Do you think IIT Guwahati certified course can help you in your career?
Introduction
Machine learning is a field of Artificial Intelligence that involves developing algorithms and models that enable computers to learn and improve their performance from data. Machine learning aims to allow computers to identify patterns and insights in data and then use these insights to make predictions or decisions about new, unseen data. Machine learning algorithms are used in various applications, including image and speech recognition, natural language processing, recommendation systems, fraud detection, and autonomous vehicles.
What is Machine Learning?
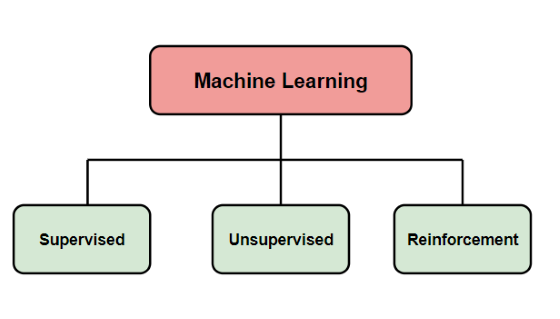
Machine Learning is a subfield of Artificial Intelligence (AI) that involves the development of algorithms and statistical models that allow computers to learn from data and improve their performance on specific tasks without being explicitly programmed.Machine Learning algorithms can be broadly categorized into supervised, unsupervised, and reinforcement learning. Machine learning has a wide range of applications in various fields, including image and speech recognition, natural language processing, autonomous vehicles, recommender systems, fraud detection, and many others. In simple words, we can say that Machine Learning teaches computers so that making decisions based on inputs and patterns becomes easy.
History of Machine Learning
Machine Learning has come a long way since computers were first invented. Each milestone added to the field's progress, from the first neural network with electric circuits in 1943 to Alan Turing's Turing Test in 1950 and Arthur Samuel's computer checkers in 1952. Frank Rosenblatt's perceptron, the nearest neighbor algorithm, and the advent of backpropagation in the 1960s and 1970s further refined Machine Learning techniques. The late 20th century saw achievements like the Stanford Cart's autonomous navigation and IBM's Deep Blue defeating a chess grandmaster in 1997. In the 2000s, tools like the Torch software library were introduced and marked the beginning of deep learning. In 2011, the formation of Google Brain, the facial recognition success of DeepFace in 2014, and the significant improvements in computer vision accuracy achieved by the ImageNet Challenge in 2017 all showcased the remarkable evolution of Machine Learning, significantly influencing both technology and human life.
How Does Machine Learning Work?
Let us see the steps in Machine Learning in detail:
Data collection and preparation: The first stage involves identifying and collecting the data needed for the ML project. This data is then pre-processed and cleaned to remove irrelevant or incomplete information.
Data exploration and analysis: In this stage, the data is analyzed to gain insights and identify patterns. This involves data visualization, statistical analysis, and Exploratory Data Analysis (EDA).
Model selection and training: Once the data has been analyzed, the next step is to select an appropriate ML algorithm and train it on the data. This involves splitting the data into training and testing sets and tuning the model to optimize performance.
Model evaluation and validation: In this stage, the performance of the trained model is evaluated using various metrics and validated on new data to ensure that it generalizes well.
Deployment and monitoring: Once the model has been assessed and validated, it is deployed in a production environment. It is then monitored to ensure that it continues to perform well and to identify any issues that need to be addressed.
Model maintenance and retraining: As new data becomes available, the ML model may need to be updated or retrained to maintain its performance.
So far, we have understood that machine learning is used to make computers learn from previous knowledge and improve their efficiency. The most common features of machine learning are:
Learning from experience: Machine Learning algorithms learn from data by identifying patterns, relationships, and trends in the data.
Adaptability: Machine Learning algorithms can adapt to new data and changing environments, allowing them to improve their performance over time.
Generalization: Machine Learning models can generalize from the training data to new, unseen data, making them useful for various applications.
Automated decision making: Machine Learning algorithms can make decisions based on data without human intervention, making them useful for tasks such as image recognition, speech recognition, and natural language processing.
Scalability: Machine Learning algorithms can process large amounts of data quickly and efficiently, making them suitable for big data applications.
Modeling: Machine Learning algorithms can be used for predictive modeling, enabling businesses and organizations to make informed decisions based on data-driven insights.
Methods of Machine Learning
1. Supervised Machine Learning
Supervised learning is a type of machine learning where the model learns to make predictions based on labeled examples. In supervised learning, the input data is labeled with the correct output, and the goal of the model is to learn the relationship between the input data and the output label.
The input data, also known as the feature or predictor variable, is a set of features that describe the input or the input instance. The output label, also known as the response variable, is the value or class that the model needs to predict. The labeled examples are typically divided into two sets: a training set and a test set.
Linear Regression
Linear regression is a subcategory of Supervised Machine Learning. It is used to predict the dependent variable based on one or more input variables (also known as independent variables or features). It assumes a linear relationship between the input and output variables.
In simple linear regression, there is only one input variable, and the output variable is predicted as a linear function of that input variable. The goal of linear regression is to find the best-fit line that minimizes the difference between the predicted output and the actual output.
In multiple linear regression, there are multiple input variables, and the output variable is predicted as a linear function of all of the input variables. The goal of multiple linear regression is to find the best-fit hyperplane that minimizes the difference between the predicted output and the actual output.
Apart from all the features of linear regression, there are many drawbacks of it. A few of them are as follows.
Linearity assumption: Linear regression assumes that the relationship between the dependent and independent variables is linear. If this assumption is not met, then the model may provide poor predictions.
Outliers: Linear regression is sensitive to outliers in the data, which can have a significant impact on the model's performance.
Overfitting: Linear regression can be prone to overfitting when the model is too complex and has too many input variables, which can result in poor generalization of new data.
Underfitting: Linear regression can also suffer from underfitting when the model is too simple and does not capture the complex relationship between the input and output variables.
Logistic Regression
Logistic regression is a popular supervised learning algorithm in machine learning that is used to predict the probability of a binary or categorical outcome, known as the dependent variable, based on one or more input variables.
Unlike linear regression, logistic regression predicts the probability of an outcome being in one of two classes (e.g., true/false, yes/no, 0/1, etc.). The output of a logistic regression model is a probability score between 0 and 1, which is then converted into a binary prediction using a decision threshold.
Logistic regression uses a logistic function (also known as the sigmoid function) to model the relationship between the input variables and the probability of the outcome being in one of the classes. The logistic function maps any input value to a value between 0 and 1, which can be interpreted as the probability of the outcome being in a positive class.
However, logistic regression also has some limitations, including:
Assumes a linear relationship between the input variables and the log odds of the outcome, which may not always be the case.
Sensitive to outliers and may not perform well when the data is imbalanced.
May not perform well when the input variables are highly correlated or when there are interactions between them.
Limited to predicting binary or categorical outcomes and cannot be used for continuous outcomes.
Decision Trees
Another category of supervised learning is Decision Trees. They are used for both classification and regression tasks. A decision tree is a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility.
The basic idea behind a decision tree is to split the data into subsets based on the values of the input variables in a way that minimizes the impurity or entropy of each subset. The splitting process is repeated recursively until all the subsets belong to the same class or have similar values for the output variable.
In a classification decision tree, the goal is to predict the class label of a sample based on its input variables. Each internal node of the tree represents a test on an input variable, and each branch represents one of the possible outcomes of that test. Each leaf node represents a class label.
However, decision trees have some limitations, including:
Overfitting: Decision trees are prone to overfitting when the tree is too complex and has too many splits. Techniques such as pruning can be used to prevent overfitting.
Instability: Decision trees can be unstable, meaning that small variations in the data can lead to different trees being generated. Techniques such as random forests can be used to address this problem.
Bias: Decision trees can be biased towards features that have more levels or values, which can lead to suboptimal splits. Techniques such as information gain ratio can be used to address this problem.
Limited to axis-parallel splits: Decision trees are limited to making splits that are perpendicular to one of the input axes, which can limit their ability to capture complex relationships in the data. Techniques such as ensemble methods or neural networks can be used to address this problem.
Random Forest
Random forest is a supervised learning algorithm in machine learning that combines multiple decision trees to improve the accuracy and stability of the predictions. A random forest is essentially a collection of decision trees, where each tree is trained on a random subset of the input data and a random subset of the input variables.
The basic idea behind random forest is to create a set of decision trees using bootstrap aggregating and random feature selection. Each tree is trained on a random subset of the input data and a random subset of the input variables. During the prediction phase, the output of each tree is combined to produce a final prediction.
However, the random forest also has some limitations, including:
Overfitting: Random forest can overfit the data if the trees are too deep and there are too many features.
Complexity: Random forest can be computationally expensive and may require more resources compared to other algorithms.
Interpretability: Random forest can be difficult to interpret, especially when the number of trees is large.
Bias: Random forest can be biased towards features that have more levels or values, which can lead to suboptimal splits. Techniques such as information gain ratio can be used to address this problem.
Support Vector Machines
Support Vector Machines are one of the popular supervised learning algorithms in machine learning that are used for classification, regression and outlier detection tasks. SVMs aim to find a hyperplane that separates two classes of data points in a high-dimensional space. In cases where a linear separation is not possible, SVMs use kernel functions to transform the input data into a higher-dimensional space where linear separation is possible.
The basic idea behind SVMs is to find a hyperplane that maximizes the margin between the two classes of data points. The margin is defined as the distance between the hyperplane and the nearest data points from each class. SVMs aim to find the hyperplane that maximizes the margin while also ensuring that the hyperplane correctly separates the two classes.
However, SVMs have some limitations, including:
Computationally expensive: SVMs can be computationally expensive for large datasets, especially when using nonlinear kernel functions.
Sensitivity to kernel choice: The performance of SVMs is sensitive to the choice of kernel function and the choice of hyperparameters.
Interpretability: SVMs can be difficult to interpret, especially when using nonlinear kernel functions.
Neural Networks
Neural Networks are popular Machine Learning algorithms that are modeled after the structure and function of the human brain. Neural Networks consist of a large number of interconnected nodes or neurons, which are organized into layers. Each neuron is responsible for processing a subset of the input data and passing its output to the next layer of neurons.
The basic idea behind Neural Networks is to use a set of training data to learn a set of weights or parameters that allow the network to map input data to output data. During the training phase, the network adjusts its weights to minimize the difference between its predicted output and the actual output. This is achieved using a backpropagation algorithm that calculates the gradient of the loss function with respect to the network weights.
However, Neural Networks also has some limitations, including:
Computationally expensive: Neural Networks can be computationally expensive, especially for large datasets and complex network architectures.
Overfitting: Neural Networks are prone to overfitting the training data if the model is too complex or the number of training samples is too small.
Black box: Neural Networks can be difficult to interpret, making it hard to understand how the model arrived at its predictions.
Hyperparameter tuning: Neural Networks have many hyperparameters that need to be tuned, such as the number of layers, the number of neurons in each layer, and the learning rate.
2. Unsupervised Machine Learning
K-means Clustering
K-means clustering is an unsupervised learning algorithm in machine learning that is used to cluster data points into K clusters based on their similarity. The algorithm works by iteratively assigning data points to the closest cluster centroid and recalculating the centroid of each cluster based on the new data point assignments.
The basic idea behind K-means clustering is to partition the data into K clusters such that the within-cluster sum of squares is minimized. The within-cluster sum of squares is the sum of the squared distances between each data point and its assigned cluster centroid. K-means clustering aims to find the optimal set of K-cluster centroids that minimizes the within-cluster sum of squares.
However, K-means clustering also has some limitations, including:
Initialization sensitivity: K-means clustering is sensitive to the initial placement of the cluster centroids, which can lead to different results for different initializations.
Determining the optimal number of clusters: The number of clusters, K, must be determined a priori, which can be difficult in practice.
Handling non-spherical clusters: K-means clustering is not well-suited for handling non-spherical clusters or clusters with irregular shapes.
Outlier sensitivity: K-means clustering is sensitive to outliers in the input data.
Hierarchical Clustering
Hierarchical clustering is another popular unsupervised learning algorithm in machine learning that is used to cluster data points into groups based on their similarity. The algorithm works by iteratively merging or splitting clusters based on their distance or similarity.
The basic idea behind hierarchical clustering is to build a tree-like structure, called a dendrogram, that represents the hierarchical relationships between the data points. The dendrogram starts with each data point as a separate cluster and iteratively merges or splits clusters until a stopping criterion is met.
There are two main types of hierarchical clustering: agglomerative and divisive. Agglomerative clustering starts with each data point as a separate cluster and iteratively merges the closest clusters until all data points belong to a single cluster. Divisive clustering starts with all data points in a single cluster and iteratively splits the cluster into smaller clusters until each data point is in a separate cluster.
However, hierarchical clustering also has some limitations, including:
Computationally expensive: Hierarchical clustering can be computationally expensive, especially for large datasets.
Initialization sensitivity: The starting point for hierarchical clustering can impact the final results.
Sensitivity to outliers: Hierarchical clustering is sensitive to outliers in the input data.
Principal Component Analysis
Principal Component Analysis (PCA) is a dimensionality reduction technique in machine learning that is used to transform high-dimensional data into a lower-dimensional space while retaining as much of the variance in the data as possible. PCA works by finding the principal components of the data, which are linear combinations of the original features that capture the maximum amount of variance in the data. The basic idea behind PCA is to project the data onto a new set of axes that are aligned with the principal components of the data. However, PCA also has some limitations, including:
Data scaling: PCA is sensitive to the scaling of the input data and requires that the data be standardized before applying PCA.
Information loss: PCA can result in some information loss due to the reduction in dimensionality.
Interpretability: The principal components produced by PCA may be difficult to interpret in some cases.
3. Semi Supervised Machine Learning
Semi-supervised machine learning is another type of machine learning that trains on a combination of both labeled and unlabeled data for training a model. As discussed earlier in supervised learning, the algorithm is trained on a labeled dataset where each data point is associated with a known target variable. In unsupervised learning, the algorithm is trained on an unlabeled dataset to discover patterns and structure in the data.
In semi-supervised learning, a smaller labeled dataset is combined with a larger unlabeled dataset to improve the model's performance. The idea is that the labeled data provides a starting point for the model to learn from, while the unlabeled data provides additional information to help the model generalize better to new data.
Semi-supervised learning can be helpful in scenarios where labeling data is expensive, time-consuming, or not feasible, but a large amount of unlabeled data is available. For example, labeling a few examples of each class in image recognition tasks may be more straightforward. Still, there may be a large number of unlabeled images available that can be used to improve the model's performance.
Some standard techniques used in semi-supervised learning include:
Self-training: The labeled data is used to train an initial model, then to label the unlabeled data. The newly labeled data is then added to the labeled dataset, and the model is retrained.
Co-training: Two or more different views of the data are used to train separate models, and the models are then used to label each other's data.
Transductive learning: The unlabeled data is used to make predictions on new data points, and the predictions are used to improve the model's performance on the labeled data.
Semi-supervised learning is a powerful technique for improving the performance of machine learning models when labeled data is limited. Still, it requires carefully considering the balance between labeled and unlabeled data and the appropriate combined techniques.
4. Reinforcement Machine Learning
Reinforcement learning is another type of machine learning that involves training agents to make decisions in a complex environment. The goal of reinforcement learning is to learn an optimal policy or sequence of actions that maximizes a reward signal, a scalar feedback signal indicating how well the agent is performing the task.
In Reinforcement Learning, the agent interacts with an environment, typically modeled as a Markov decision process (MDP). At each time step, the agent observes the state of the environment and selects an action to perform based on its current policy. The background then transitions to a new state and gives the agent a reward signal based on performance. The agent aims to learn an approach that maximizes the expected cumulative reward over time.
It involves a hit-and-trial approach, where the agent learns by exploring the environment and receiving feedback on its actions. The agent's policy is typically represented as a value function that estimates the expected cumulative reward for each state-action pair or as a policy function that maps states to actions directly.
Reinforcement Learning has been successfully applied to various problems, such as game playing, robotics, and resource management. However, it requires significant computational resources and may suffer from high variance and instability during training. Therefore, it requires careful design and tuning to achieve good performance.
Different Models in Machine Learning
The various models used in Machine Learning are:
Clustering: Clustering involves grouping data points into clusters or subgroups based on their similarity or distance from one another. The goal of clustering is to identify patterns in the data that are not immediately apparent or easily discernible. Clustering algorithms vary in their approach and complexity, but they all aim to identify clusters of data points that share some underlying structure or similarity. Some popular clustering algorithms include k-means clustering, hierarchical clustering, and density-based clustering.
Classification models: A classification model is trained to predict the class or category of a given input based on its features. The goal of a classification model is to learn a decision boundary that separates different classes in the input space.
Regression models: A regression model is used to predict a continuous numerical output based on one or more input variables or features. The goal of a regression model is to learn the relationship between the input variables and the output variable in order to make accurate predictions on new, unseen data.
Dimensionality Reduction model: Dimensionality reduction is a process that involves reducing the number of features or dimensions in a dataset while retaining as much relevant information as possible. The goal of dimensionality reduction is to simplify the input data and remove noise and redundancy, which can improve the performance and efficiency of machine learning models.
Difference Between Machine Learning, Artificial Intelligence, and Deep Learning
Artificial Intelligence (AI)
Artificial Intelligence (AI) is a broad branch of computer science that aims to build machines capable of performing tasks that normally require human intelligence. These tasks include reasoning, problem-solving, understanding language, and recognizing patterns. AI combines several disciplines like data analytics, statistics, hardware and software engineering, neuroscience, and even philosophy.
AI systems can be rule-based, meaning they follow a set of instructions, or they can adapt and learn from data. Technologies like speech recognition, image analysis, and robotics are common examples of AI in real life. Overall, AI focuses on automating intelligent behavior, creating systems that can mimic or even improve on human decision-making abilities.
Example: Voice assistants like Siri and Alexa are powered by AI because they understand and respond to human speech intelligently.
Machine Learning (ML)
Machine Learning (ML) is a subset of AI that enables machines to learn from data without being directly programmed for every task. Instead of following strict rules, ML algorithms identify patterns in data and make predictions or decisions based on them.
There are different types of ML techniques, such as supervised learning (where the model learns from labeled data), unsupervised learning (where the model identifies hidden patterns in data), and reinforcement learning (where models learn through trial and error). Popular algorithms include decision trees, neural networks, linear regression, and clustering.
In short, ML is the "learning" part of AI — it gives systems the ability to improve automatically through experience.
Example: Netflix's recommendation system uses machine learning to suggest movies and shows based on your viewing history.
Deep Learning (DL)
Deep Learning (DL) is a further specialization under machine learning. It uses artificial neural networks with many layers—sometimes hundreds or even thousands—to analyze and learn from data. Each layer processes the data and passes its output to the next layer, helping the system understand complex patterns.
Deep learning is powerful for tasks like image and speech recognition because it can handle massive amounts of unstructured data and improve its accuracy over time. The "deep" in deep learning refers to the depth (number of layers) in the neural network.
At the core of deep learning are artificial neurons that mimic how the human brain works. These neurons take input, apply weights, process through activation functions, and produce an output that helps in decision-making.
Example: Self-driving cars use deep learning to recognize objects like traffic lights, pedestrians, and other vehicles to navigate safely.
Tools in Machine Learning
There are many tools available for machine learning, each with its own strengths and weaknesses. Here are a few popular tools in the field:
PyTorch: PyTorch is a popular open-source machine learning library developed by Facebook. It offers dynamic computation graphs, making it easy to define and modify models on the fly. PyTorch is known for its flexibility, ease of use, and excellent support for deep learning.
Keras: Keras is another popular open-source machine learning library that offers a high-level interface for building neural networks. It supports both TensorFlow and Theano as backends and offers a user-friendly API for building models quickly.
TensorFlow: TensorFlow is an open-source machine learning library developed by Google. It offers a flexible architecture for building models, including support for distributed computing, and is widely used in both research and production settings.
Jupyter: Jupyter is an open-source web application that allows you to create and share documents containing code, equations, visualizations, and narrative text. It supports many programming languages, including Python, and is commonly used in machine learning for exploratory data analysis and prototyping models.
Amazon Machine Learning (AML): AML is a cloud-based machine learning service offered by Amazon Web Services (AWS). It provides a simple interface for training and deploying machine learning models, making it easy to integrate machine learning into applications without requiring expertise in machine learning.
Advantages of Machine Learning
Machine Learning has many advantages.
Automation: ML allows for the automation of many tasks that would otherwise require manual intervention. This can lead to significant time and cost savings for businesses and organizations.
Speed and efficiency: ML algorithms can process and analyze vast amounts of data much faster than humans could. This can lead to faster insights and better decision-making.
Accuracy: ML algorithms can be highly accurate and precise, especially when trained on large amounts of high-quality data.
Scalability: ML algorithms can be scaled to handle large and complex data sets, making it possible to analyze and process data that would be impossible to handle manually.
Personalization: ML algorithms can personalize products, services, and experiences based on individual user preferences and behavior.
Continuous learning: ML algorithms can learn and adapt over time, making them well-suited for tasks that involve changing or dynamic data.
Improved decision-making: ML can help organizations make more informed decisions by providing insights and predictions based on data.
Exploration: ML can help discover patterns and relationships in data that may not be immediately apparent or visible to humans.
Disadvantages of Machine Learning
Even though there are a lot of advantages of machine learning, there are many disadvantages as well.
Data quality: ML algorithms require high-quality data to produce accurate results. If the data used to train the model is biased, incomplete, or contains errors, it can lead to inaccurate predictions.
Data quantity: ML algorithms require large amounts of data to be effective. In some cases, it may be difficult or expensive to collect enough data to train the model.
Interpretability: Many ML algorithms are complex and difficult to interpret. It can be challenging to understand how the model arrived at its predictions or why it makes certain decisions.
Overfitting: ML models can sometimes overfit the training data, meaning they become too specialized to the specific data set they were trained on and do not generalize well to new data.
Human expertise: ML algorithms may require human expertise to interpret and validate the results. This can be time-consuming and expensive.
Security and privacy: ML algorithms can be vulnerable to attacks, mainly if they are based on sensitive or personal data.
Bias and discrimination: ML algorithms can reproduce and even amplify biases and discrimination present in the training data. This can lead to unfair or discriminatory outcomes.
Limitations of Machine Learning
Apart from the disadvantages, machine learning also has some limitations:
Limited by available data: Machine learning models require large amounts of data to be trained effectively. If there is not enough data available or the data is biased, the model's performance may be limited.
Limited by data quality: The data quality used to train machine learning models is essential. Poor quality data, such as data with missing values or errors, can affect the accuracy of the model's predictions.
Limited by algorithm limitations: Machine learning algorithms have restrictions regarding the complexity of problems they can solve. Some issues may require more sophisticated algorithms that still need to be made available.
Limited by interpretability: Machine learning models can be challenging to interpret, making it difficult to understand how they arrive at their predictions. This lack of interpretability can be a concern in applications where human decision-making is critical.
Limited by ethics and bias: Machine learning models can perpetuate bias in the data they are trained on, leading to biased outcomes. This can be especially problematic in applications such as hiring or loan decisions, where bias can have significant consequences.
Limited by the need for continual learning: Machine learning models may require continual updates and training to adapt to changes in the data or the environment. This can be time-consuming and costly.
Examples of Machine Learning
Machine learning has a wide range of applications and examples:
Image and object recognition: Machine learning algorithms are used in image recognition systems to identify objects and people in images. Examples include facial recognition technology, self-driving cars, and image tagging on social media platforms.
Recommender systems: Machine learning algorithms provide personalized recommendations to users based on their past behavior. Examples of this include movie recommendations on Netflix and product recommendations on Amazon.
Fraud detection: Machine learning algorithms can detect fraudulent transactions and activity in financial systems. Examples of this include credit card fraud detection and anti-money laundering systems.
Predictive maintenance: Machine learning algorithms are used to predict when equipment or machinery is likely to fail, allowing preventative maintenance before a breakdown occurs. Examples of this include predictive maintenance in the manufacturing and aviation industries.
Financial analysis: Machine learning algorithms analyze financial data and predict stock prices, market trends, and investment opportunities.
Real-World Applications of MachineLearning
Computer Vision
Computer vision and machine learning are often combined to create intelligent systems that recognize and understand visual information. Computer vision involves developing algorithms to analyze and interpret visual data from the world around us, such as images and videos. Machine learning involves developing algorithms that can learn patterns and make predictions based on data.
In computer vision, machine learning is often used to develop models that perform tasks such as object detection, image classification, and semantic segmentation. For example, a machine learning model can be trained to recognize objects in images by learning from a large dataset of labeled images. The model can then be used to classify new images by detecting the presence of these objects.
Convolutional Neural Networks (CNNs) are a common type of machine learning model used in computer vision. CNNs are designed to learn relevant features from raw image data automatically. They consist of multiple layers of convolutional filters that scan images and extract high-level features such as edges and corners. The features are then passed through fully connected layers that can make predictions based on the extracted features.
Natural Language Processing
Natural Language Processing focuses on the ability of machines to understand and interpret human language. NLP is a critical component of many modern applications, such as chatbots, language translation, sentiment analysis, and speech recognition.
NLP in machine learning involves processing large amounts of natural language text data and using algorithms to analyze and understand the language. Some common techniques used in NLP include:
Text preprocessing: This involves cleaning and normalizing text data by removing stop words and punctuation and converting all text to lowercase.
Tokenization: This involves breaking down the text into individual words or phrases called tokens.
Sentiment analysis: This involves analyzing the sentiment or emotion behind a piece of text, often used for tasks such as customer feedback analysis.
Named Entity Recognition (NER): This involves identifying and extracting specific entities such as people, organizations, and locations mentioned in the text.
Language translation: This involves translating text from one language to another.
Text summarization: This involves automatically summarizing large amounts of text into a shorter, more concise version.
Some common machine learning algorithms used in NLP include
Neural Networks: This involves using deep learning techniques such as Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs) to process natural language data.
Support Vector Machines (SVMs): This involves using a machine learning algorithm to separate text into different categories, such as positive or negative sentiment.
Hidden Markov Models (HMMs): This involves using a statistical model to identify and extract entities from text data.
Robotics
Robotics and machine learning are closely connected fields that often work together to create intelligent robotic systems. Machine learning can be used in robotics for a variety of tasks, including perception, control, and decision-making.
In robotics, perception involves the ability of a robot to sense and interpret its environment. Machine learning can be used to develop models that can process sensor data and interpret it to recognize objects or navigate through the environment. For example, a robot may use a camera to capture an image and then use machine learning algorithms to classify the objects in the image.
Control is another important aspect of robotics that can benefit from machine learning. Machine learning can be used to develop models that can learn to control the movement of a robot based on sensor data. Reinforcement learning algorithms can be used to train a robot to perform a task by providing it with feedback on its actions.
Decision-making is also a critical aspect of robotics that can benefit from machine learning. Machine learning algorithms can be used to develop models that can make decisions based on sensor data and optimize robot behavior. For example, a robot may use machine learning algorithms to plan its path through a complex environment.
Healthcare
Machine learning has numerous applications in healthcare, ranging from medical imaging and diagnosis to personalized treatment and drug discovery. The vast amount of data generated by healthcare systems, including electronic health records, medical images, and clinical trials, can be analyzed using machine learning algorithms to uncover insights that can improve patient outcomes and advance medical research.
One important application of machine learning in healthcare is medical imaging. Machine learning models can be trained to analyze medical images and identify patterns that are indicative of diseases such as cancer or heart disease. This can help radiologists and other healthcare professionals to make more accurate diagnoses and provide better treatment options for patients.
Another important application of machine learning in healthcare is personalized treatment. Machine learning models can analyze large amounts of patient data, including genetics, medical history, and lifestyle factors, to develop personalized treatment plans that are tailored to the individual patient. This can lead to more effective treatments and better patient outcomes.
Future of Machine Learning
The future of machine learning is promising, as the field is continuously advancing and expanding. Here are some possible trends and developments that could shape the future of machine learning:
Increased automation: Machine learning algorithms are becoming more automated and require less human intervention. This trend is expected to continue, leading to more efficient and effective processes.
Advances in deep learning: Deep learning techniques, which involve the use of artificial neural networks, are becoming more sophisticated and powerful. This trend is expected to continue, leading to improved accuracy and performance in a wide range of applications.
Integration with other technologies: Machine learning is being integrated with other technologies, such as robotics, IoT, and blockchain, to create new applications and solutions.
Challenges of Machine Learning
Below are some of the major challenges of machine learning:
Complex Process It is believed that machine learning can be a complex process. It is dynamic in nature and consists of multiple steps. These steps can be data training, processing, mode selection, evaluation, etc. So we need to manage them effectively. Therefore machine learning can be a tedious task for many as huge coordination is required. We can overcome this challenge by breaking the tasks into subtasks and monitoring the conditions required. Also, executing someone who is an expert in their in domain can reduce the complexity, and therefore we can make sure that we get the desired results.
Regular maintenance and monitoring: Another major challenge is the regular maintenance and monitoring of models. This is an important step for ensuring that efficiency is maintained and that we get the desired results without errors. It can also be tedious tasks. Regular maintenance is required to maintain and increase the consumption of our product by seeing that the output quality is being maintained.
Overfitting and Underfitting: Overfitting challenge is faced by machine learning engineers when the model is trained with vast data. The machine learning models become much more complex, and noise is captured, resulting in data inaccuracy. Conversely, underfitting means that the machine learning model is trained with very little data. The models are not able to capture the underlying patterns, which results in data accuracy.
Decreasing data quality: Data quality is crucial for enhancing the output. The algorithms in machine learning need high-quality data for making appropriate decisions. Machine learning professionals face the major challenge of the absence of good quality data, as noisy data makes a process more and more tedious. Inconsistent data, biased datasets, and missing labeling in data hinder the performance of the models used in machine learning.
Slow implementation: One of the most common issues faced by professionals in the field is the slow implementation of the programs. As there are multiple steps involved, such as data processing, training a model, and testing iterations, a significant amount of time may be required to produce the desired results. Also, if we want to scale the machine learning models for handling huge datasets, that may result in complexities. They take a lot of time to produce accurate results. For example, training of neural networks consumes a lot of time.
Data Biasing: This is a major challenge in machine learning. These biasing errors occur when some of the dataset elements are weighted heavily and given more attention than others. We can also involve experts in the domain to address the issue. For example, a model that is trained to give access of a certain facility only to people belonging to a certain area or race, presents biased practices.
Frequently Asked Questions
What exactly is machine learning?
Machine learning is a subcategory of Artificial Intelligence that consists of developing algorithms and statistical models that enable computer systems to automatically learn from data without being explicitly programmed.
What are the 3 types of machine learning?
The three main types of Machine Learning are Supervised, unsupervised, and reinforcement learning. The supervised learning uses labeled data to predict outcomes. Whereas unsupervised Learning uses unlabelled data to predict outcomes. And, the reinforcement learning is trained by rewarding or punishing for the desired outcome.
What are the 4 basics of machine learning?
The four basics of machine learning include supervised learning which uses labeled datasets for training algorithms, unsupervised learning uses unlabeled datasets. semi-supervised learning uses both labeled and unlabeled datasets, and lastly, reinforcement learning uses the trial-and-error methodology included with a feedback process.
Conclusion
In this article, we discussed about machine learning, its tools, features, types, lifecycle, working, advantages, and disadvantages of Machine Learning. We have seen some examples and the future of Machine learning. We have also discussed some real-world applications of Machine learning in computer vision, natural language processing, robotics, and in the healthcare field. I hope this blog helped you gain knowledge about machine learning. You can also consider our Machine Learning Course to give your career an edge over others.































 9+ registered
9+ registered 

