Distributed Computing
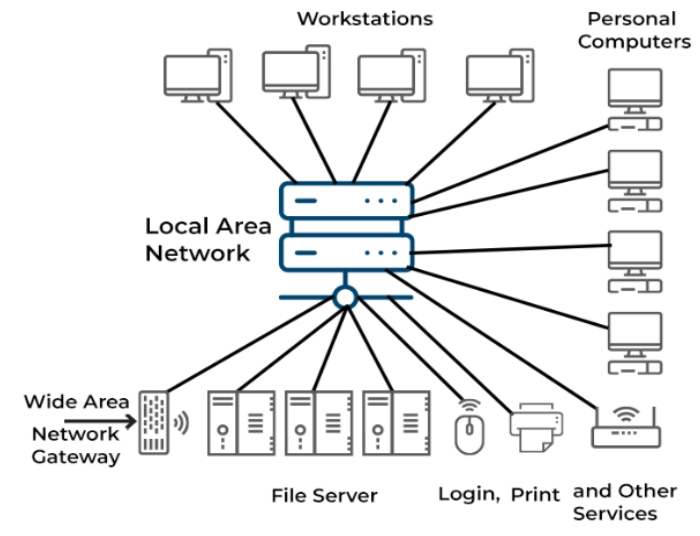
In Computer science, Distributed Computing studies distributed systems. In a distributed system, the components are spread across multiple networked computers and communicate and coordinate their actions by transferring messages from one system to the next.
The components interact with one another so that they can reach a common purpose. Maintaining component concurrency, overcoming the lack of a global clock, and controlling the independent failure of parts are three crucial issues of distributed systems. When one system's component fails, the system does not fail. Peer-to-peer applications, SOA-based systems, and massively multiplayer online games are all examples of distributed systems.
The use of distributed systems to address computational issues is frequently referred to as distributed computing. A problem is divided into numerous jobs in distributed computing, each of which is solved by one or more computers that communicate with one another via message passing.
source
Need for Distributed Computing for Big Data
-
Not every situation necessitates the use of distributed computing. Complicated processing can be done remotely using a specialist service if there isn't a significant time limitation. IT moves data to an external service or entity with plenty of free resources for processing when corporations want to undertake extensive data analysis.
-
The data management industry was transformed by robust hardware and software innovations. First, demand and innovation boosted the power of hardware while lowering its price. The new software was developed to use this hardware by automating activities such as load balancing and optimization over a large cluster of nodes.
-
Built-in rules in the software recognized that certain workloads demanded a specific level of performance. Using the virtualization technology, software regarded all nodes as one giant pool of processing, storage, and networking assets. It shifted processes to another node without interruption if one failed.
- It wasn't that firms didn't want to wait for the results they required; it was simply not financially feasible to purchase enough computing power to meet these new demands. Because of the costs, many businesses would merely acquire a subset of data rather than trying to gather all of it. Analysts wanted all of the data, but they had to make do with snapshots to capture the appropriate data at the right time.
Distributed Computing Advantages
-
Distributed computing allows information to be shared among multiple people or systems.
-
Distributed computing allows one machine's application to tap into the processing power, memory, or storage of another. Although distributed computing may improve the performance of a stand-alone application, this is rarely the case.
- Some applications, such as word processing, may not benefit from distribution. In many circumstances, a specific problem may need distribution. Distribution is a natural fit for a corporation that wants to collect data across multiple locations. In other events, distribution can help improve performance or availability.
Change in the economics of computing
A lot has changed in the interim. The cost of purchasing computational and storage resources has dropped considerably. Commodity servers that could be clustered and blades networked in a rack revolutionized the economics of computing, thanks to virtualization. This shift corresponded with advancements in software automation technologies that vastly improved the system's management.
Using distributed computing and parallel processing techniques to cut latency drastically revolutionized the scene. Low latency can only be achieved in some applications, such as High-Frequency Trading (HFT), by physically placing servers in a single area.
Big data demand meets solutions
The rise of the Internet as a platform for everything from commerce to medical shifted the demand for a new generation of data management software. Engine and Internet firms like Google, Yahoo!, and Amazon.com developed their business models in the late 1990s by using low-cost processing and storage technology.
Following that, these businesses need a new generation of software solutions to help them monetize the massive amounts of data they were collecting from clients. These businesses couldn't wait for analytic processing results. They needed to be able to process and evaluate this information in real-time.
FAQs
What is Big Data?
Big data refers to data collections that are too massive or complicated for typical data-processing application software to handle. Data with more fields have more statistical power; however, data with more fields have a higher false discovery rate.
What is distributed computing?
The subject of computer science known as distributed computing explores dispersed systems. A distributed system is one in which the components are spread across multiple networked computers and communicate and coordinate their actions by transferring the messages from one system to another.
What are the advantages of distributed computing?
Distributed computing allows one machine's application to tap into the processing power, memory, or storage of another. Although distributed computing may improve the performance of a stand-alone application, this is rarely the case.
Conclusion
This article briefly discussed Distributed Computing, and we also have examined the need for distributed computing for big data.
We hope that this blog has helped you enhance your knowledge regarding Distributed Computing neede for Big data and if you would like to learn more, check out our articles here. Do upvote our blog to help other ninjas grow.
Refer to our guided paths on Coding Ninjas Studio to learn more about DSA, Competitive Programming, JavaScript, System Design, etc. You can also consider our Data Analytics Course to give your career an edge over others..
Happy Learning!






























 9+ registered
9+ registered 

