Types of Perceptron
There are two types of perceptron:
1. Single-Layer Perceptron (SLP)
- Description: Consists of a single layer of output nodes connected directly to the input features. It performs binary classification tasks by linearly separating data into two classes.
- Example: Basic binary classification problems like classifying data points as belonging to one of two categories.
2. Multi-Layer Perceptron (MLP)
- Description: Contains one or more hidden layers between the input and output layers. It can solve more complex problems by learning non-linear decision boundaries.
- Example: Image recognition or complex function approximation tasks.
Perceptron in Machine Learning
The Perceptron is a fundamental algorithm in machine learning that serves as a building block for more complex models. It is a type of linear classifier that makes predictions based on a linear predictor function. The Perceptron algorithm adjusts the weights of features based on the classification errors it makes, learning to make better predictions over time.
History of Perceptron
In 1957, Frank Rosenblatt introduced the Perceptron model at the Cornell Aeronautical Laboratory. He aimed to simulate a simplified version of the human brain's neuron. In the 1960s, the Perceptron was initially successful but faced limitations, leading to the "AI Winter," a period of reduced funding and interest in neural networks. In 1980, the development of multi-layer networks and backpropagation revived interest in neural networks, leading to modern deep learning.
What is the Perceptron Model in Machine Learning?
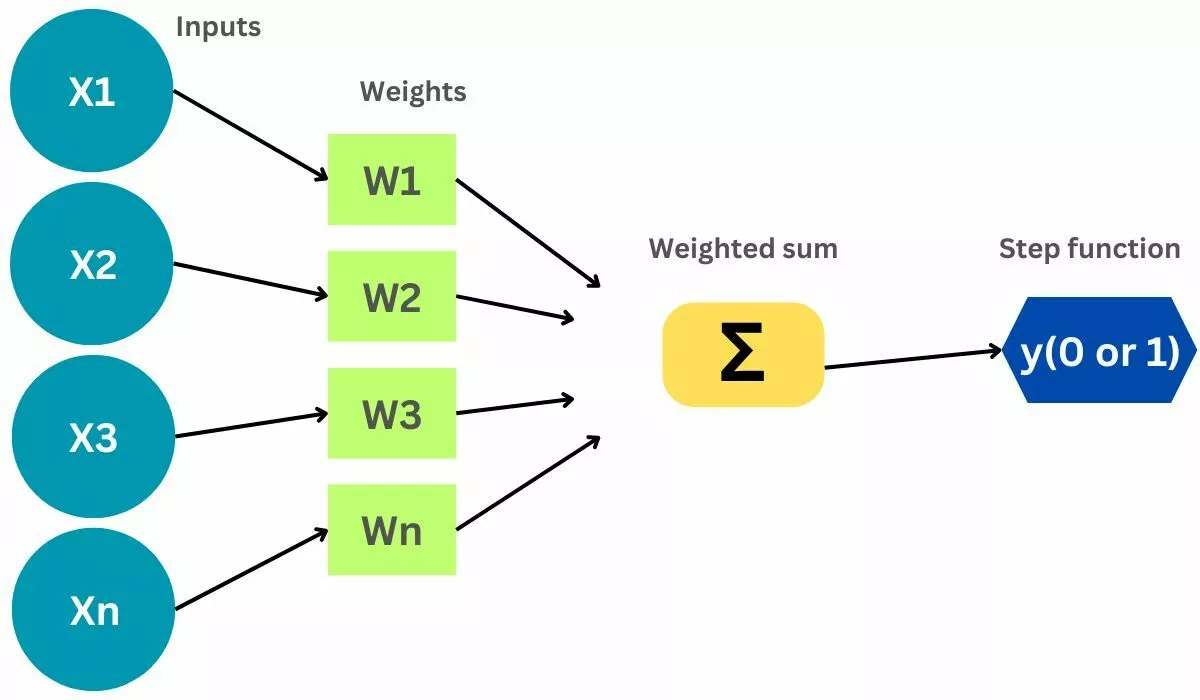
The Perceptron model is a simple type of artificial neural network used for binary classification. It consists of input nodes, weights, a bias term, and an activation function. The model computes a weighted sum of the inputs and applies an activation function to decide the output class.
How Does Perceptron Work?
- Initialization: Start with random weights and bias.
- Input Processing: Compute the weighted sum of the input features.
- Activation Function: Apply a step function to determine the output class.
- Error Calculation: Compare the predicted output with the actual label.
- Weight Adjustment: Update the weights and bias based on the error using the Perceptron Learning Rule.
- Iteration: Repeat the process for multiple epochs until convergence.
Characteristics of the Perceptron Model
- Linear Separability: Effective only for linearly separable data.
- Binary Classification: Primarily used for binary classification tasks.
- Simple Structure: Consists of a single layer of weights.
- Training Algorithm: Uses the Perceptron Learning Rule for weight updates.
- Activation Function: Typically a step function.
Limitation of Perceptron Model
- Linearly Separable Data: Cannot solve problems where data is not linearly separable.
- Single Layer Limitation: Limited to problems that can be separated by a single hyperplane.
- No Hidden Layers: Lacks the capability to model complex patterns without hidden layers.
- Convergence Issues: May not converge on certain data sets if not properly tuned.
Perceptron Learning Rule
The Perceptron Learning Rule adjusts the weights and bias based on the classification error. It updates weights according to the formula: weightnew=weightold+learning rate×(actual−predicted)×input\text{weight}_{\text{new}} = \text{weight}_{\text{old}} + \text{learning rate} \times (\text{actual} - \text{predicted}) \times \text{input}weightnew=weightold+learning rate×(actual−predicted)×input The bias is updated similarly to account for the error.
Perceptron Function
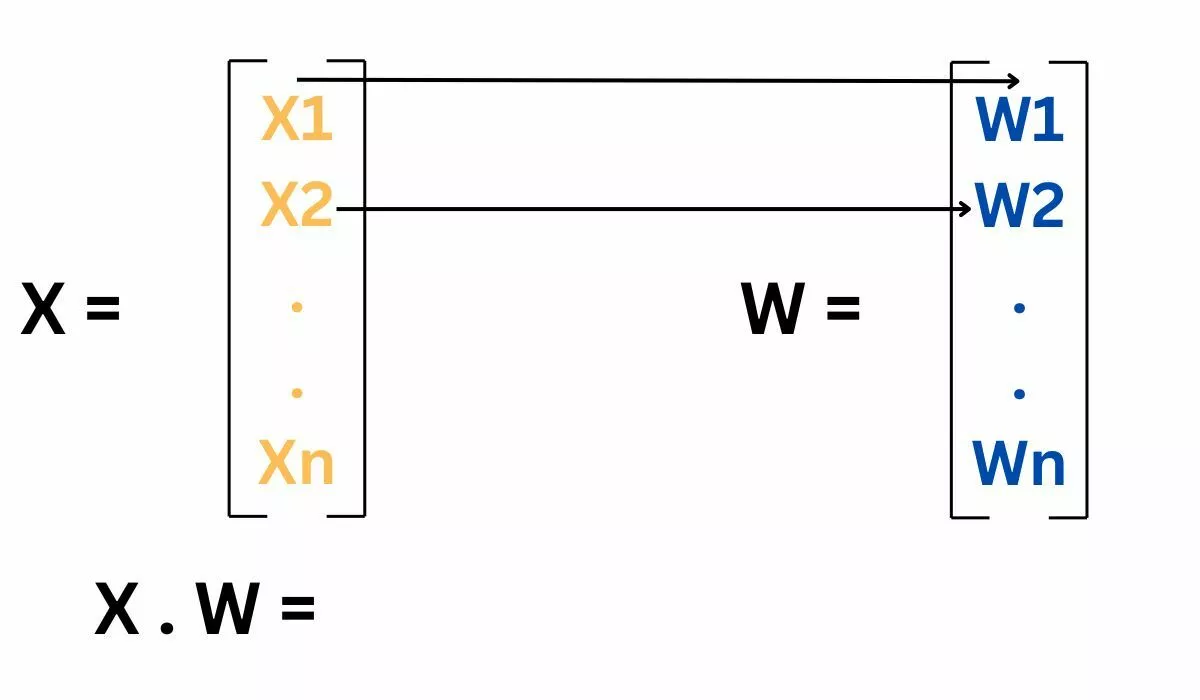
The Perceptron function computes a weighted sum of the input features and applies an activation function to determine the output. The function is: output=activation(∑(weighti×inputi)+bias)
Inputs of a Perceptron
Inputs to a Perceptron are the features of the data. Each input is associated with a weight that represents its importance. The Perceptron uses these inputs and weights to compute the weighted sum for further processing.
Activation Functions of Perceptron
The activation function in a Perceptron is typically a step function, which outputs binary values (0 or 1) based on whether the weighted sum of inputs exceeds a threshold. Other functions like the sigmoid can also be used in variations of Perceptrons.
Output of Perceptron
The output of a Perceptron is a binary value (0 or 1) indicating the class of the input data. It is determined by applying the activation function to the weighted sum of inputs.
Error in Perceptron
Error in a Perceptron is the difference between the actual label and the predicted output. It is used to adjust the weights and bias during training to minimize classification errors.
Perceptron: Decision Function
The Perceptron decision function calculates the class of an input by computing a weighted sum of the input features and applying the activation function. If the weighted sum is above a certain threshold, it classifies the input into one class; otherwise, it classifies it into another.
Perceptron at a Glance
- Basic Model: Single-layer neural network.
- Linear Classifier: Effective for linearly separable data.
- Training: Adjusts weights using the Perceptron Learning Rule.
- Activation Function: Typically a step function.
- Limitations: Struggles with non-linearly separable data.
Implement Logic Gates with Perceptron
Perceptrons can be used to model basic logic gates by setting appropriate weights and bias:
- AND Gate: Outputs 1 only if both inputs are 1.
- OR Gate: Outputs 1 if at least one input is 1.
- NAND Gate: Inverts the output of the AND gate.
- NOR Gate: Inverts the output of the OR gate.
What is Logic Gate?
Logic gates are fundamental components of digital circuits that perform basic logical operations on one or more binary inputs to produce a single binary output. They are used to build complex digital systems.
Implementing Basic Logic Gates With Perceptron
- AND Gate: A Perceptron with weights set to values that only activate if both inputs are high (1).
- OR Gate: A Perceptron with weights that activate if at least one input is high (1).
- NAND Gate: A Perceptron that outputs the opposite of the AND gate.
- NOR Gate: A Perceptron that outputs the opposite of the OR gate.
Frequently Asked Questions
What is the difference between neural network and perceptron?
A perceptron is a single-layer neural network used for binary classification, whereas a neural network can have multiple layers (hidden layers) and handle complex patterns and tasks beyond simple linear separability.
What are the 4 parts of perceptron?
The four parts of a perceptron are input features, weights, a bias term, and an activation function. Inputs are weighted and summed, adjusted by bias, and passed through the activation function to produce the output.
What is the objective of perceptron learning?
The objective of perceptron learning is to adjust weights and biases to minimize classification errors, thereby finding the optimal decision boundary that separates different classes in the input feature space.
Conclusion
In this blog, we have discussed what perceptron is. It is a foundational model in machine learning and neural networks, representing one of the simplest forms of a neural network. It serves as a building block for more complex models and algorithms.
Check this out to know about Machine Learning.
Happy Learning






























 8+ registered
8+ registered 

