


























99acres interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
99acres
6 rounds | 8 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 6 months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Referral
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Easy
Telephonic
Duration60 minutes
Interview date20 May 2015
Coding problem3
This was conducted by some Senior Software Developer.
They basically asked sql queries like : using joins and sub queries and basic sql concepts. OOPS concepts and puzzles were also asked.
1. DBMS Question
CHAR vs VARCHAR in SQL
Problem approach
1. CHAR datatype is used to store character string of fixed length. VARCHAR datatype is used to store character string of variable length
2. In CHAR, If the length of string is less than set or fixed length then it is padded with extra memory space. In VARCHAR, If the length of string is less than set or fixed length then it will store as it is without padded with extra memory spaces.
3. CHAR stands for “Character”. VARCHAR stands for “Variable Character”
4. Storage size of CHAR datatypes is equal to n bytes i.e. set length. Storage size of VARCHAR datatype is equal to the actual length of the entered string in bytes.
5. We should use CHAR datatype when we expect the data values in a column are of same length. We should use VARCHAR datatype when we expect the data values in a column are of variable length.
2. Middle Of Linked List
Easy
20m average time
80% success

0/40
Asked in companies

Given a singly linked list of 'N' nodes. The objective is to determine the middle node of a singly linked list. However, if the list has an even number of nodes, we return the second middle node.
Note:
1. If the list is empty, the function immediately returns None because there is no middle node to find.
2. If the list has only one node, then the only node in the list is trivially the middle node, and the function returns that node.
Problem approach
Traverse linked list using two pointers.
Move one pointer by one and the other pointers by two.
When the fast pointer reaches the end slow pointer will reach the middle of the linked list.
3. DBMS Question
Difference between Normalisation and De-Normalisation
Problem approach
1. In normalization, Non-redundancy and consistency data are stored in set schema. In denormalization, data are combined to execute the query quickly.
2. In normalization, Data redundancy and inconsistency is reduced. In denormalization, redundancy is added for quick execution of queries.
3. Data integrity is maintained in normalization. Data integrity is not maintained in denormalization.
4. In normalization, redundancy is reduced or eliminated. In denormalization redundancy is added instead of reduction or elimination of redundancy.
02
Round
Easy
Coding Test - Pen and paper
Duration90 minutes
Interview date22 May 2015
Coding problem1
This was a test round where there were multiple sections :
1 Puzzle
1 DSA based question
Complex sql query using 3-4 joins and sub-query in one single query
One query on co-related query
Some questions to find O/P of the program written in C like: operators, recursions, stack, queue.
1. K Largest Element
Moderate
10m average time
90% success
0/80
Asked in companies


You are given an unsorted array containing ‘N’ integers. You need to find ‘K’ largest elements from the given array. Also, you need to return the elements in non-decreasing order.
Problem approach
To solve the question using a max heap, make a max heap of all the elements of the list. Run a loop for k-1 times and remove the top element of the heap. After running the loop, the element at top will be the kth largest element, return that. Time Complexity : O(n + klogn)
The question can also be solved using a min heap.
Approach:
1. Create a min heap class with a capacity of k
2. When the heap reaches capacity eject the minimum number.
3. Loop over the array and add each number to the heap.
4. At the end, the largest k number of elements will be left in the heap, the smallest of them being at the top of the heap, which is the kth largest number
The time complexity for this solution is O(N logK).
03
Round
Easy
Face to Face
Duration60 minutes
Interview date22 May 2015
Coding problem1
This was the first technical Round. I was asked to explain how I solved puzzles of the written exam and how did I implement sql query of the written and asked me about Indexers.
Some Puzzles were also asked.
1. Convert A Given Number To Words
Easy
15m average time
80% success
0/40
Asked in companies
Given an integer number ‘num’. Your task is to convert ‘num’ into a word.
Suppose the given number ‘num’ is ‘9823’ then you have to return a string “nine thousand eight hundred twenty three” that is word conversion of the given ‘num’ 9823.
Problem approach
For numbers up-to 4 digits, the idea is to create arrays that store individual parts of output strings. One array is used for single digits, one for numbers from 10 to 19, one for 20, 30, 40, 50,.. etc, and one for powers of 10.
Next, keep dividing the number into different parts and append the corresponding word in the output string.
04
Round
Easy
Face to Face
Duration45 minutes
Interview date22 May 2015
Coding problem2
This was the second technical round.
I was asked some puzzles, and OOP concepts. Sql concepts like: where and having diff, some queries to write were also given. Some more Data Structure based questions were also asked.
1. Cycle Detection in a Singly Linked List
Moderate
15m average time
80% success
0/80
Asked in companies

You are given a Singly Linked List of integers. Return true if it has a cycle, else return false.
A cycle occurs when a node's next points back to a previous node in the list.
Example:
In the given linked list, there is a cycle, hence we return true.
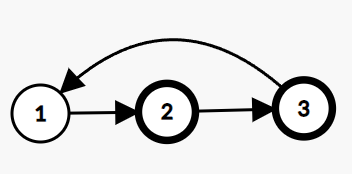
Problem approach
Floyd's algorithm can be used to solve this question.
Define two pointers slow and fast. Both point to the head node, fast is twice as fast as slow. There will be no cycle if it reaches the end. Otherwise, it will eventually catch up to the slow pointer somewhere in the cycle.
Let X be the distance from the first node to the node where the cycle begins, and let X+Y be the distance the slow pointer travels. To catch up, the fast pointer must travel 2X + 2Y. L is the cycle size. The total distance that the fast pointer has travelled over the slow pointer at the meeting point is what we call the full cycle.
X+Y+L = 2X+2Y
L=X+Y
Based on our calculation, slow pointer had already traveled one full cycle when it met fast pointer, and since it had originally travelled A before the cycle began, it had to travel A to reach the cycle's beginning!
After the two pointers meet, fast pointer can be made to point to head. And both slow and fast pointers are moved till they meet at a node. The node at which both the pointers meet is the beginning of the loop.
Pseudocode :
detectCycle(Node *head) {
Node *slow=head,*fast=head;
while(slow!=NULL && fast!=NULL && fast->next!=NULL) {
slow = slow->next;
fast = fast->next->next;
if(slow==fast)
{
fast = head;
while(slow!=fast)
{
slow = slow->next;
fast=fast->next;
}
return slow;
}
}
return NULL; }
2. OOPS Question
What is Polymorphism? What are its types in C++?
Problem approach
Polymorphism is defined as the ability to take more than one form. It is a feature that provides a function or an operator with more than one definition. It can be implemented using function overloading, operator overload, function overriding, virtual function.
Polymorphism is of two types :
1. Compile Time Polymorphism :
Invokes the overloaded functions by matching the number and type of arguments. The information is present during compile-time. This means the C++ compiler will select the right function at compile time. It is achieved through function overloading and operator overloading.
2. Run Time Polymorphism :
This happens when an object’s method is called during runtime rather than during compile time. Runtime polymorphism is achieved through function overriding. The function to be called is established during runtime.
05
Round
Medium
Face to Face
Duration60 minutes
Interview date22 May 2015
Coding problem0
This was the third technical round. Puzzles
I was asked to show the stack Trace of the question in written paper, that has recursive function and two function call to the same recursive function inside the recursive function. Website performance factors and Design Patterns were asked. Lastly, Data Structure based questions and the company organization Structure was discussed.
06
Round
Easy
HR Round
Duration30 minutes
Interview date22 May 2015
Coding problem1
Here, they asked how much we know about this organization like:naukri.com, 99acres.com, shiksha.com, jeevansathi.com,allcheckdeals.com,brij.com etc. He also discussed which vertical you are interested in joining
1. Basic HR Questions
Q1. Some examples of my leadership during my lifetime.
Q2. Some case studies where how I will act in difficult and stressed conditions.
Q3. Salary structure
Q4. Why do I want to join this organisation?
Problem approach
Tip 1 : Be sure to do your homework on the organization and its culture before the interview.
Tip 2 : Employers want to understand how you use your time and energy to stay productive and efficient. Be sure to emphasize that you adhere to deadlines and take them seriously.
Tip 3 : Talk about a relevant incident that made you keen on the profession you are pursuing and follow up by discussing your education.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
Selected 10308 views
0 comments
0 upvotes
Analytics Consultant
3 rounds | 10 problems
Interviewed by ZS
Selected 1135 views
0 comments
0 upvotes
SDE - Intern
1 rounds | 3 problems
Interviewed by Amazon
Selected 4015 views
0 comments
0 upvotes
SDE - 2
4 rounds | 6 problems
Interviewed by Expedia Group
 Selected
Selected 3128 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 116551 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 59304 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35700 views
7 comments
0 upvotes