Do you think IIT Guwahati certified course can help you in your career?
Introduction
PostgreSQL(PSQL) is a powerful, open-source database that helps us to store data efficiently. A simplified view of data along with fast access to it becomes an important factor when dealing with a large database.
We use a View to see data according to our needs and use indexing to access data quickly.
In this article, we will understand both these concepts in detail.
Let us start by discussing Views in PostgreSQL.
What Are Views In PostgreSQL?
A view in PostgreSQL can be considered as a virtual table that does not permanently occupy memory. A view does not form part of the physical schema and shows us data virtually from ordinary tables. It looks similar to an ordinary table in SQL and may contain all or some of its rows and columns.
Views are advantageous and may help you in the following ways.
Views allow you to structure data according to your needs in a table-like fashion.
You can enable authorization using views. You may grant permissions to only specific users to certain rows and columns of your table.
Views can collect and record data to create reports.
Once you create a view, you can see it again with a simple select statement. This feature helps us to avoid writing complex queries again and again.
Let us learn how to create views in PostgreSQL.
Creating Views
We can create views in SQL using the Create View statement. Take a look at its syntax.
Syntax
CREATE VIEW <view_name>
AS
SELECT <column(s)>
FROM <table_name(s)>
WHERE <condition>;
You specify your view name just after the Create View statement. Then you use the AS clause and enter your query. The data in the view created will satisfy the provided query.
From the above syntax, note that you can create a view containing data from multiple tables. Just specify the table names according to the syntax described above.
Once you have created the view, you can query it again using a simple select statement.
SELECT * from <view_name>;
The above query will display the view on your screen.
Example
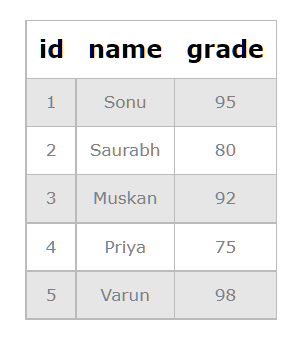
Suppose after a coding contest is over, Coding Ninjas wants to reward those students who achieved a score of more than 90. We already have a student_info table with some data in it.
We have to create a view that shows the names of the high achievers.
CREATE VIEW high_achievers AS
SELECT name FROM student_info WHERE grade > 90;
Our view high_achievers is created. Run the following command to see the view.
SELECT * FROM high_achievers;
As you can see, the names of only those students whose grades were above 90 are visible.
Temporary Views
Sometimes, you may need a view only for a short period or a single session. In that case, you can create a temporary view. You just have to add the TEMPORARY or TEMP keyword after the Create keyword in the original syntax.
CREATE [TEMP|TEMPORARY] VIEW <view_name>
AS
SELECT <column(s)>
FROM <table_name>
WHERE <condition>;
This temporary view will get automatically deleted after you end your session.
Basic Operations On Views
Let us look at some basic operations we can perform on an existing view. Knowledge of these operations will help you efficiently manage views and data.
Renaming Views
You can rename a current view using the Alter and Rename keywords.
ALTER VIEW <OLD_view_name> RENAME TO <NEW_view_name>;
Deleting Views
The DROP keyword is used to remove an existing view. It has a simple syntax.
DROP VIEW <view_name>;
Note that if you try to delete a view that does not exist, Postgres will give you an error. To avoid this, you can use an optional IF EXISTS clause.
DROP VIEW [IF EXISTS] view_name;
Updating Views
An important fact about views is that you can modify them without dropping them. This statement means you can change the definition or the query that creates a view. The syntax is much similar to that of creating a view.
CREATE or REPLACE VIEW <view_name>
AS
SELECT <column(s)>
FROM <table_name(s)>
WHERE <condition>;
Materialized View
A Materialized View is a database object that stores the results of a query as a physical copy in a separate location. Unlike standard views, materialized views get saved in memory.
This view can be helpful in many scenarios, such as
Improving query performance: Since the data in a materialized view is pre-computed and stored in a separate location, querying it can be faster than running the original query. This is very useful for queries that take a long time to run or that are frequently run.
Offloading work from the database server: By storing the results of a query in a materialized view, you can reduce the workload on the database server by allowing it to focus on other tasks.
Ensuring data consistency: If you have a query that joins data from multiple tables, a materialized view can ensure that the data is consistent by storing a snapshot of the data at a specific point in time.
You can use the CREATE MATERIALIZED VIEW statement to create a materialized view in SQL.
Syntax:
CREATE MATERIALIZED VIEW <view_name> AS SELECT * FROM <table_name> WHERE <condition>;
To update your materialized view or load data into it, you need to refresh your view. Use the REFRESH MATERIALIZED VIEW statement to refresh an existing view.
Note that Postgres locks the table whose view is being refreshed. You cannot use the table while the refresh is in progress. You can prevent this from happening if you use the CONCURRENTLY keyword.
What Are Indexes And How To Create Them In PostgreSQL?
In a database, an index is a structure that allows for faster data retrieval by providing a way to look up data quickly. It improves the performance of database queries.
Indexes work by creating a separate data structure that stores a copy of the data from a specific column or set of columns in a table. Specify the column or columns you want to index when creating an index. The index stores the data in a way that makes it easier to search and retrieve specific rows from the table.
For example, Consider you have a table with a large number of rows. You frequently need to search for a specific row based on the value of a particular column. In such a case, you can create an index on that column to speed up the search process. The index will allow you to look up the data much faster than if you had to search through the entire table.
Features Of Indexes In PostrgreSQL
PostgreSQL indexes have the following features:
Type of data: PostgreSQL supports various types of indexes, including B-tree, hash, full-text search, spatial, and bitmap indexes. Each type of index is designed to support different types of data and queries.
Column selection: You can create an index on a single column or a combination of columns. This allows you to create an index that is tailored to the specific queries that you are running.
Index visibility: In PostgreSQL, indexes can be created as either visible or invisible. Visible indexes are used by the query planner to determine the best execution plan for a query. On the other hand, the invisible indexes are not considered by the query planner. This allows you to create an index for testing purposes without affecting the query planner's decision-making.
Index concurrency: PostgreSQL supports index-only scans, which allow the query planner to use an index to retrieve data without having to access the table itself. This can improve query performance and reduce the amount of load on the table.
Partial indexes: PostgreSQL supports the creation of partial indexes, which are indexes that only contain a subset of the rows in a table. This allows you to create a more selective index. It reduces the size of the index, which improves query performance.
Creating Indexes
We can create indexes using the CREATE INDEX statement. We define the index name along with the table and column name associated with the index.
Syntax:
CREATE [UNIQUE] INDEX <index_name>
ON <table_name>
[USING index_method]
(column_name [ASC | DESC] [NULLS {FIRST | LAST}], ...);
Understanding the syntax:
The above syntax has some keywords which you might be unaware. We have explained all such keywords below.
CREATE: This keyword indicates that you are creating a new index.
UNIQUE: This keyword is optional. It specifies that no two rows in the table can have the same values in the indexed columns.
INDEX: This keyword indicates that you are creating an index.
index_name: This is the name of the index. It should be unique within the schema in which it is created.
USING index_method: This optional clause specifies the type of index to create. For example, btree, hash, gist, spgist, gin, and brin.
column_name: This is the name of the column or columns to be indexed. You can specify multiple columns by separating them with a comma.
ASC | DESC: This optional clause specifies the sort order for the indexed column. ASC stands for ascending order, while DESC stands for descending order.
NULLS {FIRST | LAST}: This optional clause specifies how NULL values should be sorted in the index. FIRST specifies that NULL values should be sorted before non-NULL values, while LAST specifies that NULL values should be sorted after non-NULL values.
Example
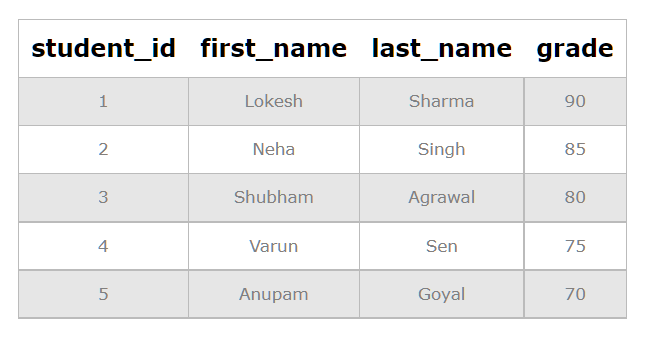
Here is an example of creating and using an index in PostgreSQL, using a table named student_info with some sample data:
First, let's create the student_info table and insert some data:
CREATE TABLE student_info (
student_id INT PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
grade INT NOT NULL
);
INSERT INTO student_info (student_id, first_name, last_name, grade)
VALUES
(1, 'Lokesh', 'Sharma', 90),
(2, 'Neha', 'Singh', 85),
(3, 'Shubham', 'Agrawal', 80),
(4, 'Varun', 'Sen', 75),
(5, 'Anupam', 'Goyal', 70);
Select * from student_info;
Output:
Next, let's create an index on the grade column:
CREATE INDEX grade_index ON student_info (grade);
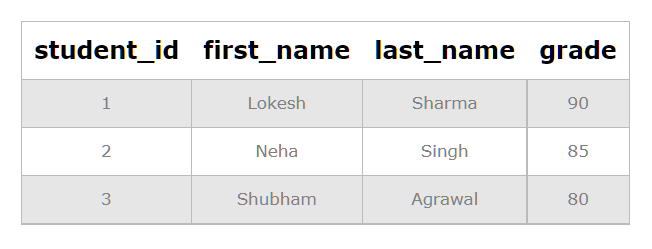
Now we can use the index to improve the performance of queries that filter or sort the data based on the grade column. For example, the following query will use the index to quickly find all students who have a grade of 80 or higher:
SELECT * FROM student_info WHERE grade >= 80;
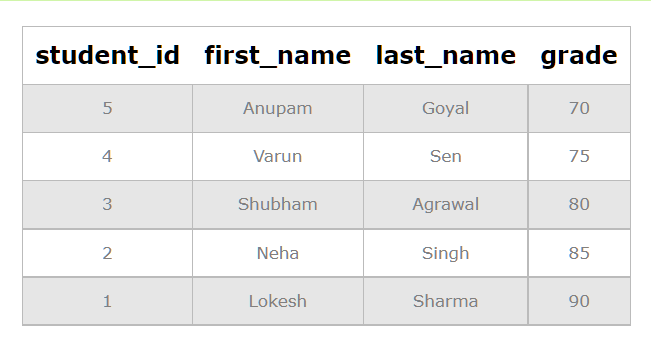
The index will also be used to quickly sort the data by the grade column:
SELECT * FROM student_info ORDER BY grade;
Dropping Indexes
To drop an index in PostgreSQL, you can use the DROP INDEX statement.
Follow the syntax below.
DROP INDEX [ IF EXISTS ] index_name [ CASCADE | RESTRICT ];
Cascade and Restrict are optional clauses. Cascade specifies that any objects that depend on the index should also be dropped. Restrict tells us that the index should not be dropped if any objects depend on it.
Index Access Method Interface Definition
The Index Access Method (IAM) interface is a set of functions and data structures that define how a database index is implemented and accessed. In PostgreSQL, the IAM interface is used to define custom index types that can be used in place of the built-in index types, such as B-tree and hash indexes.
The IAM interface can be a powerful tool for customizing the behavior and performance of indexes. However, it requires a deep understanding of database internals and can be complex to implement. That is why we only use it in advanced scenarios where the built-in index types are insufficient.
Built-In Index Types
PostgreSQL supports several built-in index types that can be used to improve the performance of queries. These index types are based on different data structures and algorithms, which can be used to optimize different types of queries.
Here are the built-in index types available in PostgreSQL:
B-Tree Indexes
B-Tree indexes are the most commonly used index type in PostgreSQL. They are based on the B-Tree data structure, which is a balanced tree that allows for fast searches, insertions, and deletions. B-Tree indexes can be used to index data of any type. These indexes are generally the best choice for most indexing needs.
Hash Indexes
Hash indexes are based on the hash table data structure, which uses a hash function to map keys to indices in an array. Hash indexes are generally faster than B-Tree indexes for exact match queries but are not as efficient for range queries or sorting. They are also not suitable for indexing data with a high degree of correlation.
Generalized Inverted Index (GIN) Indexes
GIN indexes are used to index data structures that contain multiple values per key, such as arrays or JSON documents. They are based on the inverted index data structure, which stores a mapping from values to the keys that contain them. GIN indexes are generally more efficient than B-Tree indexes for indexing complex data structures, but they are slower to update and are not suitable for sorting or range queries.
Generalized Search Tree (GiST) Indexes
GiST indexes are used to index data that does not fit neatly into a B-Tree or other standard index structure. They are based on the generalized search tree data structure, which allows for the creation of customized index types that can support a wide range of queries and data types. GiST indexes are generally more flexible than other index types but are also slower and more complex to use.
Space-Partitioned GiST (SP-GiST) Indexes
SP-GiST indexes are a variant of GiST indexes that are optimized for indexing spatial data. They use a space-partitioning data structure to support efficient queries on spatial data, such as points, lines, and polygons.
BRIN (Block Range Index)
It is a type of index in PostgreSQL that is designed to index large tables with a small number of unique values. They work by storing summary information about the values in a table rather than storing the values themselves. This makes BRIN indexes much smaller and faster to update than traditional indexes, which can be useful for improving the performance of queries on large tables.
By choosing the appropriate index type for your data and queries, you can improve the performance of your database and reduce the load on your system. It is important to carefully consider the trade-offs of different index types and choose the one that best fits your needs.
Frequently Asked Questions
Can I have multiple indexes on a table in PostgreSQL?
Yes, you can have multiple indexes on a table in SQL. However, each index takes up space in the database, so it's important to consider the trade-off between the benefits of additional indexes and the cost of maintaining them.
Can I update data through a view in SQL?
It depends on the type of view you are using. If the view is updatable, you can use the UPDATE, INSERT, and DELETE statements to modify the data through the view. However, if the view is not updatable, you cannot modify the data through the view.
How do I create a new database in PostgreSQL?
To create a new database in PostgreSQL, you can use the following command:
createdb mydatabase;
This will create a new database with the name ‘mydatabase’.
Conclusion
In this article, we discussed the working of views and indexes in PostgreSQL. It covered the creation, deletion, and modification of views. A view in PostgreSQL can be considered as a virtual table that does not permanently occupy memory.
We hope you enjoyed reading this article. If you wish to learn more about SQL, refer to the following blogs.
Visit our website to read more such blogs. Make sure you enroll in our other courses as well. You can take mock tests, solve problems, and interview puzzles. Also, you can check out some exciting interview stuff- interview experiences and an interview bundle for placement preparations. Do upvote our blog to help fellow ninjas grow.
Keep Grinding! 🦾
Happy Coding! 💻
Live masterclass
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles
by Prerita Agarwal
27 Jul, 2026
12:30 PM
Multi-Agent AI Support Bot using OpenAI & Gemini
by Saurav Prateek
28 Jul, 2026
12:30 PM
Zomato Data Analysis Case Study: Ace 25L+ Roles in FoodTech(no use)
by Abhishek Soni
29 Jul, 2026
11:30 AM
Zomato Sales Analytics: SQL + PowerBI for 25LPA Jobs
by Abhishek Soni
29 Jul, 2026
11:30 AM
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles






























 9+ registered
9+ registered 

