


























Amazon interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Amazon
3 rounds | 8 Coding
problems

Rejected
Interview preparation journey

Journey
I started my coding journey in Feb 2020. Firstly I solved approx 50-60 questions on the Hackkerank platform to brush up on my programming syntax and warmup. then I start coding on Leetcode and GFG platforms simultaneously. I picked each data structures topic and start solving questions for the same from easy to medium level. Firstly, I picked LinkedList data structures and coded approx 40 questions for the same and then I picked Hashing, Stack, Queue, and Trees. Graphs I solved very limited questions (only BFS, DFS, and topological sort-based questions). Dynamic programming I solved approx again 20-25 questions these are the generic ones only like LCS, Knapsack, etc. My approach for solving the question was to spend around 10-15 mins to first try building the solution. If I were not able to build the solution, then I used to refer to some post or youtube to understand the same. and after that, I keep this question on my to-do list then the next or next-to-next day, I used to code by myself the approach I watched on post/youtube.
Application story
I got this opportunity through campus placements. I prepare moderate data structures like linked lists, trees, graphs, arrays, hashing, stacks, and queues.
Why selected/rejected for the role?
Being a moderate level of coding and a deep understanding of programming skills. I was able to solve questions asked me during the selection process also good communication skill is more than required. But because of problem handling skills, I think, I got rejected for the same. Like the interviewer was looking for the STAR method to solve a problem.
Preparation
Duration: 6.5 months
Topics: Topics: Data Structures, OOPS, Trees, Graphs, LinkedList, Arrays, Queue, Stack, Hashmap, Searching, Sorting, Recursion, Strings
Tip 1 : Practice At least 20 questions from each topic like LinkedList, Graphs, Trees, and HashMap and all medium data structures.
Tip 2 : try to complete the medium code in 30 mins of durations.
Tip 3 : Prepare one coding language with which you are more comfortable.
Application process
Where: Company Website
Eligibility: No criteria
Tip 1 : Have some projects on your resume.
Tip 2 : Never put false things.

Interview rounds
01
Round
Medium
Online Coding Interview
Duration90 mins
Interview date8 May 2022
Coding problem5
this round contains 2 coding problems with 30 basic OS, DBMS, CN mcq questions.
1. Word Break
Moderate
15m average time
85% success

0/80
Asked in companies
You are given a list of “N” strings A. Your task is to check whether you can form a given target string using a combination of one or more strings of A.
Note :
You can use any string of A multiple times.
Examples :
A =[“coding”, ”ninjas”, “is”, “awesome”] target = “codingninjas”
Ans = true as we use “coding” and “ninjas” to form “codingninjas”
Problem approach
First I tried to use Hashmap for this. Then it did not work. So I used Trie data structure to solve this problem.
2. Clone Graph
Moderate
25m average time
75% success
0/80
Asked in companies
You are given a reference/address of a node in a connected undirected graph containing N nodes and M edges. You are supposed to return a clone of the given graph which is nothing but a deep copy. Each node in the graph contains an integer “data” and an array/list of its neighbours.
The structure of the graphNode class is as follows:
class graphNode
{
public:
int data;
vector<graphNode*> neighbours;
}
Note :
1. Nodes are numbered from 1 to N.
2. Your solution will run on multiple test cases. If you are using global variables make sure to clear them.
Problem approach
using the hashmap, we can keep track of nodes we have already created.
3. DBMS Question
Which of the following is a command of DDL?
1) Alter
2) Delete
3) Create
4) All of the Above
Problem approach
Tip 1:choose most appropriate ans.
4. OS MCQ
To avoid deadlock ____________
a) there must be a fixed number of resources to allocate
b) resource allocation must be done only once
c) all deadlocked processes must be aborted
d) inversion technique can be used
Problem approach
Tip 1: choose best ans to the question
5. Networking MCQ
Which of the following layers is an addition to the OSI model when compared with the TCP IP model?
a) Application layer
b) Presentation layer
c) Session layer
d) Session and Presentation layer
Problem approach
Tip 1: Do not take too much time for a single question.
02
Round
Medium
Online Coding Test
Duration60 mins
Interview date17 May 2022
Coding problem2
Interviewer was good.
1. Trie Implementation
Moderate
25m average time
65% success
0/80
Asked in companies

Implement a Trie Data Structure which supports the following three operations:
Operation 1 - insert(word) - To insert a string WORD in the Trie.
Operation 2- search(word) - To check if a string WORD is present in Trie or not.
Operation 3- startsWith(word) - To check if there is a string that has the prefix WORD.
Trie is a data structure that is like a tree data structure in its organisation. It consists of nodes that store letters or alphabets of words, which can be added, retrieved, and deleted from the trie in a very efficient way.
In other words, Trie is an information retrieval data structure, which can beat naive data structures like Hashmap, Tree, etc in the time complexities of its operations.
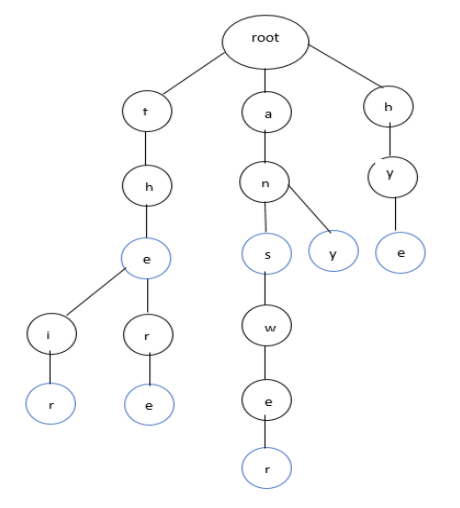
The above figure is the representation of a Trie. New words that are added are inserted as the children of the root node.
Alphabets are added in the top to bottom fashion in parent to children hierarchy. Alphabets that are highlighted with blue circles are the end nodes that mark the ending of a word in the Trie.
For Example:-
Type = ["insert", "search"], Query = ["coding", "coding].
We return ["null", "true"] as coding is present in the trie after 1st operation.
Problem approach
For solving this problem, you must have an understanding of Trie data structures.
2. Next Greater Element II
Moderate
35m average time
70% success
0/80
Asked in companies

You are given a circular array 'a' of length 'n'.
A circular array is an array in which we consider the first element is next of the last element. That is, the next element of 'a[n - 1]' is 'a[0]'.
Find the Next Greater Element(NGE) for every element.
The Next Greater Element for an element 'x' is the first element on the right side of 'x' in the array, which is greater than 'x'.
If no greater elements exist to the right of 'x', consider the next greater element as -1.
Example:
Input: 'a' = [1, 5, 3, 4, 2]
Output: NGE = [5, -1, 4, 5, 5]
Explanation: For the given array,
- The next greater element for 1 is 5.
- There is no greater element for 5 on the right side. So we consider NGE as -1.
- The next greater element for 3 is 4.
- The next greater element for 4 is 5, when we consider the next elements as 4 -> 2 -> 1 -> 5.
- The next greater element for 2 is 5, when we consider the next elements as 2 -> 1 -> 5.
Problem approach
this problem can be solved using stack data structures.
03
Round
Medium
Online Coding Test
Duration60 mins
Interview date25 May 2022
Coding problem1
Only 1 hard coding question was asked.
1. LFU Cache
Moderate
0/80
Asked in companies


Design and implement a Least Frequently Used(LFU) Cache, to implement the following functions:
1. put(U__ID, value): Insert the value in the cache if the key(‘U__ID’) is not already present or update the value of the given key if the key is already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting the new item.
2. get(U__ID): Return the value of the key(‘U__ID’), present in the cache, if it’s present otherwise return -1.
Note:
1) The frequency of use of an element is calculated by a number of operations with its ‘U_ID’ performed after it is inserted in the cache.
2) If multiple elements have the least frequency then we remove the element which was least recently used.
You have been given ‘M’ operations which you need to perform in the cache. Your task is to implement all the functions of the LFU cache.
Type 1: for put(key, value) operation.
Type 2: for get(key) operation.
Example:
We perform the following operations on an empty cache which has capacity 2:
When operation 1 2 3 is performed, the element with 'U_ID' 2 and value 3 is inserted in the cache.
When operation 1 2 1 is performed, the element with 'U_ID' 2’s value is updated to 1.
When operation 2 2 is performed then the value of 'U_ID' 2 is returned i.e. 1.
When operation 2 1 is performed then the value of 'U_ID' 1 is to be returned but it is not present in cache therefore -1 is returned.
When operation 1 1 5 is performed, the element with 'U_ID' 1 and value 5 is inserted in the cache.
When operation 1 6 4 is performed, the cache is full so we need to delete an element. First, we check the number of times each element is used. Element with 'U_ID' 2 is used 3 times (2 times operation of type 1 and 1-time operation of type 1). Element with 'U_ID' 1 is used 1 time (1-time operation of type 1). So element with 'U_ID' 1 is deleted. The element with 'U_ID' 6 and value 4 is inserted in the cache.
Problem approach
this problem can be solved using 2 hashmaps.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 5 problems
Interviewed by Amazon
Rejected
3084 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
Rejected
2294 views
1 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by Amazon
Rejected
1593 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
 Selected
Selected 8962 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58238 views
5 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Samsung
Selected 12649 views
2 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Microsoft
Selected 5983 views
5 comments
0 upvotes