


























Adobe interview experience Real time questions & tips from candidates to crack your interview
Member of Technical Staff
Adobe
3 rounds | 10 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Interview
Duration120 Minutes
Interview date13 Mar 2015
Coding problem2
This was an online Coding+MCQ round. Both the coding questions were related to DP and were of Medium to Hard Difficulty.The MCQ's were of easy-medium level but one has to be fast in order to complete the section in the given time frame.
1. Maximum Sum
Moderate
35m average time
70% success

0/80
Asked in companies

You are given an array “ARR” of N integers. You are required to perform an operation on the array each time until it becomes empty. The operation is to select an element from the array(let’s say at ith index i.e ARR[i]) and remove one occurrence of the selected element from the array and remove all the occurrences of (ARR[i]-1) and (ARR[i]+1) from the array(if present). Your task is to maximize the sum of selected elements from the array.
For example, let’s say the given array is [2, 3, 3, 3, 4, 5].
The maximum possible sum for the given array would be 14. Because if we select one of the 3’s from the array, then one 3 and all occurrences of (3-1) and (3+1) i.e 2 and 4 will be deleted from the array. Now we left with {3,3,5} elements in the array. Then again we select 3 in the next two steps and in both steps 3 will be deleted also (3-1) and (3+1) doesn't exist in the array so nothing extra to delete in both steps. Now we left with only {5} and in the next step, we select the 5 and delete it. Then the array becomes empty. Thus the sum of selected elements will be 3+3+3+5 = 14.
Problem approach
Algorithm:
1) Find the maximum number max in the array.
2) Create a new auxiliary array dp of size max+1 and store frequencies of unique elements in the array, where dp[i] denotes the number of times i as an element is present in the input array.
3) Iterate the dp array(we will use this array to store the results), now for each index i from 2 to MAX we have two choices: dp[i] = max(dp[i-1], dp[i-2] + dp[i]*i).
4) Return dp[MAX], which have the maximum sum of the selected numbers.
TC : O(max(MAX, N)), where “MAX” is the maximum element and N is the size of the array.
SC : O(MAX)
2. Longest Common Prime Subsequence
Moderate
0/80
Asked in companies


Ninja got a very long summer vacation. Being very bored and tired about it, he indulges himself in solving some puzzles.
He encountered a problem in which he was given two arrays of integers of length ‘N’ and ‘M’ respectively and he had to find the longest common prime subsequence.
Ninja wants help in solving the problem as he is not getting the approach so he approaches you as he knows that you are very good at building logics. Help Ninja!
Note:
A subsequence is a sequence that can be derived from another sequence by zero or more elements, without changing the order of the remaining elements.
Problem approach
Algorithm :
1) Generate all the prime numbers in the range of values of the given array using Sieve Of Eratosthenes.
2) Now make an iteration for ‘arr1’ and check the elements in ‘arr1’ which are prime and store the elements in an array, say ‘finalA’.
3) Now make an iteration for ‘arr2’ and check the elements in ‘arr2’ which are prime and store the elements in an array, say ‘finalB’.
4) Now calculate the LCS for the two arrays: ‘finalA’ and ‘finalB’ with the help of ‘lcs()’ function using Dynamic Programming.
5) Return the array after calculating the longest common subsequence.
TC : O(N*M) , where N=size of array 1 and M=size of array 2
SC : O(N*M)
02
Round
Medium
Face to Face
Duration60 Minutes
Interview date14 Mar 2015
Coding problem4
This round had 2 Algorithmic questions wherein I was supposed to code both the problems after discussing their approaches and respective time and space complexities . After that , I was grilled on some OOPS concepts related to C++.
1. Detect and Remove Loop
Moderate
10m average time
90% success
0/80
Asked in companies
Given a singly linked list, you have to detect the loop and remove the loop from the linked list, if present. You have to make changes in the given linked list itself and return the updated linked list.
Expected Complexity: Try doing it in O(n) time complexity and O(1) space complexity. Here, n is the number of nodes in the linked list.
Problem approach
Approach 1(Using Hashing) :
We are going to maintain a lookup table(a Hashmap) that basically tells if we have already visited a node or not, during the course of traversal.
Steps :
1) Visit every node one by one, until null is not reached.
2) Check if the current node is present in the loop up table, if present then there is a cycle and will return
true, otherwise, put the node reference into the lookup table and repeat the process.
3) If we reach at the end of the list or null, then we can come out of the process or loop and finally, we can
say the loop doesn't exist.
TC : O(N), where N is the total number of nodes.
SC : O(N)
Approach 2 (Using Slow and Fast Pointers) :
Steps :
1) The idea is to have 2 pointers: slow and fast. Slow pointer takes a single jump and corresponding to
every jump slow pointer takes, fast pointer takes 2 jumps. If there exists a cycle, both slow and fast
pointers will reach the exact same node. If there is no cycle in the given linked list, then fast pointer will
reach the end of the linked list well before the slow pointer reaches the end or null.
2) Initialize slow and fast at the beginning.
3) Start moving slow to every next node and moving fast 2 jumps, while making sure that fast and its next
is not null.
4) If after adjusting slow and fast, if they are referring to the same node, there is a cycle otherwise repeat
the process
5) If fast reaches the end or null then the execution stops and we can conclude that no cycle exists.
TC : O(N), where N is the total number of nodes.
SC : O(1)
2. Stack using queue
Moderate
25m average time
65% success
0/80
Asked in companies

Implement a Stack Data Structure specifically to store integer data using two Queues.
There should be two data members, both being Queues to store the data internally. You may use the inbuilt Queue.
Implement the following public functions :
1. Constructor:
It initializes the data members(queues) as required.
2. push(data) :
This function should take one argument of type integer. It pushes the element into the stack and returns nothing.
3. pop() :
It pops the element from the top of the stack and, in turn, returns the element being popped or deleted. In case the stack is empty, it returns -1.
4. top :
It returns the element being kept at the top of the stack. In case the stack is empty, it returns -1.
5. size() :
It returns the size of the stack at any given instance of time.
6. isEmpty() :
It returns a boolean value indicating whether the stack is empty or not.
Operations Performed on the Stack:
Query-1(Denoted by an integer 1): Pushes an integer data to the stack. (push function)
Query-2(Denoted by an integer 2): Pops the data kept at the top of the stack and returns it to the caller. (pop function)
Query-3(Denoted by an integer 3): Fetches and returns the data being kept at the top of the stack but doesn't remove it, unlike the pop function. (top function)
Query-4(Denoted by an integer 4): Returns the current size of the stack. (size function)
Query-5(Denoted by an integer 5): Returns a boolean value denoting whether the stack is empty or not. (isEmpty function)
Example
Operations:
1 5
1 10
2
3
4
Enqueue operation 1 5: We insert 5 at the back of the queue.
Queue: [5]
Enqueue operation 1 10: We insert 10 at the back of the queue.
Queue: [5, 10]
Dequeue operation 2: We remove the element from the front of the queue, which is 5, and print it.
Output: 5
Queue: [10]
Peek operation 3: We return the element present at the front of the queue, which is 10, without removing it.
Output: 10
Queue: [10]
IsEmpty operation 4: We check if the queue is empty.
Output: False
Queue: [10]
Problem approach
Approach : A stack can be implemented using two queues. Let stack to be implemented be ‘s’ and queues used to implement be ‘q1’ and ‘q2’. Stack ‘s’ can be implemented in two ways :
Method 1 (push - O(1) , pop - O(n) ) :
1) push(s, x) operation :
i) Enqueue x to q1 (assuming size of q1 is unlimited).
2) pop(s) operation :
i) One by one dequeue everything except the last element from q1 and enqueue to q2.
ii) Dequeue the last item of q1, the dequeued item is result, store it.
iii) Swap the names of q1 and q2
iv) Return the item stored in step 2.
TC : push(s,x) -> O(1)
pop() -> O(n)
Method 2 (push - O(n) , pop - O(1) ) :
1) push(s, x) operation :
i) Enqueue x to q2
ii) One by one dequeue everything from q1 and enqueue to q2.
iii) Swap the names of q1 and q2
2) pop(s) operation :
i) Dequeue an item from q1 and return it.
TC : push(s,x) -> O(n)
pop() -> O(1)
3. OOPS Question
What is Vtable and VPTR in C++?
Problem approach
Answer :
Vtable : It is a table that contains the memory addresses of all virtual functions of a class in the order in which they are declared in a class. This table is used to resolve function calls in dynamic/late binding manner. Every class that has virtual function will get its own Vtable.
VPTR : After creating Vtable address of that table gets stored inside a pointer i.e. VPTR (Virtual Pointer). When you create an object of a class which contains virtual function then a hidden pointer gets created automatically in that object by the compiler. That pointer points to a virtual table of that particular class.
Some important points about Vtable and VPTR are as follows :
1) Vtable is created by compiler at compile time.
2) VPTR is a hidden pointer created by compiler implicitly.
3) If base class pointer pointing to a function which is not available in base class then it will generate error over there.
4) Memory of Vtable and VPTR gets allocated inside the process address space.
5) Vtable gets created for each class which has virtual functions.
6) To achieve run time polymorphism effect there should be single level inheritance in our code.
4. OOPS Question
What Friend Functions in C++?
Problem approach
Answer :
1) Friend functions of the class are granted permission to access private and protected members of the class in C++. They are defined globally outside the class scope. Friend functions are not member functions of the class.
2) A friend function is a function that is declared outside a class but is capable of accessing the private and protected members of the class.
3) There could be situations in programming wherein we want two classes to share their members. These members may be data members, class functions or function templates. In such cases, we make the desired function, a friend to both these classes which will allow accessing private and protected data members of the class.
4) Generally, non-member functions cannot access the private members of a particular class. Once declared as a friend function, the function is able to access the private and the protected members of these classes.
Some Characteristics of Friend Function in C++ :
1) The function is not in the ‘scope’ of the class to which it has been declared a friend.
2) Friend functionality is not restricted to only one class
3) Friend functions can be a member of a class or a function that is declared outside the scope of class.
4) It cannot be invoked using the object as it is not in the scope of that class.
5) We can invoke it like any normal function of the class.
6) Friend functions have objects as arguments.
7) It cannot access the member names directly and has to use dot membership operator and use an object name with the member name.
8) We can declare it either in the ‘public’ or the ‘private’ part.
03
Round
Medium
Face to Face
Duration60 minutes
Interview date14 Mar 2015
Coding problem4
This round had 3 preety good questions related to DSA and some questions revolving around Memory Management and Operating Systems.
1. Predecessor and Successor In BST
Easy
10m average time
90% success
0/40
Asked in companies

You have been given a binary search tree of integers with ‘N’ nodes. You are also given 'KEY' which represents data of a node of this tree.
Your task is to return the predecessor and successor of the given node in the BST.
Note:
1. The predecessor of a node in BST is that node that will be visited just before the given node in the inorder traversal of the tree. If the given node is visited first in the inorder traversal, then its predecessor is NULL.
2. The successor of a node in BST is that node that will be visited immediately after the given node in the inorder traversal of the tree. If the given node is visited last in the inorder traversal, then its successor is NULL.
3. The node for which the predecessor and successor will not always be present. If not present, you can hypothetically assume it's position (Given that it is a BST) and accordingly find out the predecessor and successor.
4. A binary search tree (BST) is a binary tree data structure which has the following properties.
• The left subtree of a node contains only nodes with data less than the node’s data.
• The right subtree of a node contains only nodes with data greater than the node’s data.
• Both the left and right subtrees must also be binary search trees.
Problem approach
Approach (Using Inorder Traversal) :
1) Maintain two variables ‘PRE’ and ‘SUC’ which point to the predecessor and successor respectively.
2) We use a helper function ‘FIND_PRE_SUC_HELP’, which take the following as parameter :
‘ROOT’ , ‘PRE’ , ‘SUC’ , ‘KEY’ i.e. ‘X’.
3) If the current node's data is equal to ‘KEY’ then :
3.1) The maximum value in the left subtree is the predecessor.
3.2) The minimum value in the right subtree is the successor.
4) If after exiting ‘FIND_PRE_SUC_HELP’ any of ‘PRE’ or ‘SUC’ are NULL then that value was not found
then add -1 to the vector.
5) Else add the value pointed by ‘PRE’ and then ‘SUC’.
TC : O(N), where ‘N’ is the number of nodes in the given tree.
SC : O(N)
2. Count Ways To Reach The N-th Stairs
Moderate
30m average time
80% success
0/80
Asked in companies

You have been given a number of stairs. Initially, you are at the 0th stair, and you need to reach the Nth stair.
Each time, you can climb either one step or two steps.
You are supposed to return the number of distinct ways you can climb from the 0th step to the Nth step.
Note:
Note: Since the number of ways can be very large, return the answer modulo 1000000007.
Example :
N=3
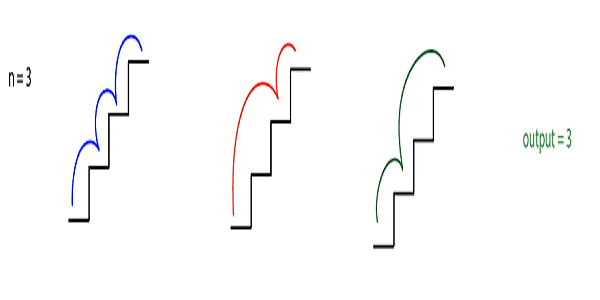
We can climb one step at a time i.e. {(0, 1) ,(1, 2),(2,3)} or we can climb the first two-step and then one step i.e. {(0,2),(1, 3)} or we can climb first one step and then two step i.e. {(0,1), (1,3)}.
Problem approach
Approach (Using DP) :
1) We reach “currStep” step in taking one step or two steps:
1.1) We can take the one-step from (currStep-1)th step or,
1.2) We can take the two steps from (currStep-2)th step.
2) So the total number of ways to reach “currStep” will be the sum of the total number of ways to reach at (currStep-1)th and the total number of ways to reach (currStep-2)th step.
3) Let dp[currStep] define the total number of ways to reach “currStep” from the 0th. So,
dp[ currStep ] = dp[ currStep-1 ] + dp[ currStep-2 ]
4) The base case will be, If we have 0 stairs to climb then the number of distinct ways to climb will be one
(we are already at Nth stair that’s the way) and if we have only one stair to climb then the number of
distinct ways to climb will be one, i.e. one step from the beginning.
TC : O(N), Where ‘N’ is the number of stairs.
SC : O(N)
3. Good Arrays
Moderate
20m average time
85% success
0/80
Asked in companies

You are given an array ‘A’ of length ‘N’, you have to choose an element from any index in this array and delete it. After deleting the element you will get a new array of length ‘N’-1. Your task is to find the number of such arrays of length ‘N’-1 which are good.
Note :
An array is called good if the sum of elements in odd indexes is equal to the sum of elements in even indexes.
For Example :
In array A= [1 2 4 3 6], if we delete A[4]=6, we will get new array B= [1 2 4 3], where B[0] + B[2] = B[1] + B[3] = 5, which means array B is good.
Problem approach
Algorithm :
1) Create a variable ‘res’ =0, which will store the number of good arrays that can be formed.
2) Create four variables ‘oddRightSum’ = 0, ‘evenRightSum’ = 0, ‘oddLeftSum’ = 0, ‘evenLeftSum’ = 0;
3) Iterate over all index ‘i’ in array ‘A:
3.1) If ‘i’ is even, then add the current element to ‘evenRightSum’
3.2) If ‘i’ is odd, then add the current element to ‘oddRightSum’
4) Iterate over all index ‘i’ in array ‘A:
4.1) If ‘i’ is odd, then decrease ‘oddRightSum’ by the current element.
4.2) If ‘i’ is even, then decrease ‘evenRightSum’ by the current element.
4.3) If ‘leftEvenSum’ + ’rightOddSum’ == ‘leftOddSum’ + ‘rightEvenSum’., then increment ‘res’, as we
have found one good array.
4.4) If ‘i’ is odd, then increase ‘oddRightSum’ by the current element.
4.5) If ‘i’ is even, then increase ‘evenRightSum’ by the current element.
5) Return ‘res’ variable.
TC : O( N ), where N=size of the array
SC : O(1)
4. OS Question
What is Memory Protection in OS ?
Problem approach
Answer :
1) Memory protection is a strategy that makes it possible to manage the amount of access rights that are granted to the memory found on a computer hard drive.
2) The main purpose of this type of protection is to minimize the potential for some type of storage violation that would harm the data contained in the memory, or damage a portion of the memory capacity of the hard drive.
3) One of the main functions of memory protection is the prevention of any application from making use of memory that the operating system has not specifically allocated to that application.
4) This prevents applications from seizing control of an inordinate amount of memory and possibly causing damage that negatively impacts other applications that are currently in use, or even creating a loss of data that is saved on the hard drive.
5) In many operating systems, this is managed by segmenting the memory for use by all open applications, ensuring that each has enough to operate properly without creating issues with the other running applications.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - Intern
1 rounds | 7 problems
Interviewed by Adobe
Selected 1600 views
0 comments
0 upvotes
SDE - Intern
2 rounds | 4 problems
Interviewed by Adobe

Rejected
966 views
0 comments
0 upvotes
SDE - Intern
2 rounds | 2 problems
Interviewed by Adobe

Rejected
1084 views
0 comments
0 upvotes
Product Intern
2 rounds | 7 problems
Interviewed by Adobe
Selected 926 views
0 comments
0 upvotes
Companies with similar interview experiences
Member of Technical Staff
4 rounds | 13 problems
Interviewed by Oracle
 Selected
Selected 5397 views
0 comments
0 upvotes
Member of Technical Staff
2 rounds | 5 problems
Interviewed by Oracle
Rejected
1603 views
0 comments
0 upvotes
Member of Technical Staff
3 rounds | 5 problems
Interviewed by Oracle
Selected 1997 views
0 comments
0 upvotes