


























Adobe interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Adobe
4 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Video Call
Duration60 Minutes
Interview date16 Jun 2021
Coding problem2
This round had 2 questions of DSA . Both the questions were from Linked Lists. I was first asked to explain my approach and then code up the both the problems.
1. Delete middle node
Easy
15m average time
95% success

0/40
Asked in companies

Given a singly linked list of 'N' nodes. Your task is to delete the middle node of this list and return the head of the modified list.
However, if the list has an even number of nodes, we delete the second middle node
Example:
If given linked list is 1->2->3->4 then it should be modified to 1->2->4.
Problem approach
Approach 1 :
1) Count the number of nodes in a linked list.
2) Delete n/2’th node using the simple deletion process.
TC : O(N) , N=number of nodes in the Linked List
Two traversals of the linked list is needed
SC : O(1)
Approach 2 :
1) The idea is to use two pointers, slow_ptr, and fast_ptr.
2) Both pointers start from the head of list. When fast_ptr reaches the end, slow_ptr reaches middle.
3) Keep track of the previous middle so the middle node can be deleted.
TC : O(N)
Single Traversal of the linked list is required
SC : O(1)
2. Merge Two Sorted Linked Lists
Moderate
15m average time
80% success
0/80
Asked in companies
You are given two sorted linked lists. You have to merge them to produce a combined sorted linked list. You need to return the head of the final linked list.
Note:
The given linked lists may or may not be null.
For example:
If the first list is: 1 -> 4 -> 5 -> NULL and the second list is: 2 -> 3 -> 5 -> NULL
The final list would be: 1 -> 2 -> 3 -> 4 -> 5 -> 5 -> NULL
Problem approach
Approach 1 (Recursive) :
1) Compare the head of both linked lists.
2) Find the smaller node among the two head nodes. The current element will be the smaller node among two head nodes.
3) The rest elements of both lists will appear after that.
4) Now run a recursive function with parameters, the next node of the smaller element, and the other head.
5) The recursive function will return the next smaller element linked with rest of the sorted element. Now point the next of current element to that, i.e curr_ele->next=recursivefunction()
6) Handle some corner cases.
6.1) If both the heads are NULL return null.
6.2) If one head is null return the other.
TC : O(N), where N=length of the Linked List
SC : O(N)
Approach 2 (Iterative) :
1) Traverse the list from start to end.
2) If the head node of second list lies in between two nodes of the first list, insert it there and make the next node of second list the head. Continue this until there is no node left in both lists, i.e. both the lists are traversed.
3) If the first list has reached end while traversing, point the next node to the head of second list.
Note: Compare both the lists where the list with a smaller head value is the first list.
TC : O(N), where N=length of the Linked List
SC : O(1)
02
Round
Medium
Video Call
Duration60 Minutes
Interview date16 Jun 2021
Coding problem3
This round had 2 coding questions , the first one was related to Sorting and the second one was related to Compilers and C++ in general to check endianess of the machine actually . After the coding questions, I was asked some concepts related to OOPS in general.
1. Sub Sort
Moderate
15m average time
85% success
0/80
Asked in companies
You are given an integer array ‘ARR’. You have to find the length of the shortest contiguous subarray such that, if you sort this subarray in ascending order, then the whole array will be sorted in ascending order.
An array 'C' is a subarray of array 'D' if it can be obtained by deletion of several elements(possibly zero) from the beginning and the end from array 'D'.
Example:
Let’s say we have an array 'ARR' {10, 12, 20, 30, 25, 40, 32, 31, 35, 50, 60}. Then we have to find the subarray {30 , 25 , 40 , 32 , 31 , 35} and print its length = 5 as our output. Because, when we sort this subarray the whole array will be sorted.
Problem approach
Approach 1 (Brute Force) :
In this approach, we make use of an idea based on selection sort.
1) Traverse over the given numsnums array choosing the elements nums[i]. For every such element chosen, we try to determine its correct position in the sorted array. For this, we compare nums[i] with every nums[j], such that i < j < n.
2) If any nums[j] is lesser than nums[i], it means both nums[i] and nums[j] aren't at their correct position for the sorted array. Thus, we need to swap the two elements to bring them at their correct positions.
3) Instead of swapping, just note the position of nums[i] (given by i) and nums[j] (given by j). These two elements now mark the boundary of the unsorted subarray(atleast for the time being).
4) Out of all the nums[i] chosen, we determine the leftmost nums[i] which isn't at its correct position. This marks the left boundary of the smallest unsorted subarray(l).
5) Similarly, Out of all the nums[j] considered for all nums[i] we determine the rightmost nums[j] which isn't at its correct position. This marks the right boundary of the smallest unsorted subarray(r).
6) Therefore, the length of the smallest unsorted subarray = r−l+1.
TC : O(N^2)
SC : O(1)
Approach 2 (Using Sorting) :
1) We can sort a copy of the given array nums, say given by nums_sorted.
2) Then, if we compare the elements of nums and nums_sorted, we can determine the leftmost and rightmost elements which mismatch.
3) The subarray lying between them is, then, the required shorted unsorted subarray.
TC : O(N*log(N))
SC : O(N)
2. Swap Adjacent Bit Pairs
Easy
10m average time
90% success
0/40
Asked in companies
You are given an integer 'N'. Your task is to find the number formed after swapping each even bit of 'N' in its binary representation with its adjacent bit on the right, assuming that the least significant bit is an odd bit.
For example :
Consider the integer N = 45 whose binary representation is 101101. The resulting number formed after swapping each even bit with its adjacent bit to the right will be 30 (011110) in this case.
Problem approach
The idea is to first separate all the bits that are present at the odd positions and the even positions. After separating the bits at even and odd positions, we can swap them by right shifting the number formed by taking bits at even position by 1 bit and left shifting the number formed by taking bits at the odd position by 1 bit. So, our final result will be the Bitwise OR of the two values. To get the bits at the odd position, we will need to toggle all the bits at even position in the binary representation of N off, while keeping the bits at odd positions unchanged, to do so, we will take the Bitwise AND of N with the binary number of the form of 01010101… As taking the Bitwise AND will make all even bits 0 while the odd bits will remain the same. As the number of bits in our input is at most 32, so will take the number 01..(repeated16 times), which can be represented as 0x55555555 in hexadecimal form. Similarly, to get the bits at even positions, we will take Bitwise AND of N with 0xAAAAAAAA.
Steps:
- Let oddPositionBits and evenPositionBits be the two variables that store the value of bits at odd positions and even positions respectively.
- Set oddPositionBits as the Bitwise AND of N and 0x55555555.
- Set evenPositionBits as the Bitwise AND of N and 0xAAAAAAAA.
- Left shift oddPositionBits by 1 bit and right shift evenPositionBits by 1 bit. In this step, we are swapping the positions of the odd bits and the even bits.
- Let ans be the variable that stores the final result. Set ans as the Bitwise OR of oddPositionBits and evenPositionBits. Here, we are recombining the od bits and the even bits after swapping them.
- Return the variable ans.
3. OOPS Question
What are Virtual Destructors in C++?
Problem approach
Answer :
Destructor : A destructor in C++ is a member function of a class used to free the space occupied by or delete an object of the class that goes out of scope. A destructor has the same name as the name of the constructor function in a class, but the destructor uses a tilde (~) sign before its function name.
Virtual Destructor : A virtual destructor is used to free up the memory space allocated by the derived class object or instance while deleting instances of the derived class using a base class pointer object. A base or parent class destructor use the virtual keyword that ensures both base class and the derived class destructor will be called at run time, but it called the derived class first and then base class to release the space occupied by both destructors.
03
Round
Medium
Video Call
Duration50 Minutes
Interview date16 Jun 2021
Coding problem2
Standard DS/Algo round with 2 questions . First I explained my approach and then we discussed some Edge Cases along with proper Complexity Analysis.
1. Search In Rotated Sorted Array
Moderate
30m average time
65% success
0/80
Asked in companies

Aahad and Harshit always have fun by solving problems. Harshit took a sorted array consisting of distinct integers and rotated it clockwise by an unknown amount. For example, he took a sorted array = [1, 2, 3, 4, 5] and if he rotates it by 2, then the array becomes: [4, 5, 1, 2, 3].
After rotating a sorted array, Aahad needs to answer Q queries asked by Harshit, each of them is described by one integer Q[i]. which Harshit wanted him to search in the array. For each query, if he found it, he had to shout the index of the number, otherwise, he had to shout -1.
For each query, you have to complete the given method where 'key' denotes Q[i]. If the key exists in the array, return the index of the 'key', otherwise, return -1.
Note:
Can you solve each query in O(logN) ?
Problem approach
Approach :
1) We initialise two integer variables ‘si’ and ‘ei’ denoting the start index and the end index to 0 and N -1, respectively.
2) We also initialise another integer variable ‘pivot’ to 0 that stores the index of the pivot element.
3) In the modified binary search, we will compare ARR[mid] with ARR[0] because if ARR[mid] < ARR[0], then it is guaranteed that ‘pivot’ is mid or present on its left side. Else, ‘pivot’ is present on the right side.
4) The modified binary search to find the pivot point:
4.1) We find the index of the middle element of ARR as mid = si + (ei - si) /2 .
4.2) If (ARR[mid] < ARR[0])
i) pivot = mid
ii) We update the end index ei, ei = mid - 1.
4.3) Else
i) We update the start index si, si = mid + 1.
5) After finding the pivot, we can easily locate the two sorted parts of ARR, one starting from 0 to pivot - 1 and the other from pivot to N - 1.
6) Now, we apply binary search in that sorted part of ARR in which the element K may lie. If K is present, we return its index. Else, we return -1.
TC : O(log(N)), where N=size of the array
SC : O(1)
2. Quick Sort
Moderate
10m average time
90% success
0/80
Asked in companies
You are given an array of integers. You need to sort the array in ascending order using quick sort.
Quick sort is a divide and conquer algorithm in which we choose a pivot point and partition the array into two parts i.e, left and right. The left part contains the numbers smaller than the pivot element and the right part contains the numbers larger than the pivot element. Then we recursively sort the left and right parts of the array.
Example:
Let the array = [ 4, 2, 1, 5, 3 ]
Let pivot to be the rightmost number.
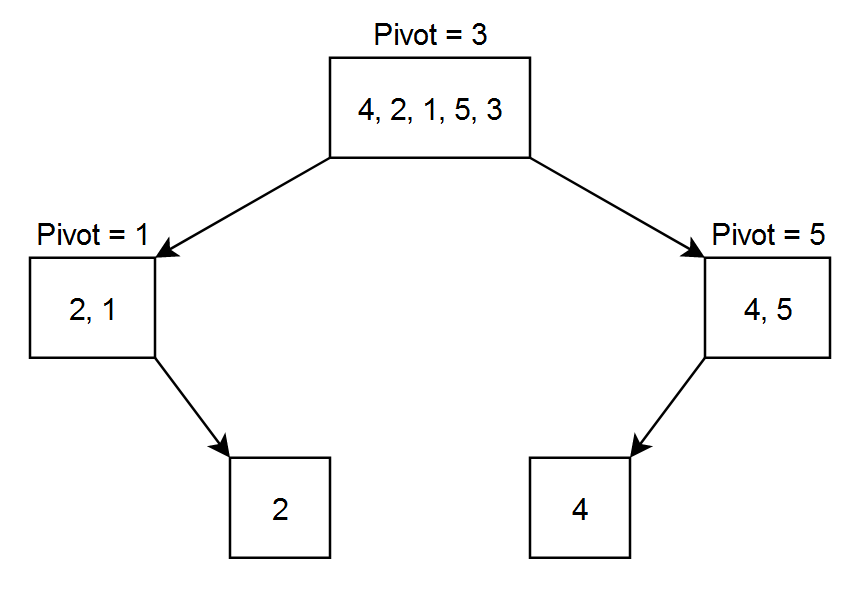
After the 1st level partitioning the array will be { 2, 1, 3, 4, 5 } as 3 was the pivot. After 2nd level partitioning the array will be { 1, 2, 3, 4, 5 } as 1 was the pivot for the left part and 5 was the pivot for the right part. Now our array is sorted and there is no need to divide it again.
Problem approach
Approach :
1) Select any splitting value, say L. The splitting value is also known as Pivot.
2) Divide the stack of papers into two. A-L and M-Z. It is not necessary that the piles should be equal.
3) Repeat the above two steps with the A-L pile, splitting it into its significant two halves. And M-Z pile, split into its halves. The process is repeated until the piles are small enough to be sorted easily.
4) Ultimately, the smaller piles can be placed one on top of the other to produce a fully sorted and ordered set of papers.
5) The approach used here is reduction at each split to get to the single-element array.
6) At every split, the pile was divided and then the same approach was used for the smaller piles by using the method of recursion.
Technically, quick sort follows the below steps:
Step 1 − Make any element as pivot
Step 2 − Partition the array on the basis of pivot
Step 3 − Apply quick sort on left partition recursively
Step 4 − Apply quick sort on right partition recursively
//Pseudo Code :
quickSort(arr[], low, high)
{
if (low < high)
{
pivot_index = partition(arr, low, high);
quickSort(arr, low, pivot_index - 1); // Before pivot_index
quickSort(arr, pivot_index + 1, high); // After pivot_index
}
}
partition (arr[], low, high)
{
// pivot - Element at right most position
pivot = arr[high];
i = (low - 1);
for (j = low; j <= high-1; j++)
{
if (arr[j] < pivot)
{
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (i + 1);
}
Complexity Analysis :
TC : Best Case - O(N*log(N))
Worst Case - O(N^2)
SC : Average Case - O(log(N))
Worst Case - O(N)
04
Round
Medium
Video Call
Duration60 minutes
Interview date16 Jun 2021
Coding problem4
This round went for about 50-60 minutes where I had to code two questions related to DSA after discussing their approaches and time and space complexities and then I was asked some questions revolving around OOPS and OS . The interviewer was quite freindly and helped me at some places where I was facing some difficulties.
1. LCA In A BST
Moderate
15m average time
85% success
0/80
Asked in companies
You are given a binary search tree of integers with N nodes. You are also given references to two nodes 'P' and 'Q' from this BST.
Your task is to find the lowest common ancestor(LCA) of these two given nodes.
The lowest common ancestor for two nodes P and Q is defined as the lowest node that has both P and Q as descendants (where we allow a node to be a descendant of itself)
A binary search tree (BST) is a binary tree data structure which has the following properties.
• The left subtree of a node contains only nodes with data less than the node’s data.
• The right subtree of a node contains only nodes with data greater than the node’s data.
• Both the left and right subtrees must also be binary search trees.
For example:
'P' = 1, 'Q' = 3
tree = 2 1 4 -1 -1 3 -1 -1 -1,
The BST corresponding will be-
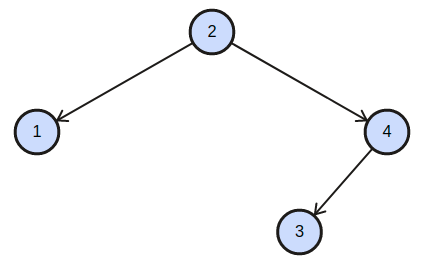
Here, we can clearly see that LCA of node 1 and node 3 is 2.
Problem approach
Steps :
1) Create a recursive function that takes a node and the two values n1 and n2.
2) If the value of the current node is less than both n1 and n2, then LCA lies in the right subtree. Call the recursive function for the right subtree.
3) If the value of the current node is greater than both n1 and n2, then LCA lies in the left subtree. Call the recursive function for the left subtree.
4) If both the above cases are false then return the current node as LCA.
TC : O(h), where h=Height of the BST
SC : O(h)
2. Spiral Matrix
Easy
0/40
Asked in companies

You are given a N x M matrix of integers, return the spiral path of the matrix
Example Of Spiral Path

Problem approach
Algorithm:
spiralPrint(matrix[][], rows, cols):
1) Initialize two variables ‘R’, ‘C’ with 0 to denote the lowest boundary for row and column of the submatrix remaining. Also, rows and cols denote the maximum boundary for the submatrix remaining.
2) While(R < rows and C < cols) :
2.1) Print the first row from left to right of the remaining submatrix i.e from column ‘C’ to ‘cols’, print the
elements of the Rth row. Increment ‘R’ by 1.
2.2) Print the last column from top to bottom of the remaining submatrix i.e from row ‘R’ to ‘rows’, print
the elements of the (cols)th column. Decrement ‘cols’ by 1.
2.3) Print the last row from right to left of the remaining submatrix i.e from column ‘cols’ to ‘C’, print the
elements of the (rows)th row. Decrement ‘rows’ by 1.
2.4) Print the first column from bottom to top of the remaining submatrix i.e from row ‘rows’ to ‘R’, print
the elements of the Cth column. Increment ‘C’ by 1.
TC : O(N*M), where ‘N’ is the number of rows and ‘M’ is the number of columns of the matrix.
SC : O(1)
3. OOPS Question
What is Diamond Problem in C++ and how do we fix it?
Problem approach
Answer :
The Diamond Problem : The Diamond Problem occurs when a child class inherits from two parent classes who both share a common grandparent class i.e., when two superclasses of a class have a common base class.
Solving the Diamond Problem in C++ : The solution to the diamond problem is to use the virtual keyword. We make the two parent classes (who inherit from the same grandparent class) into virtual classes in order to avoid two copies of the grandparent class in the child class.
4. OS Question
What are the different types of semaphores ?
Problem approach
Answer :
There are two main types of semaphores i.e. counting semaphores and binary semaphores.
1) Counting Semaphores :
These are integer value semaphores and have an unrestricted value domain. These semaphores are used to coordinate the resource access, where the semaphore count is the number of available resources. If the resources are added, semaphore count automatically incremented and if the resources are removed, the count is decremented.
2) Binary Semaphores :
The binary semaphores are like counting semaphores but their value is restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0. It is sometimes easier to implement binary semaphores than counting semaphores.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 5 problems
Interviewed by Adobe
 Selected
Selected 3190 views
0 comments
0 upvotes
SDE - 1
4 rounds | 10 problems
Interviewed by Adobe
Selected 1198 views
0 comments
0 upvotes
SDE - 1
5 rounds | 8 problems
Interviewed by Adobe
Selected 1400 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Adobe
Selected 3464 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 115097 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35147 views
7 comments
0 upvotes