


























Amazon interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Amazon
5 rounds | 13 Coding
problems
Rejected
Interview preparation journey

Preparation
Duration: 2.5 months
Topics: DSA, DBMS, OS, System design, Projects, Dynamic programming, Trees.
Tip 1 : Understand the logic behind each solution properly. Don’t memorize it.
Tip 2 : Practice more
Tip 3 : Practice explanation skills
Application process
Where: Linkedin
Eligibility: 1.5+ YOE
Tip 1 : Be concise and to the point
Tip 2 : Presentable

Interview rounds
01
Round
Medium
Online Coding Interview
Duration60 minutes
Interview date7 Jan 2022
Coding problem2
( HackerEarth platform) - two questions were there. I solved 1 out of them. One was easy-medium (dfs, bfs based) and the second was the array based question.
It had a time slot of 2 days, I could give any time in that 2 days.
1. Shortest Path in an Unweighted Graph
Moderate
25m average time
70% success

0/80
Asked in companies
The city of Ninjaland is analogous to the unweighted graph. The city has ‘N’ houses numbered from 1 to ‘N’ respectively and are connected by M bidirectional roads. If a road is connecting two houses ‘X’ and ‘Y’ which means you can go from ‘X’ to ‘Y’ or ‘Y’ to ‘X’. It is guaranteed that you can reach any house from any other house via some combination of roads. Two houses are directly connected by at max one road.
A path between house ‘S’ to house ‘T’ is defined as a sequence of vertices from ‘S’ to ‘T’. Where starting house is ‘S’ and the ending house is ‘T’ and there is a road connecting two consecutive houses. Basically, the path looks like this: (S , h1 , h2 , h3 , ... T). you have to find the shortest path from ‘S’ to ‘T’.
For example
In the below map of Ninjaland let say you want to go from S=1 to T=8, the shortest path is (1, 3, 8). You can also go from S=1 to T=8 via (1, 2, 5, 8) or (1, 4, 6, 7, 8) but these paths are not shortest.
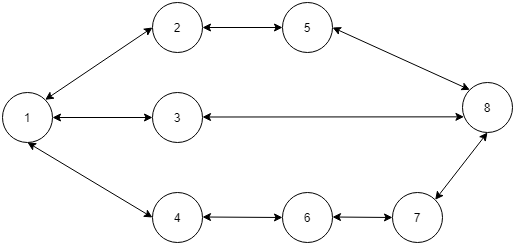
Problem approach
One solution is to solve in O(VE) time using Bellman–Ford. If there are no negative weight cycles, then we can solve in O(E + VLogV) time using Dijkstra’s algorithm.
Since the graph is unweighted, we can solve this problem in O(V + E) time. The idea is to use a modified version of Breadth-first search in which we keep storing the predecessor of a given vertex while doing the breadth-first search.
We first initialize an array dist[0, 1, …., v-1] such that dist[i] stores the distance of vertex i from the source vertex and array pred[0, 1, ….., v-1] such that pred[i] represents the immediate predecessor of the vertex i in the breadth-first search starting from the source.
Now we get the length of the path from source to any other vertex in O(1) time from array d, and for printing the path from source to any vertex we can use array p and that will take O(V) time in worst case as V is the size of array P. So most of the time of the algorithm is spent in doing the Breadth-first search from a given source which we know takes O(V+E) time. Thus the time complexity of our algorithm is O(V+E).
2. Two Sum
Easy
10m average time
90% success
0/40
Asked in companies

You are given an array of integers 'ARR' of length 'N' and an integer Target. Your task is to return all pairs of elements such that they add up to Target.
Note:
We cannot use the element at a given index twice.
Follow Up:
Try to do this problem in O(N) time complexity.
02
Round
Medium
Video Call
Duration60 minutes
Interview date17 Jan 2022
Coding problem2
It was problem solving round only
it happened at 5 pm
1. Construct Binary Tree From Inorder and Preorder Traversal
Easy
10m average time
90% success
0/40
Asked in companies
You have been given the preorder and inorder traversal of a binary tree. Your task is to construct a binary tree using the given inorder and preorder traversals.
Note:
You may assume that duplicates do not exist in the given traversals.
For example :
For the preorder sequence = [1, 2, 4, 7, 3] and the inorder sequence = [4, 2, 7, 1, 3], we get the following binary tree.
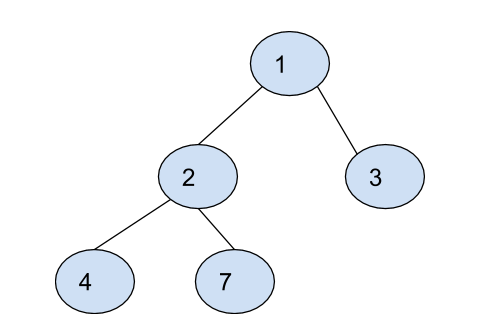
2. Populating Next Right Pointers in Each Node
Moderate
25m average time
75% success
0/80
Asked in companies
You have been given a complete binary tree of ‘N’ nodes. The nodes are numbered 1 to ‘N’.
You need to find the ‘next’ node that is immediately right in the level order form for each node in the given tree.
Note :
1. A complete binary tree is a binary tree in which nodes at all levels except the last level have two children and nodes at the last level have 0 children.
2. Node ‘U’ is said to be the next node of ‘V’ if and only if ‘U’ is just next to ‘V’ in tree representation.
3. Particularly root node and rightmost nodes have ‘next’ node equal to ‘Null’
4. Each node of the binary tree has three-pointers, ‘left’, ‘right’, and ‘next’. Here ‘left’ and ‘right’ are the children of node and ‘next’ is one extra pointer that we need to update.
For Example :
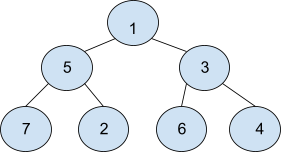
The‘next’ node for ‘1’ is ‘Null’, ‘2’ has ‘next’ node ‘6’, ‘5’ has ‘next’ node ‘3’, For the rest of the nodes check below.
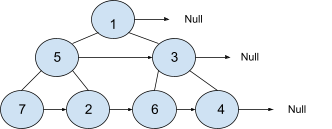
03
Round
Easy
Video Call
Duration60 minutes
Interview date18 Jan 2022
Coding problem3
It was DS + projects
The interviewer was Dev's manager. Didn't ask me to write full code. Just pseudo code.
And full code for heapify function.
1. K Most Frequent Words
Moderate
36m average time
65% success
0/80
Asked in companies
You have been given an array/list 'WORDS' of 'N' non-empty words, and an integer 'K'. Your task is to return the 'K' most frequent words sorted by their frequency from highest to lowest.
Note:
If two words have the same frequency then the lexicographically smallest word should come first in your answer.
Follow up:
Can you solve it in O(N * logK) time and O(N) extra space?
2. Technical Question
What if the data size is too large and can not store in memory, ie. stored in a file and you are getting input as a stream. Given approach like dividing the file into smaller parts ( multi hashmap + heap)
3. Technical Question
10 mins discussion about current work .
04
Round
Medium
Video Call
Duration65 minutes
Interview date21 Jan 2022
Coding problem2
It was core problem solving and coding
1. Longest Consecutive Sequence
Moderate
40m average time
70% success
0/80
Asked in companies
You are given an unsorted array/list 'ARR' of 'N' integers. Your task is to return the length of the longest consecutive sequence.
The consecutive sequence is in the form ['NUM', 'NUM' + 1, 'NUM' + 2, ..., 'NUM' + L] where 'NUM' is the starting integer of the sequence and 'L' + 1 is the length of the sequence.
Note:
If there are any duplicates in the given array we will count only one of them in the consecutive sequence.
For example-
For the given 'ARR' [9,5,4,9,10,10,6].
Output = 3
The longest consecutive sequence is [4,5,6].
Follow Up:
Can you solve this in O(N) time and O(N) space complexity?
2. Game Of Life
Moderate
15m average time
85% success
0/80
Asked in companies

You’re given a board of N * M size. Each element of this board is represented by either 0 or 1, where 0 means ‘dead’ and 1 means ‘live’. Each element can interact with all of its eight neighbors using the following four rules.
If any live cell has less than two live neighbors, then it dies.
If any live cell has two or three live neighbors, then it lives onto the next generation.
If any live cell has more than three live neighbors, then it dies.
A dead element with exactly three live neighbors becomes a live element.
Your task is to print the next state of this board using these four rules.
05
Round
Medium
Video Call
Duration70 minutes
Interview date29 Jan 2022
Coding problem4
2 Behavioral Questions + 1Technical
1. Puzzle Question
Tell me an instance where your manager told you “ Dont do this”.
2. LRU Cache Implementation
Moderate
25m average time
65% success
0/80
Asked in companies
Design and implement a data structure for Least Recently Used (LRU) cache to support the following operations:
1. get(key) - Return the value of the key if the key exists in the cache, otherwise return -1.
2. put(key, value), Insert the value in the cache if the key is not already present or update the value of the given key if the key is already present. When the cache reaches its capacity, it should invalidate the least recently used item before inserting the new item.
You will be given ‘Q’ queries. Each query will belong to one of these two types:
Type 0: for get(key) operation.
Type 1: for put(key, value) operation.
Note :
1. The cache is initialized with a capacity (the maximum number of unique keys it can hold at a time).
2. Access to an item or key is defined as a get or a put operation on the key. The least recently used key is the one with the oldest access time.
3. Puzzle Question
Tell me the time when you entered into an argument with the team
4. Puzzle Question
A story-based question was there like A plant is there. It will drop two seeds one on left and one on right. Any one or both of them can convert to grown-up plants. Then again they will drop seeds left and right.
Finally boils down to a full binary tree is there. Any node is either plant or empty space (NULL). At any level length of pipes required to water the plant is the distance between the left most node ( grown-up plant ) - the rightmost node (grown-up plant).
The main focus was on how will you store the full binary tree representation. if you make a tree. Let's say n (number of levels) is too high. Eg 1000. How much memory it will consume. Is it feasible for a much larger n?
Finally, I took the approach. I will store it in a file in a serialized tree manner.
https://leetcode.com/problems/serialize-and-deserialize-binary-tree/
They will traverse level by level and calculate the value required for each level.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 5 problems
Interviewed by Amazon

Rejected
3084 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
Rejected
2294 views
1 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by Amazon
Rejected
1592 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
 Selected
Selected 8962 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Samsung
Selected 12648 views
2 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Microsoft
Selected 5983 views
5 comments
0 upvotes