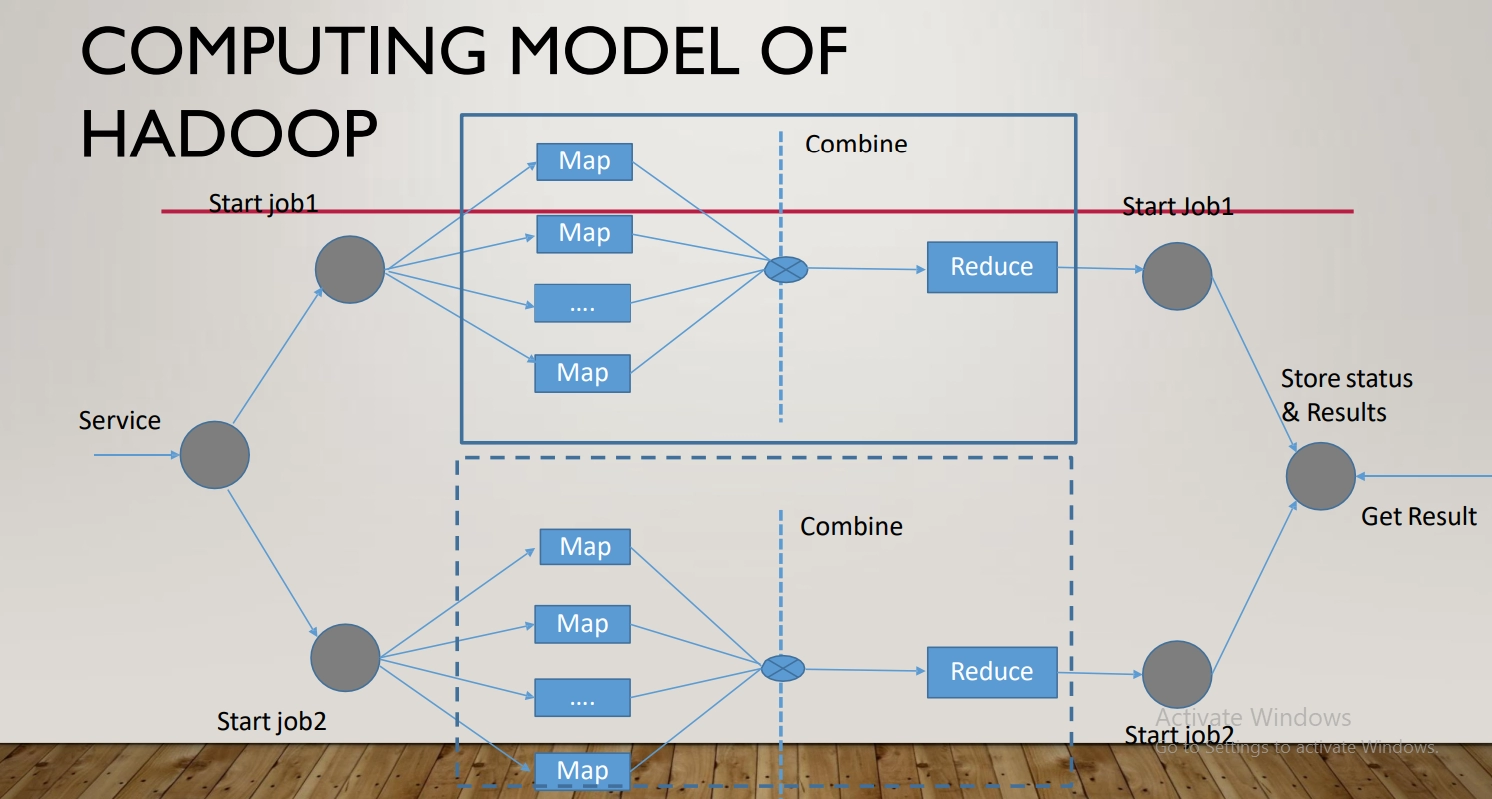
When it comes to handling, processing, and analyzing big data, the most successful and effective technology innovations have been distributed and parallel processing, Hadoop, in-memory computing, and big data clouds. Most popular is Hadoop. It enables organizations to rapidly extract the most information from data usage. Organizations can save money and manage resources better with cloud computing.
Distributed and Parallel Computing for Big Data
A system of traditional data management and storage cannot cope with big data. Distributed and Parallel Technologies are better suited to handle this type of data.
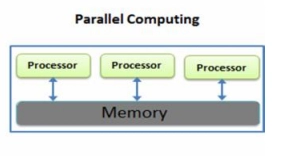
Distributed Computing: The network consists of various computing resources that distribute tasks among them. In this network, computing resources each have their own memory. It increases the speed and the efficiency and is more suitable for processing large amounts of data in a short time.
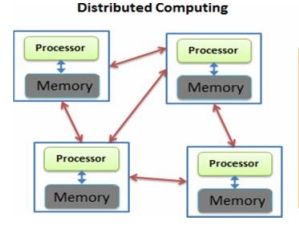
Parallel Computing: By adding computational resources to a computer system, it also improves its processing capability. Compose complex computation into smaller subtasks; each dealt with by a separate processing unit. Increased parallelism will result in increased processing speed. In this, they share a common memory.
Due to the increasing quantity of data, organizations must adopt data analysis strategies that can analyze the entire data in a short amount of time. These strategies are realized through new software and powerful hardware components.
The procedure followed by the software applications are:
- Break up the given task
- Surveying the available resources
- Assigning subtasks to the nodes
Issues in the system:
- A technical problem prevents resources from responding.
- Virtualization: Using virtualization, users can share system resources effortlessly while ensuring privacy and security by isolating and protecting them from one another.
Merits of the system
Scalability: Thanks to added scalability, the new system can accommodate increasing volumes of data more effectively and flexibly. We can easily add more computing units in parallel computing.
Load Balancing – The sharing of workload across various systems.
Virtualization: Using virtualization, users can share system resources effortlessly while ensuring privacy and security by isolating and protecting them from one another.
Parallel Computing Techniques
1) Cluster or Grid Computing
This is mainly used in Hadoop. Based on the use of multiple servers in a network (clusters), the service can handle large amounts of data. The workload is distributed among the servers. Generally, the cost is high.
2) Massively Parallel Processing (MPP)
It is used in data warehouses. The MPP platform is based on a single machine that functions as a grid. Designed to handle all storage, memory, and processing needs. Software coded specifically for the MPP platform is used for optimization.
3) High-Performance Computing (HPC)
It can be used to process floating-point data at high computing speeds. Research and business organizations use this approach when the result is more valuable than the cost or when the strategic importance of the project is of critical importance.
Difference between Distributed and Parallel Systems
| Distributed System | Parallel System |
| An autonomous system is connected via a network to complete a particular task. | Multiple processing units are attached to a computer system. |
| There is a possibility of coordination between connected computers with their own memory and CPU. | The shared memory in a network can be accessed by all the processing units at once. |
| A loosely coupled network of computers that provide remote access to data and resources. |
Tight coupling of processing resources that are used for solving a single, complex problem.
|


 9+ registered
9+ registered 

