Do you think IIT Guwahati certified course can help you in your career?
Introduction
A HashSet in Java implements the Set interface and is supported by a HashMap, whereas a TreeSet implements sorted sets and is backed by a TreeMap.
We will first look at both the sets definitions and how it gets implemented. Later in the blog, we will look at HashSet and TreeSet differences. We will also cover the programs for a thorough understanding of the topic.
What is HashSet?
A HashSet is a data structure used in computer science to store a collection of unique elements. It is a part of the collections framework in many programming languages, including Java and C#.
In a HashSet, elements are stored in a way that ensures uniqueness; that is, no two elements in the set can be equal according to the equals() method (or equivalent) of the elements. Additionally, elements in a HashSet are not stored in any particular order.
This data structure is optimized for fast insertion, deletion, and lookup operations. Internally, it typically uses a hash table or a similar mechanism to achieve efficient performance.
HashSetExample.java
Java
Java
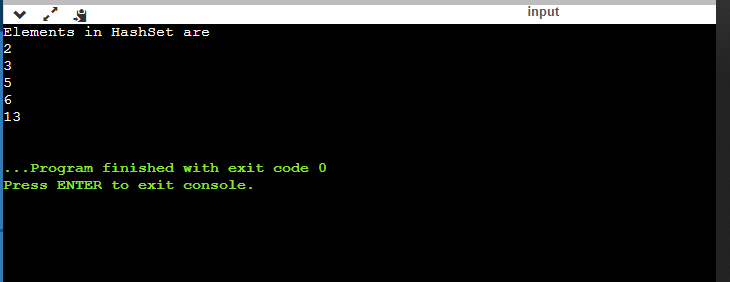
import java.util.HashSet; public class HashSetEx { public static void main(String[] args) { /*creating a HashSet */ HashSet<Integer> hashSet= new HashSet<Integer>(); /* add elements to HashSet */ hashSet.add(5); hashSet.add(2); hashSet.add(3); hashSet.add(6); hashSet.add(13); System.out.println("Elements in HashSet are "); /* iterate in hashSet */ for(int hash: hashSet){ System.out.println(hash); } } }
You can also try this code with Online Java Compiler
A TreeSet is another data structure used to store a collection of elements in computer science, particularly in languages like Java. It is part of the collections framework and is designed to store unique elements in sorted order.
Internally, a TreeSet is typically implemented using a self-balancing binary search tree, such as a red-black tree. This structure maintains the elements in sorted order, which allows for efficient retrieval of elements in sorted sequence. The elements are sorted based on their natural ordering (if they implement the Comparable interface) or by a specified comparator provided during construction.
TreeSetExample.java
Java
Java
import java.util.TreeSet; public class TreeSetEx { public static void main(String[] args) { /* creating a TreeSet */ TreeSet<String> treeSet= new TreeSet<String>(); /* add elements to HashSet */ treeSet.add("yellow"); treeSet.add("blue"); treeSet.add("green"); /* Duplicate elements will not be stored */ treeSet.add("blue"); System.out.println("Elements in TreeSet are “); System.out.println(treeSet); } }
You can also try this code with Online Java Compiler
Let’s try to understand some of the differences through programs.
Null Values in HashSet
When you try to insert Null values in HashSet
Java
Java
import java.util.HashSet; public class HashSetEx { public static void main(String[] args) { /* creating a HashSet */ HashSet<Integer> hashSet= new HashSet<Integer>(); /* add elements to HashSet */ hashSet.add(5); hashSet.add(2); hashSet.add(3); hashSet.add(6); hashSet.add(0); System.out.println("Elements in HashSet are "); /* iterate in hashSet */ for(int hash: hashSet){ System.out.println(hash); } } }
You can also try this code with Online Java Compiler
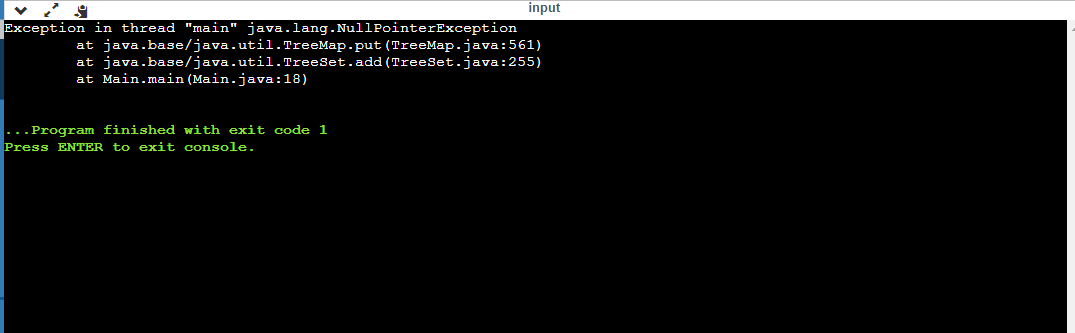
import java.util.TreeSet; public class TreeSetEx { public static void main(String[] args) { /* creating a TreeSet */ TreeSet<String> treeSet= new TreeSet<String>(); /* add elements to HashSet */ treeSet.add("Mango"); treeSet.add("banana"); treeSet.add(null); /* Duplicate elements will not be stored */ treeSet.add("blue"); System.out.println("Elements in TreeSet are "); System.out.println(treeSet); } }
You can also try this code with Online Java Compiler
Thread safety is not provided by HashSet or TreeSet
They are not synchronized, but we can synchronize them using the Collections.synchronizedSet() function
Both classes' iterators are fail-fast in nature. If we try to edit an iterator after it has been generated, it throws a ConcurrentModificationException
Both use the clone() function to produce a clone of their objects using the shallow copy technique
Which one is better to use?
HashSet offers O(1) performance for add, remove, and contains, but does not maintain order. TreeSet maintains elements in sorted order using a binary tree but has O(log n) worst-case performance for basic operations. Use HashSet if you need constant time performance and don't require order, and use TreeSet if you need sorted elements and efficient traversal in sorted order, especially for larger sets. The choice depends on specific use cases and set sizes.
HashSet performs search, insert, and delete operations in constant time. This makes HashSet faster than TreeSet, which takes O(Log n) time. The reason behind this is that HashSet is implemented using a hash table, while TreeSet uses a sorted data structure.
What is the difference between HashSet and TreeSet?
HashSet is an unordered collection of unique elements, relying on hashing for fast operations. TreeSet is a sorted collection, using a self-balancing binary search tree.
Which is faster for searching operations TreeSet or HashSet?
HashSet offers faster search operations.
What is the difference between TreeSet and TreeMap?
TreeSet ensures elements are sorted, which aids in retrieval. TreeMap, like TreeSet, is sorted but stores key-value pairs.
Conclusion
In this blog, we have learned about the Difference Between HashSet and TreeSet. We started by introducing the sets and covered the differences between their sets. We have coded programs for a thorough understanding of HashSet vs TreeSet.
To learn more about Sets, please refer to our blog
Refer to our guided pathways on Code studio to learn more about DSA, Competitive Programming, JavaScript, System Design, etc. Enroll in our courses, and use the accessible sample exams and questions as a guide. For placement preparations, look at the interview experiences and interview package.

































 8+ registered
8+ registered 

