Do you think IIT Guwahati certified course can help you in your career?
Introduction
Disjoint sets in mathematics are two sets that don't have any element in common. Sets can contain any number of elements, and those elements can be of any type. We can have a set of cars, a set of integers, a set of colors, etc. Sets also have various operations that can be performed on them, such as union, intersection, difference, etc.
In computer science and DAA, we focus on Disjoint Set Data Structure and the operations we can perform. In this article, we will go through what a disjoint set data structure is, the disjoint set operations in daa, as well as an example application of it.
Disjoint Set Data Structure
Before we look at disjoint set operations in daa, let us understand what the disjoint set data structure itself is.
A disjoint set data structure is a data structure that stores a list of disjoint sets. In other words, this data structure divides a set into multiple subsets - such that no 2 subsets contain any common element. They are also called union-find data structures or merge-find sets.
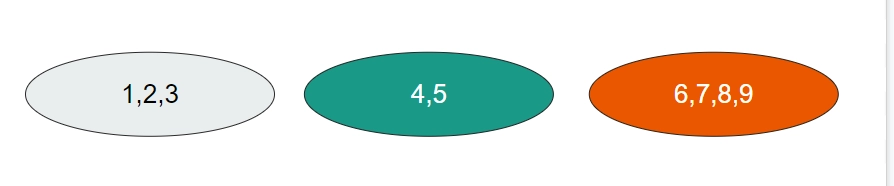
For example: if the initial set is [1,2,3,4,5,6,7,8].
A Disjoint Set Data Structure might partition it as - [(1,2,4), (3,5), (6,8),(7)].
This contains all of the elements of the original set, and no 2 subsets have any element in common.
The following partitions would be invalid:
[(1,2,3),(3,4,5),(6,8),(7)] - invalid because 3 occurs in 2 subsets.
[(1,2,3),(5,6),(7,8)] -invalid as 4 is missing.
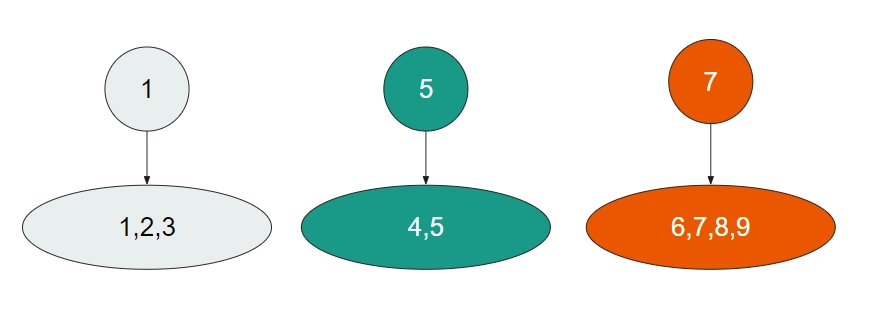
Representative Member
Each subset in a Disjoint Set Data Structure has a representative member. More commonly, we call this the parent. This is simply the member responsible for identifyingthe subset.
Let's understand this with an example.
Suppose this is the partitioning of sets in our Disjoint Set Data structure.
We wish to identify each subset, so we assign each subset a value by which we can identify it. The easiest way to do this is to choose a member of the subset and make it the representative member. This representative member will become the parent of all values in the subset.
Here, we have assigned representative members to each subset. Thus, if we wish to know which subset 3 is a part of, we can simply say - 3 is a part of the subset with representative member 1. More simply, we can say that the parent of 3 is 1.
Union/Merge - this is used to merge 2 subsets into a single subset.
Find - This is used to find which subset a particular value belongs to.
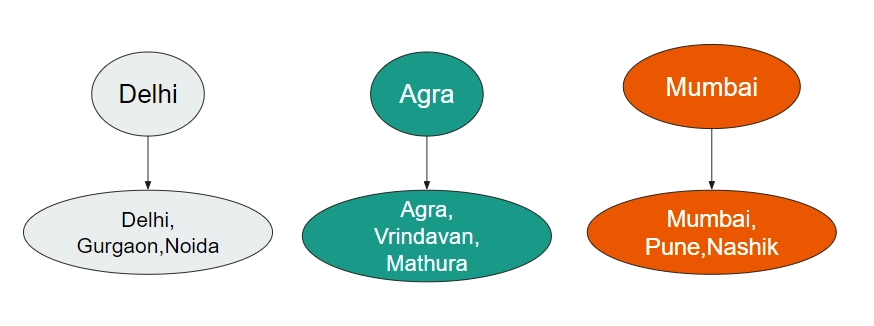
We will take a look at both of them. To make things easier, we will change our sets from integers to Cities.
Let's say this Data Structure represents the places connected via express trains/ metro lines or any other means.
Union/Merge
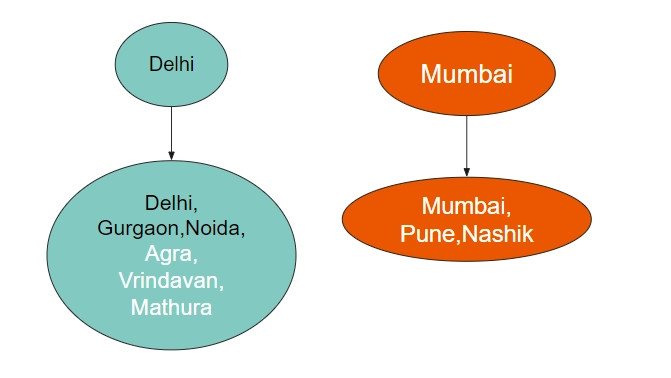
Suppose, in our example - a new express train started from Delhi to Agra. This would mean that allthe cities connected to Delhi are now connected to all the cities connected to Agra.
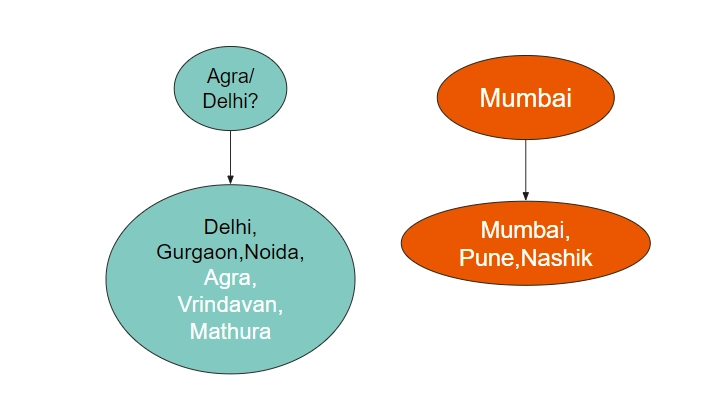
This simply means that we can mergethe subsets of Agra and Delhi into a single subset. It will look like this.
One key issue here is which out of Agra and Delhi will be the new Parent? For now, we will just choose any of them, as it will be sufficient for our purposes. Let's take Delhi for now.
Further optimizations can be made to this by choosing the parent based on which subset has a larger number of values.
This is the new state of our Disjoint Set Data Structure. Delhi is the parent of Delhi, Gurgaon, Noida, Agra, Vrindavan, and Mathura.
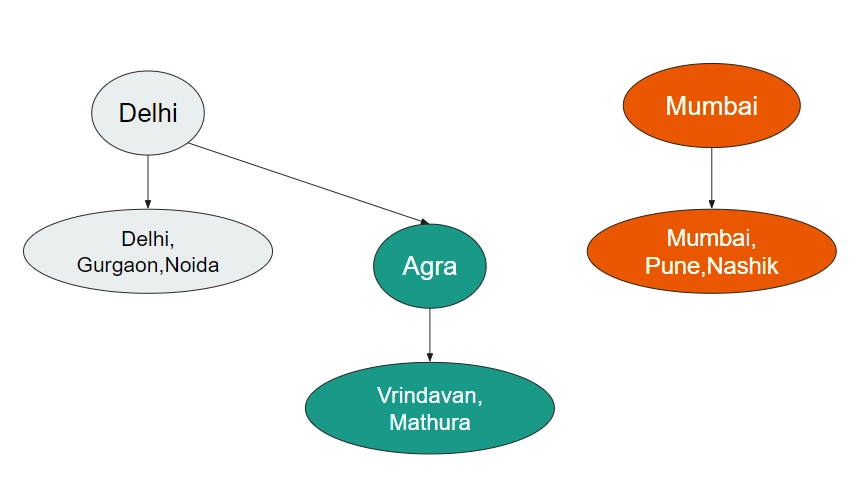
This would mean that we would have to change the parent of Agra, Vrindavan, and Mathura (basically, all the children of Agra), to Delhi. This would be linear in time. If we perform the union operation m times, and each union takes O(n) times, we would get a quadratic O(mn) time complexity. This is not optimized enough.
Instead, we structure it like this:
Earlier, Agra was its own parent. Now, Delhi is the parent of Agra.
Now, you might be wondering - The parent of Vrindavan is still Agra. It should have been Delhi now.
This is where the next operation helps us - the find operation.
Find
The find operation helps us find the parent of a node. As we saw above, the direct parent of a node might not be its actual (logical) parent. E.g., the logical parent of Vrindavan should be Delhi in the above example. But its direct parent is Agra.
So, how do we find the actual parent?
The find operation helps us to find the actual parent. In pseudocode, the find operation looks like this:
find(node):
if (parent(node)==node) return node;
else return find(parent(node));
We don't return the direct parent of the node. We keep going up the tree of parents until we find a node that is its own parent.
Let's understand this via our example.
Suppose we have to find the parent of Mathura.
Check the direct parent of Mathura. It's Agra. Is Agra == Mathura? The answer is false. So, now we call the find operation on Agra.
Check the direct parent of Agra. It's Delhi. Is Delhi ==Agra? The answer is false. So now we call the find operation on Delhi.
Check the direct parent of Delhi. It's Delhi. Is Delhi==Delhi. The answer is true! So, our final answer for the parent of Mathura is Delhi.
This way, we keep going "up" the tree until we reach a root element. A root element is a node with its own parent - in our case, Delhi.
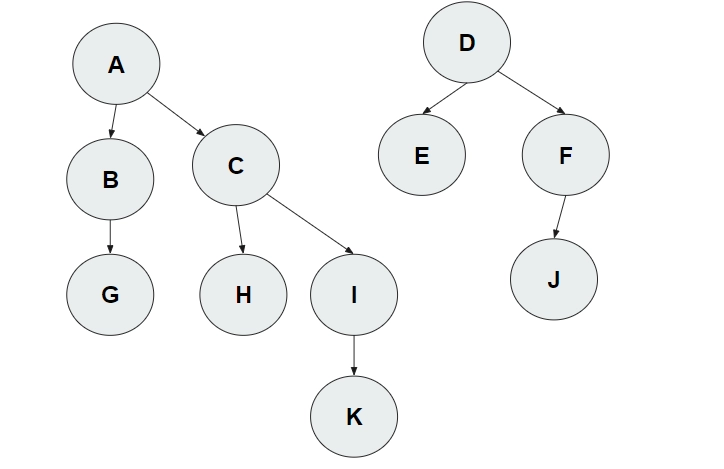
Let's try to find the parent of K in this example. (A and D are their own parents)
ParentOf(K) is I. Is I == K? False. So, we move upward, now using I.
ParentOf(I) is C. Is C== I? False. Move upward using C.
ParentOf(C) is A. Is A==C? False. Move upward using A.
ParentOf(A) is A. Is A==A? True! Our final answer is A.
Let's understand the use of a Disjoint Set Data Structure through a simple application - Finding a cycle in an undirected graph.
Find a Cycle in an Undirected Graph using Disjoint Set Data Structure
Let us understand the disjoint set operations in daa more clearly with the help of an example. Here, wewill use a disjoint set data structure to find whether an undirected graph contains a cycle or not. We are assuming that our graph does not contain any self-loops.
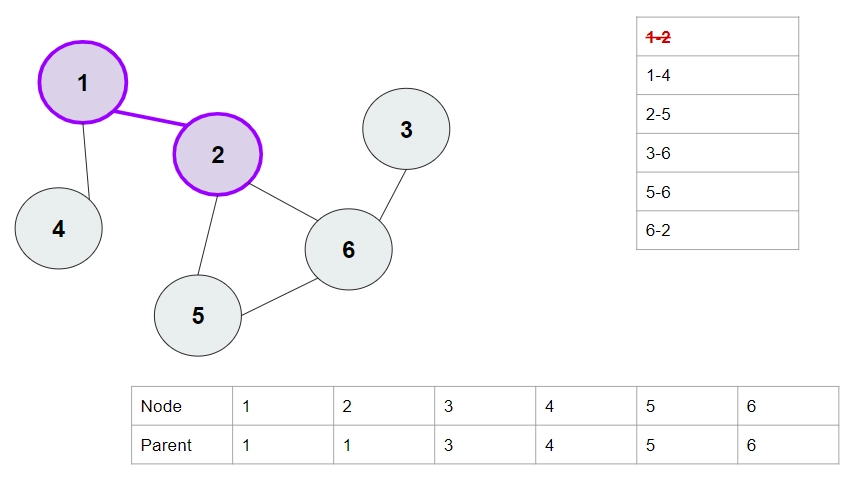
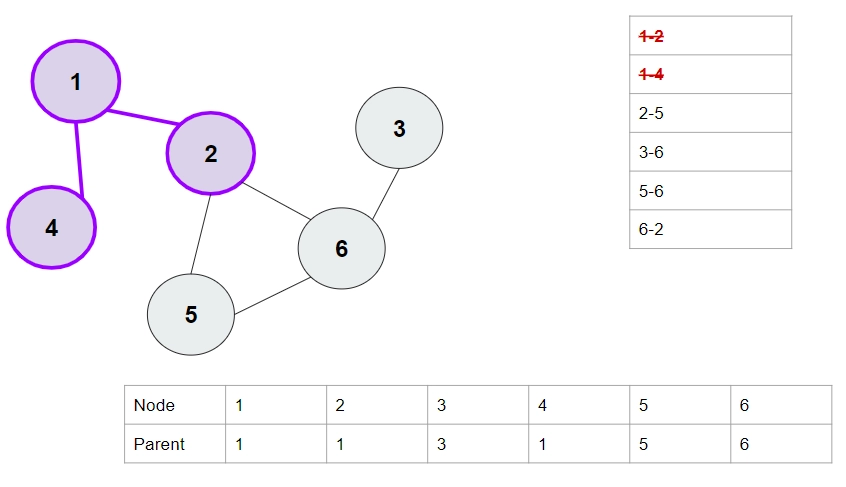
Let this be our graph. Each node is initialized as its own parent. The list of edges is shown on the top right, and the parents are shown at the bottom. We have shown each edge only once for simplicity (i.e., 1-2 and 2-1 aren't shown separately)
Algorithm
We will go through each edge and do the following. Let the edge be u-v.
Find the parent of u and v. If both parents are the same, it means u and v are part of the same subset, and we have found a cycle.v
If they are not the same, merge u and v. We don't merge u and v directly. Instead, we merge the parents of u and v. This ensures that all the siblings of u and all the siblings of v have the same common parent.
We do this for all edges.
Walkthrough
1. 1-2 Edge.
Parent of 1 is 1, parent of 2 is 2. They are different, so we will merge them. Set the parent of 2 as 1 (this is chosen randomly, setting the parent of 1 as 2 would also have been correct ).
2. 1-4 Edge. Parent of 1 is 1. Parent of 4 is 4. They are not the same, so merge 1 and 4. Set parent of 4 as 1.
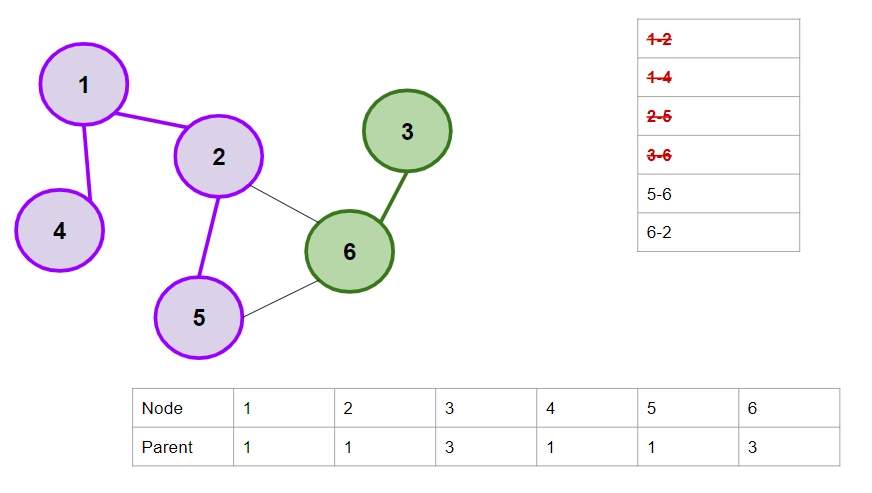
3. 2-5 Edge. The parent of 2 is 1, and the parent of 5 is 5. They aren't the same, so we'll merge them. Set the parent of 5 as 1.
4. 3-6 Edge. The parent of 3 is 3, and the parent of 6 is 6. They aren't the same, so we'll merge them. Set the parent of 6 as 3.
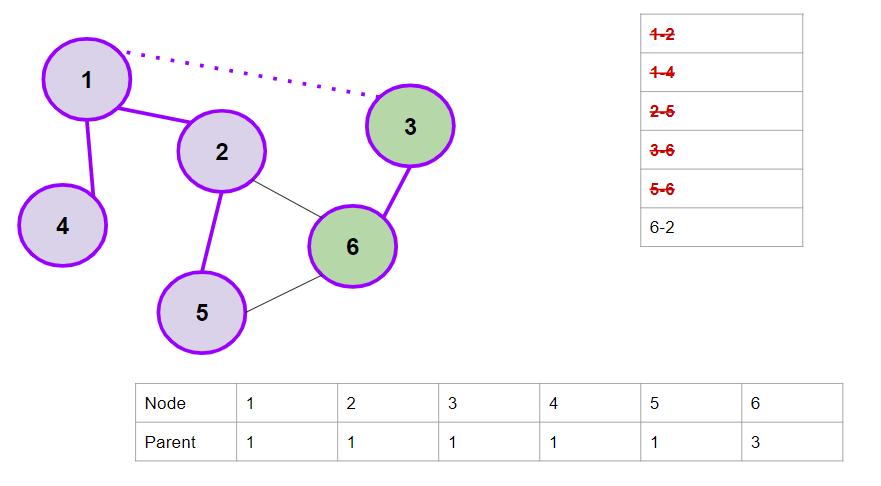
5. 5-6 Edge. The parent of 5 is 1, and the parent of 6 is 3. They aren't the same, so we'll merge them. Set the parent of 3 as 1.
Note here - the direct parent of 6 is still 3. But, the actual parent becomes 1, because the parent of 3 is 1. (The dotted line is not an edge in the graph, it shows that the parent of 3 is 1)
6. 6-2 Edge. The parent of 6 is 1 (actual parent), and the parent of 2 is also 1. These are both the same. Thus, our graph contains a cycle.
Code in C++
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
// An edge in the graph
struct Edge {
// the endpoints of the edge
int u, v;
// constructor for Edge
Edge(int u, int v) : u(u), v(v) {}
};
// This class represents a graph using edge list representation
class Graph {
public:
int V; // no of vertices in the graph
vector<Edge> edges; // list of edges in the graph
Graph(int v) { // constructor
V = v;
}
// adds an edge (u,v) to the graph
void addEdge(int u, int v) { edges.push_back(Edge(u, v)); }
};
// A disjoint set data structure that supports merge and find operations
class DisjointSet {
//The array that stores the parents of each node
vector<int> parent;
public:
//the number of nodes
int V;
// constructor
DisjointSet(int V) : V(V) {
//initialise with V+1 values so our nodes can be 1-indexed
parent = vector<int>(V + 1);
for (int i = 1; i <= V; i++) {
parent[i] = i;
}
}
//find operation of Disjoint Set Data Structure
int find(int u) {
if (u == parent[u])
return u;
return find(parent[u]);
}
//merge or union operation of Disjoint Set Data Structure
void merge(int u, int v) {
int parentU = find(u);
int parentV = find(v);
if (parentU != parentV) {
parent[parentU] = parentV;
}
}
};
// function to detect whether cycle exists in graph, using Disjoint Set Data Structure
void cycleExists(Graph g) {
DisjointSet ds(g.V);
for (Edge e : g.edges) {
int u = e.u;
int v = e.v;
if (ds.find(u) == ds.find(v)) {
cout << "Cycle exists between " << u << " and " << v << endl;
return;
}
ds.merge(u, v);
}
cout << "No cycle exists" << endl;
}
//main driver function
int main() {
Graph g(6);
g.addEdge(1, 2);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(3, 6);
g.addEdge(5, 6);
g.addEdge(6, 2);
cycleExists(g);
return 0;
}
You can also try this code with Online C++ Compiler
Regardless of the example or the purpose in which they are used, disjoint set operations in daa always have the same space and time complexities. The complexities for both find and union operations are:
The space complexity is O(n), where n is the number of vertices. The parent array stores the parent of each vertex. Hence we get O(n) space complexity. We aren't considering the space complexity of the graph in this because the graph is the input here.
The time complexity is O(log N) in the average case because the find operation will have to go up a tree with n nodes. The height of a tree in the average case will be log N. In the worst case, we can have a skewed tree, and our time complexity will become O(n). Check out this problem - Largest BST In Binary Tree
Frequently Asked Questions
Is there a way to decrease the time complexity of the disjoint set operations in daa?
Yes, we can perform union by path-compression and rank operations to reduce the time complexity. With this, we don't change how the tree is traversed - but we make sure the skew case can never occur.
Are disjoint set operations in daa used practically?
Disjoint set operations are optimal and efficient in practical uses. They have a lot of uses in real-life applications - e.g., finding connected components, Kruskal's algorithm, etc.
Why do we merge the parents instead of the actual nodes in the merge operation for a disjoint set?
We merge parents instead of nodes so that all the children of both parents come under a single parent. E.g., let's say we need to merge B and Y. A is the parent of B, and X is the parent of Y. Another node C, also has its parent as A. And another node, Z, also has its parent as Y. If we merge B and Y directly by setting the parent of B as Y - then we will disconnect B from A and from C. However, if we merge A and X, by setting the parent of X as A, then all the nodes (A, B, C, X, Y, Z) will have a single parent A. This is what we want.
Conclusion
In this article, we have discussed the disjoint sets, disjoint set operations in daa, methods to detect a cycle in a graph, and implementation using union-find method in detail.
After reading about how to find the Closest element to a target value in Binary Search Tree, are you not feeling excited to read/explore more articles on the topic of BST? Don't worry; Coding Ninjas has you covered. If you want to practice questions on the binary tree then follow these links: disjoint set data-structure, Check if two sets are disjoint, union-find algorithm.


































 9+ registered
9+ registered 

